吉客云数据集成到轻易云:查询商品信息方案分享
在本文中,我们将详细解析如何利用轻易云数据集成平台,将吉客云的商品信息通过API接口erp.storage.goodslist对接至轻易云。这一技术案例重点展示了高吞吐量的数据写入能力、实时监控与告警系统、以及自定义数据转换逻辑等关键特性。
首先,针对大量来源于吉客云的商品数据信息,高效且可靠地进行抓取和处理是核心难点。为了应对大规模的数据请求并确保不漏单,我们使用定时调度器周期性调用吉客云API,实现了批量获取商品列表并导入到轻易云平台。通过合理配置分页参数与限流策略,按需分配资源,以防止服务器超载,提高任务执行效率。
其次,为解决跨平台的数据格式差异问题,本方案借助了轻易云提供的可视化数据流设计工具及自定义映射功能。在实际操作中,通过配置灵活的数据转换规则,将吉客云返回的数据字段准确无误地匹配到目标系统所需字段,从而确保数据一致性。
最后,在实际运行过程中,对接异常处理与错误重试机制也尤为重要。我们通过设置监控和告警规则,实时追踪各项任务状态,并记录日志用于分析问题原因。同时,异常发生时自动触发重试机制,有效保证了整个流程的稳定运行,不影响业务连续性。
以上即是此次“查询商品信息”方案实施中的核心要点,下文将深入探讨具体实现步骤及技术细节。
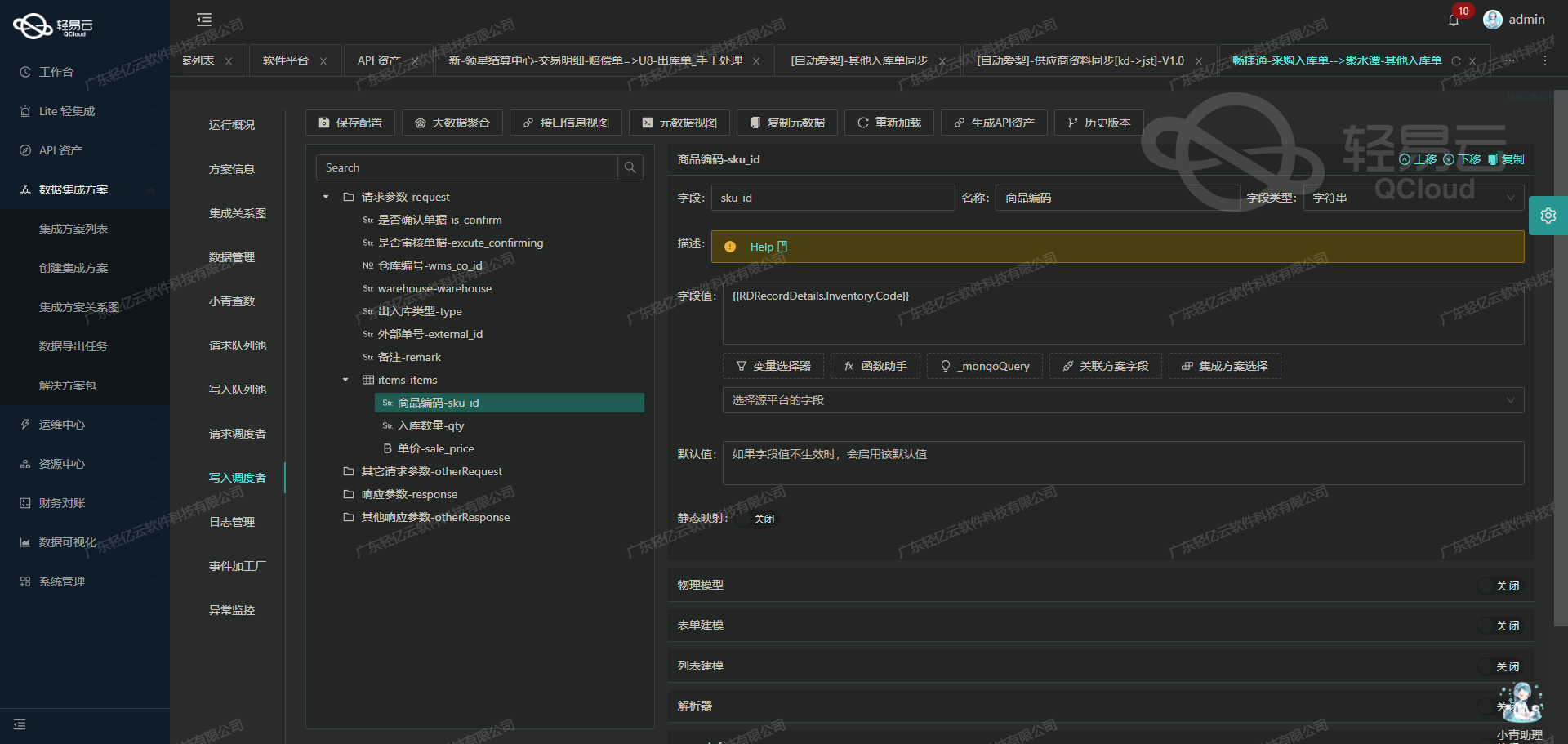
使用轻易云数据集成平台调用吉客云接口获取商品信息
在数据集成过程中,调用源系统的API接口是至关重要的一步。本文将详细探讨如何使用轻易云数据集成平台调用吉客云的erp.storage.goodslist接口来获取并加工商品信息。
接口概述
吉客云的erp.storage.goodslist接口用于查询商品信息,支持POST请求。该接口返回的商品信息包括SKU名称、SKU ID、是否组合装、货品是否停用等多个字段。通过配置元数据,可以灵活地指定查询条件和分页参数。
元数据配置详解
元数据配置是调用API接口的关键部分,以下是对提供的元数据配置的详细解析:
{
"api": "erp.storage.goodslist",
"effect": "QUERY",
"method": "POST",
"number": "skuName",
"id": "skuId",
"request": [
{"field": "pageIndex", "label": "页码", "type": "string"},
{"field": "pageSize", "label": "页码大小", "type": "string", "value": "200"},
{"field": "skuName", "label": "规格名称", "type": "string"},
{"field": "isPackageGood", "label": "是否组合装", "type": "string"},
{"field": "isBlockup", "label": "货品是否停用", "type": "string"},
{"field": "skuIsBlockup", "label": "规格是否停用", "type": "string"},
{"field": "startDateModifiedSku",
"label":"起始时间(规格修改时间)",
"type":"string",
"value":"{{LAST_SYNC_TIME|datetime}}"
},
{"field":"endDateModifiedSku",
"label":"终止时间(规格修改时间)",
"type":"string",
"value":"{{CURRENT_TIME|datetime}}"
}
],
“autoFillResponse”: true
}- API:
erp.storage.goodslist,指定了要调用的吉客云接口。 - effect:
QUERY,表示这是一个查询操作。 - method:
POST,指定了HTTP请求方法为POST。 - number 和 id: 分别对应SKU名称和SKU ID,这两个字段在后续的数据处理和映射中非常重要。
- request: 包含了多个请求参数,如页码(pageIndex)、页码大小(pageSize)、规格名称(skuName)等。这些参数可以根据实际需求进行调整。
特别需要注意的是:
startDateModifiedSku和endDateModifiedSku参数使用了动态变量{{LAST_SYNC_TIME|datetime}}和{{CURRENT_TIME|datetime}},确保每次调用时都能获取到最新的数据。
数据请求与清洗
在轻易云平台上配置好元数据后,可以开始进行数据请求与清洗。以下是具体步骤:
- 发送请求:根据配置好的元数据,通过POST方法向吉客云发送请求。请求体中包含分页参数和其他过滤条件。
- 接收响应:吉客云返回包含商品信息的JSON响应。
- 数据清洗:对返回的数据进行初步清洗,包括去除无效字段、格式转换等操作。例如,将日期字符串转换为标准日期格式,将布尔值转换为系统可识别的标识符等。
数据转换与写入
完成数据清洗后,需要将处理后的数据转换为目标系统所需的格式,并写入目标数据库或系统。这一步通常包括以下操作:
- 字段映射:将吉客云返回的数据字段映射到目标系统的数据结构。例如,将SKU名称映射到目标系统中的商品名称字段。
- 格式转换:根据目标系统要求,对数据格式进行进一步转换。例如,将字符串类型的日期转换为日期对象。
- 写入操作:通过轻易云平台提供的数据写入功能,将处理后的数据批量写入目标数据库或系统。
实践案例
假设我们需要获取所有未停用且最近一个月内修改过的商品信息,可以按如下方式配置并调用API:
{
“api”: “erp.storage.goodslist”,
“method”: “POST”,
“request”: {
“pageIndex”: “1”,
“pageSize”: “200”,
“isBlockup”: “false”,
“startDateModifiedSku”: “2023-09-01T00:00:00Z”,
“endDateModifiedSku”: “2023-10-01T00:00:00Z”
}
}通过上述配置,我们可以获取到符合条件的商品列表,并进一步处理这些数据以满足业务需求。
总结来说,通过合理配置元数据并利用轻易云平台强大的集成功能,可以高效地实现跨系统的数据集成和处理,为企业业务提供可靠的数据支持。
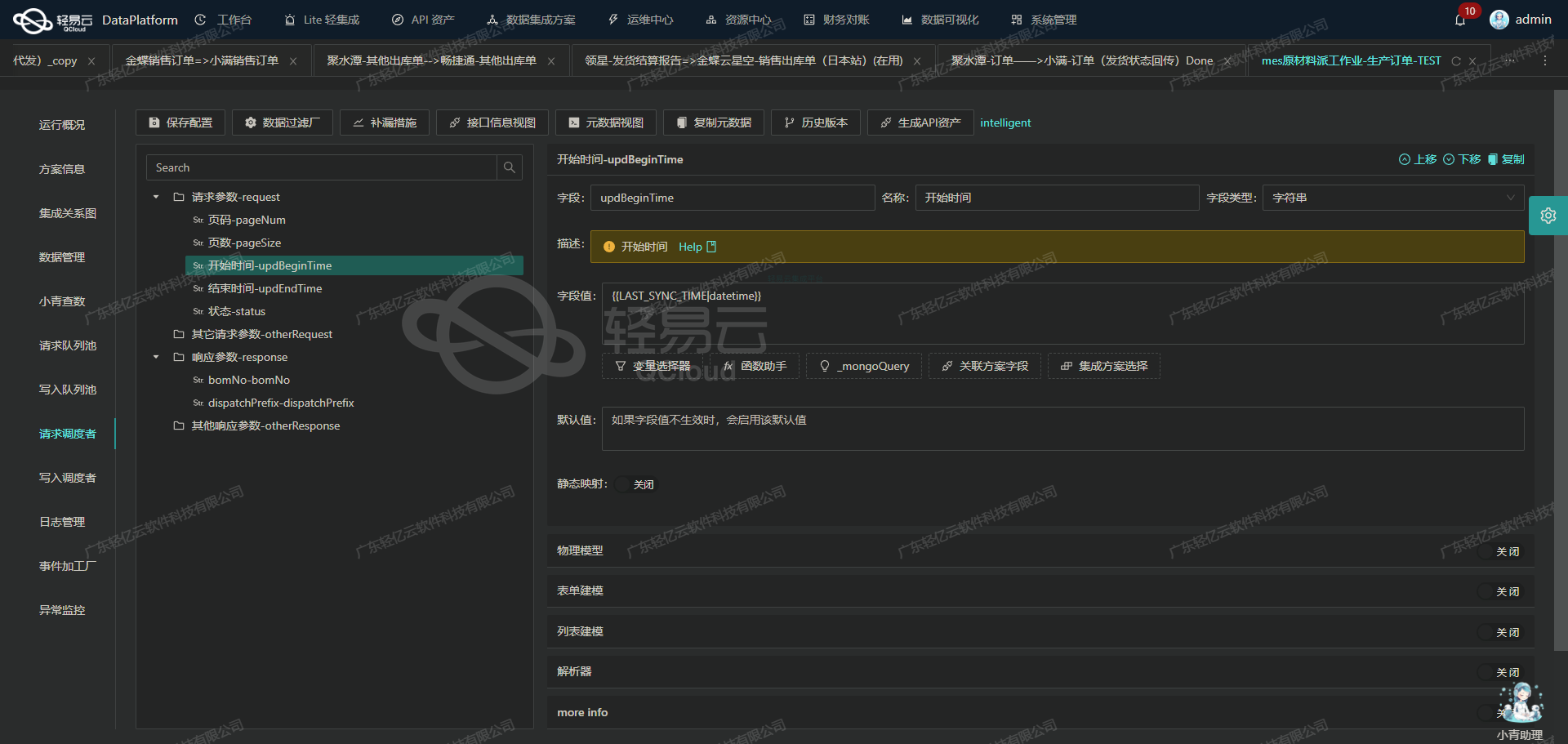
使用轻易云数据集成平台进行ETL转换并写入目标平台的技术案例
在数据集成过程中,ETL(提取、转换、加载)是至关重要的一步。本文将深入探讨如何使用轻易云数据集成平台将已经集成的源平台数据进行ETL转换,并最终通过API接口写入目标平台。
数据请求与清洗
在进行ETL转换之前,我们首先需要从源平台获取原始数据,并对其进行清洗。假设我们需要查询商品信息,首先通过API接口从源平台提取商品数据:
{
"api": "查询商品信息",
"method": "GET",
"params": {
"category": "electronics",
"availability": "in_stock"
}
}在获取到原始数据后,接下来是对这些数据进行清洗和预处理。这一步骤通常包括去除无效字段、格式化日期、标准化数值等操作。例如:
def clean_data(raw_data):
cleaned_data = []
for item in raw_data:
if item['price'] > 0: # 去除价格为零的商品
cleaned_item = {
'id': item['id'],
'name': item['name'].strip(),
'price': float(item['price']),
'availability': item['availability']
}
cleaned_data.append(cleaned_item)
return cleaned_data数据转换与写入
完成数据清洗后,下一步是将清洗后的数据转换为目标平台所能接受的格式。根据提供的元数据配置,我们需要将数据转为轻易云集成平台API接口所能够接收的格式。
元数据配置如下:
{
"api": "写入空操作",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true
}根据该配置,我们可以确定以下几点:
- API接口为
写入空操作。 - 请求方法为
POST。 - 在执行写入操作前需要进行ID检查。
下面是一个示例代码片段,展示如何将清洗后的数据转换并通过API接口写入目标平台:
import requests
def transform_and_write(cleaned_data):
url = "https://api.qingyiyun.com/write_empty_operation"
headers = {"Content-Type": "application/json"}
for item in cleaned_data:
payload = {
"id": item["id"],
"name": item["name"],
"price": item["price"],
"availability": item["availability"]
}
# ID检查逻辑
if check_id_exists(item["id"]):
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(f"Item {item['id']} written successfully.")
else:
print(f"Failed to write item {item['id']}. Status code: {response.status_code}")
else:
print(f"Item {item['id']} does not exist.")
def check_id_exists(item_id):
# 假设有一个函数可以检查ID是否存在于目标平台
# 返回True表示存在,False表示不存在
return True
# 假设我们已经有了清洗后的数据cleaned_data
cleaned_data = clean_data(raw_data)
transform_and_write(cleaned_data)在上述代码中,我们首先定义了一个函数transform_and_write,用于将清洗后的数据转换并通过POST请求写入目标平台。在发送请求之前,通过调用check_id_exists函数进行ID检查,以确保ID存在。
实时监控与调试
在实际操作中,实时监控和调试也是不可或缺的一部分。轻易云数据集成平台提供了全透明可视化的操作界面,可以实时监控每个环节的数据流动和处理状态。如果出现问题,可以通过日志和监控工具快速定位并解决问题。
例如,在Python代码中可以添加日志记录,以便在出现错误时能够快速诊断:
import logging
logging.basicConfig(level=logging.INFO)
def transform_and_write(cleaned_data):
url = "https://api.qingyiyun.com/write_empty_operation"
headers = {"Content-Type": "application/json"}
for item in cleaned_data:
payload = {
"id": item["id"],
"name": item["name"],
"price": item["price"],
"availability": item["availability"]
}
if check_id_exists(item["id"]):
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
logging.info(f"Item {item['id']} written successfully.")
else:
logging.error(f"Failed to write item {item['id']}. Status code: {response.status_code}")
else:
logging.warning(f"Item {item['id']} does not exist.")通过这种方式,可以更好地跟踪和管理整个ETL过程,提高系统的稳定性和可靠性。