案例分享:马帮付款单列表集成到MySQL
在进行数据系统对接时,如何保障数据的完整性和实时更新是一项关键挑战。本案例将详细介绍如何通过fin-search-paymentorder API高效获取马帮系统中的付款单列表,并通过batchexecute API快速写入到MySQL数据库中。在具体操作过程中,不仅需要处理接口分页和限流问题,还要确保数据转换和映射的严密性,以适应不同的数据结构需求。
1. 数据抓取与分页处理
使用马帮API获取大批量付款单数据时,需要考虑到API接口的限流策略以及分页机制。为了避免遗漏任何一条记录,我们采用定时任务可靠地抓取多页支付订单,并对每次调用进行状态监控。一方面保证了所有页面都能成功访问;另一方面,通过分布式任务调度体系,有效减少了服务器负载,实现高吞吐量的数据顺利传输。
2. 数据格式转换与映射
马帮系统返回的数据格式通常带有一定的业务特性,而这些特性并不总是直接符合MySQL表结构要求。因此,在向MySQL插入数据之前,我们需要根据企业自身需求实现自定义的数据转换逻辑。复杂字段如JSON对象、嵌套数组等,需要应用精细化解析与重新映射,再用batchexecute API执行大批量插入操作。这不仅提高了写入效率,也确保了数据存储的一致性与完整性。
3. 实时监控与异常处理
整个数据集成过程必须具备完备的监控和告警功能,以及时发现并解决潜在问题。通过集中的日志管理和异常检测机制,每个步骤都会被详细记录。如果出现网络波动或者接口超时,可以自动触发重试机制,进一步提升任务执行的可靠性。此外,结合轻易云平台提供可视化操作界面,使得开发人员能够更加直观地查看各环节运行情况,从而迅速响应突发事件,保障业务连续稳定运行。
这个案例展示了如何利用轻易云平台强大的工具链,将复杂的数据处理工作变得透明且可追踪,为企业优化资源配置,提高工作效率提供坚实支撑。以下章节将深入讲解具体实施方案及技术细节,包括API调用代码示例、分页策略设计、自定义转换规则等内容。
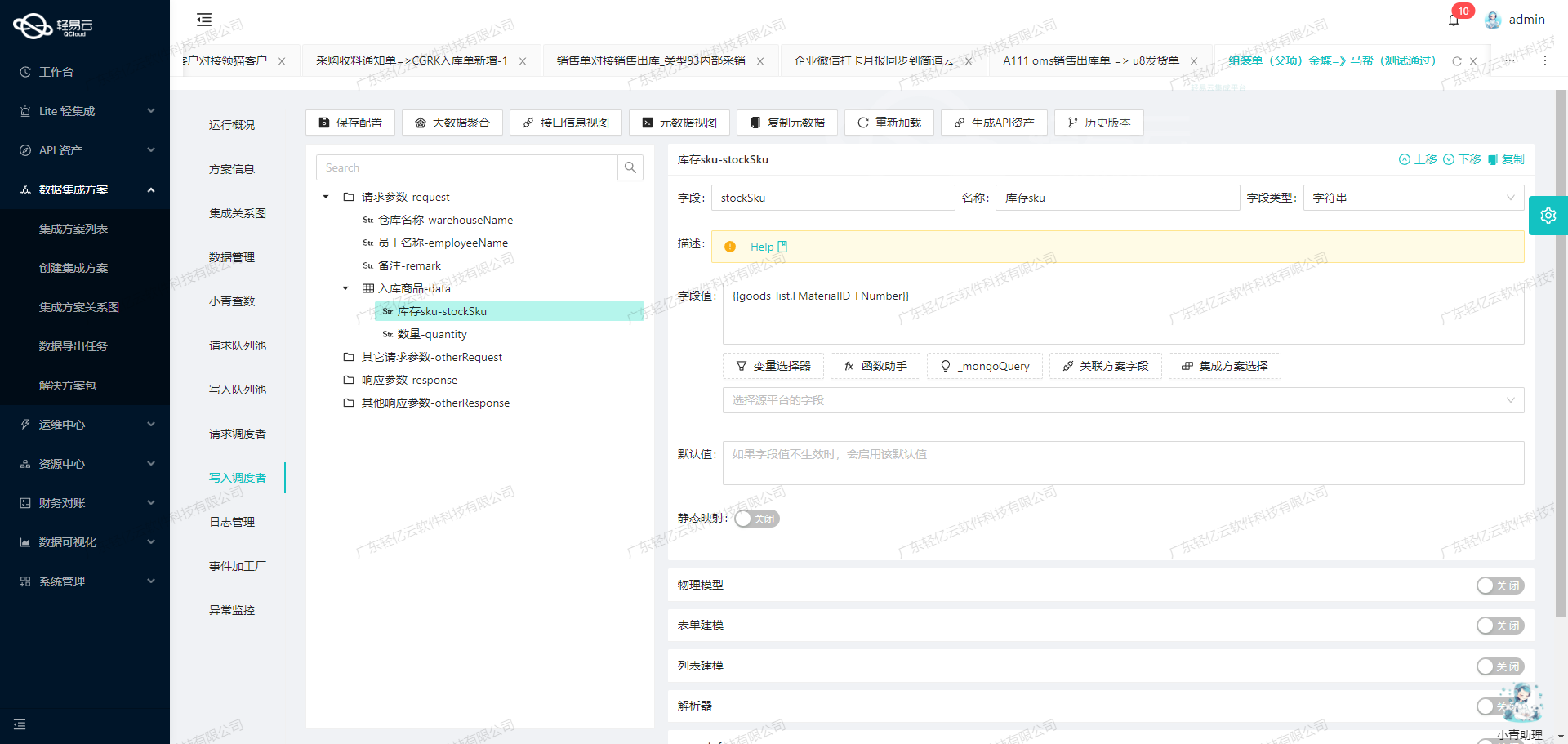
调用马帮接口fin-search-paymentorder获取并加工数据
在轻易云数据集成平台的生命周期中,调用源系统接口是至关重要的一步。本文将深入探讨如何通过调用马帮接口fin-search-paymentorder来获取付款单列表,并对数据进行初步加工处理。
接口配置与请求参数
首先,我们需要配置元数据以便正确调用马帮的API接口。根据提供的元数据配置,我们可以看到以下关键字段:
api:fin-search-paymentordereffect:QUERYmethod:POST- 请求参数:
maxRows: 分页查询数,设置为500。ordertype: 单据类型,设置为2。timeCreatedStart: 创建开始时间,使用上次同步时间{{LAST_SYNC_TIME|datetime}}。timeCreatedEnd: 创建结束时间,使用当前时间{{CURRENT_TIME|datetime}}。
这些参数确保我们能够高效地分页获取所需的数据,并且仅限于特定时间范围内的新创建的付款单。
请求示例
构建请求时,我们需要确保请求体包含所有必要的参数。以下是一个请求示例:
{
"maxRows": "500",
"ordertype": "2",
"timeCreatedStart": "{{LAST_SYNC_TIME|datetime}}",
"timeCreatedEnd": "{{CURRENT_TIME|datetime}}"
}在实际操作中,这些动态参数会被平台自动替换为相应的时间戳。
数据清洗与转换
在获取到原始数据后,我们需要对其进行清洗和转换,以便后续写入到目标系统(如MySQL数据库)。以下是几个关键步骤:
-
字段映射:根据元数据配置,我们需要将API返回的数据字段映射到目标数据库的字段。例如:
- API返回的
orderNum映射到数据库中的订单编号。 - API返回的
id映射到数据库中的唯一标识符。 - API返回的
shipmentId映射到数据库中的发货单号。
- API返回的
-
数据格式转换:确保日期、金额等字段符合目标系统的格式要求。例如,将日期字符串转换为标准的日期格式,将金额字符串转换为数值类型。
-
去重与过滤:在某些情况下,API可能会返回重复的数据或不符合条件的数据。我们需要通过去重和过滤操作来保证数据质量。
数据写入
经过清洗和转换后的数据,可以通过轻易云平台提供的数据写入功能,将其批量插入到MySQL数据库中。这一步通常包括以下操作:
- 建立数据库连接:配置MySQL数据库连接信息,包括主机、端口、用户名和密码等。
- 批量插入:使用批量插入语句,将处理后的数据一次性写入数据库,提高效率。
以下是一个简单的批量插入示例:
INSERT INTO payment_orders (order_num, id, shipment_id, created_time)
VALUES (?, ?, ?, ?)通过预编译语句和参数化查询,可以有效防止SQL注入攻击,并提高执行效率。
实时监控与日志记录
为了确保整个过程的透明度和可追溯性,轻易云平台提供了实时监控和日志记录功能。我们可以实时查看每个步骤的数据流动情况,并记录所有操作日志,以便后续审计和问题排查。
总之,通过合理配置元数据并利用轻易云平台强大的集成功能,我们可以高效地从马帮系统获取付款单列表,并将其无缝集成到目标MySQL数据库中。这不仅提升了业务流程的自动化程度,也极大地提高了数据处理效率和准确性。

数据集成生命周期中的ETL转换:将马帮付款单列表写入MySQL
在数据集成生命周期的第二步,数据转换与写入是关键环节。本文将深入探讨如何使用轻易云数据集成平台,将已经集成的源平台数据进行ETL转换,并转为目标平台MySQL API接口所能接收的格式,最终写入目标平台。
元数据配置解析
首先,我们需要理解元数据配置,以便准确地进行ETL转换。以下是我们要处理的元数据配置:
{
"api": "batchexecute",
"effect": "EXECUTE",
"method": "SQL",
"number": "id",
"id": "id",
"name": "id",
"idCheck": true,
"request": [
{"field": "id", "label": "id", "type": "string", "value": "{id}"},
{"field": "amount", "label": "amount", "type": "string", "value": "{amount}"},
{"field": "associateNum", "label": "associateNum", "type": "string", "value": "{associateNum}"},
{"field": "ordertype", "label": "ordertype", "type": "string", "value": "{ordertype}"},
{"field": "comment", "label": "comment", "type": "string", "value": "{comment}"},
{"field": "completeTime", "label": "completeTime", "type": string, value: "{completeTime}"},
{"field":"checkTime","label":"checkTime","type":"string","value":"{checkTime}"},
{"field":"createTime","label":"createTime","type":"string","value":"{createTime}"},
{"field":"paymentType","label":"paymentType","type":"string","value":"{paymentType}"},
{"field":"orderNum","label":"orderNum","type":"string","value":"{orderNum}"},
{"field":"prepayTime","label":"prepayTime","type":"string","value":"{prepayTime}"},
{"field":"status","label":"status","type":"string","value":"{status}"},
{"field":"totalAmount","label":"totalAmount","type":"string","value":"{totalAmount}"},
{"field":"account","label":"account","type":"string","value":"{account}"},
{"field:"createrId,"label:"createrId,"type:"string,"value:"{createrId}"},
{"field:"checkOperId,"label:"checkOperId,"type:"string,"value:"{checkOperId}"},
{"field:"completerId,"label:"completerId,"type:"string,"value:"{completerId}"},
{"field:"paymentMethod,"label:"paymentMethod,"type:"string,"value:"{paymentMethod}"}
],
otherRequest: [
{
field: main_sql,
label: 主语句,
type: string,
describe: SQL首次执行的语句,将会返回:lastInsertId,
value: REPLACE INTO paymentorder (id,amount,associateNum,ordertype,comment,completeTime,checkTime,createTime,paymentType,orderNum,prepayTime,status,totalAmount,account,createrId,checkOperId,completerId,paymentMethod) VALUES
},
{
field: limit,
label: limit,
type: string,
value: 1000
}
]
}数据请求与清洗
在这一阶段,我们已经从源平台(如马帮)获取了付款单列表,并进行了必要的数据清洗和预处理。接下来,我们需要将这些清洗后的数据转换为目标平台(MySQL)所能接受的格式。
数据转换与写入
-
定义SQL语句模板: 我们需要定义一个SQL语句模板,用于将每条记录插入到MySQL数据库中。根据元数据配置中的
main_sql字段,我们可以看到这是一个REPLACE INTO语句:REPLACE INTO paymentorder (id, amount, associateNum, ordertype, comment, completeTime, checkTime, createTime, paymentType, orderNum, prepayTime, status, totalAmount, account, createrId, checkOperId, completerId,paymentMethod) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?) -
参数映射: 根据元数据配置中的
request字段,我们需要将每个字段映射到相应的SQL参数中。例如:id->{id}amount->{amount}associateNum->{associateNum}- ...
-
构建批量执行请求: 我们使用API
batchexecute来批量执行这些SQL语句。每次请求可以包含多条记录,具体数量由limit字段决定,这里设置为1000。 -
示例代码: 以下是一个简化的示例代码片段,展示如何构建和执行批量插入请求:
import requests import json # 定义API URL和头部信息 api_url = 'http://your-mysql-api-endpoint/batchexecute' headers = {'Content-Type': 'application/json'} # 构建请求体 data = { 'main_sql': 'REPLACE INTO paymentorder (id, amount,... ) VALUES', 'records': [ { 'id': record['id'], 'amount': record['amount'], ... } for record in cleaned_data_list ], 'limit': 1000 } # 执行请求 response = requests.post(api_url, headers=headers, data=json.dumps(data)) if response.status_code == 200: print('Data inserted successfully') else: print('Failed to insert data:', response.text)
实践中的注意事项
- 数据类型匹配:确保源数据类型与目标数据库字段类型匹配,避免因类型不匹配导致的数据插入失败。
- 错误处理:在实际操作中,需要加入错误处理机制,如重试策略、日志记录等,以应对网络波动或其他异常情况。
- 性能优化:对于大规模数据插入,可以考虑分批次处理,并利用数据库的批量插入特性提升性能。
通过以上步骤,我们可以高效地将清洗后的源平台数据转换并写入到目标平台MySQL中,实现不同系统间的数据无缝对接。