金蝶云星空数据集成到轻易云数据集成平台的技术案例分享
在企业信息系统日益复杂化的背景下,实现不同业务系统之间的数据无缝对接,成为提高运营效率和决策准确性的关键所在。本篇文章将深入解析如何通过轻易云集成平台,将金蝶云星空中的生产用料清单数据高效、安全地迁移和处理,以适应深圳天一-好-物料为空这个特定业务场景。
首先介绍一个具体的操作实例:使用executeBillQuery API从金蝶云星空系统中获取生产用料清单数据,并利用轻易云提供的写入API完成对接。在这个过程中,我们将特别关注以下几个关键技术点:
-
高吞吐量的数据写入能力: 由于生产用料清单涉及大量的数据记录,保证这些数据能够迅速、无遗漏地写入至目标系统是首要任务。我们采用并行处理机制以及批次提交策略,有效提升了数据的传输效率。
-
集中监控与告警系统: 数据对接过程中,引入实时监控和告警功能来跟踪每个步骤的执行状态。一旦发现异常,如超时或接口返回错误码,可以立即触发报警,并启动自动重试及人工干预流程,从而确保整个过程不中断。
-
自定义数据转换逻辑: 金蝶与轻易两大平台在接口规范、字段映射等方面存在差异。通过灵活配置自定义转换规则,我们实现了源(SRC)到目标(TARGET)的平滑过渡,包括字段重命名、值映射以及格式调整等,保障了最终数据库结构的一致性和完整性。
-
分页与限流问题解决方案: 金蝶云星空
executeBillQuery接口具备分页查询特性,通过合理设置分页参数,可以避免因一次性请求过多导致服务器压力过大的情况。同时配合限流管理,在保持高效抓取速度的同时也有效防止了服务拒绝风险。
这一系列措施不仅确保了金蝶 云星空中的重要业务数据能够及时且可靠地同步至轻易云,同时极大程度上简化了运维人员工作,提高整体作业质量。随后的章节中,将详细介绍具体实施步骤及代码样例,以便读者更直观地理解各个环节中的技术细节。
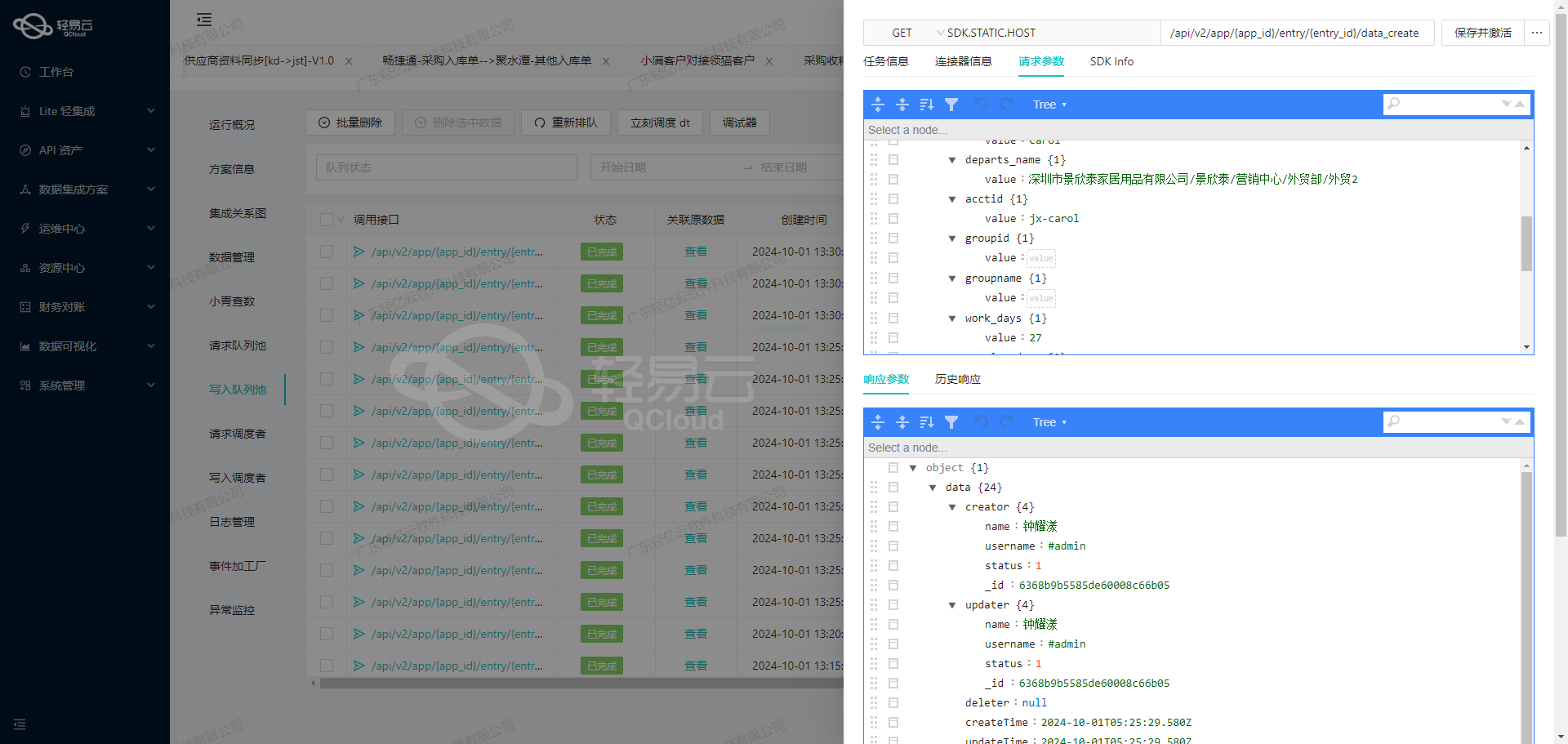
调用金蝶云星空接口executeBillQuery获取并加工数据
在数据集成的生命周期中,调用源系统接口是关键的第一步。本文将深入探讨如何通过轻易云数据集成平台调用金蝶云星空接口executeBillQuery,获取并加工生产用料清单数据。
API接口配置
首先,我们需要配置API接口的元数据。根据提供的元数据配置,我们可以看到该接口采用POST方法进行请求,主要用于查询操作(effect: QUERY)。以下是主要的请求字段及其描述:
FEntity_FEntryID: 实体分录IDFMoEntrySeq: 生产订单号FID: 实体主键FBillNo: 单据编号FInventoryDate: 库存日期FPrdOrgId.FNumber: 生产组织编号FSupplyOrg.FNumber: 发料组织编号FWorkshopID.FNumber: 生产车间编号FMoBillNo: 生产订单编号FMaterialId.FNumber: 产品编码FMaterialName: 产品名称FMoId: 生产订单内码FQty: 数量FMOEntryID: 生产订单分录内码FMaterialID2.FNumber: 子项物料编码FMaterialName1: 子项物料名称FMaterialType: 子项类型FDosageType: 用量类型FMustQty: 应发数量FPickedQty: 已领数量FRePickedQty: 补领数量FOverControlMode: 超发控制类型
此外,还有一些其他请求参数用于分页和过滤,例如Limit、StartRow、TopRowCount、FilterString和FieldKeys。
请求示例
为了更好地理解如何调用该接口,我们可以构建一个具体的请求示例。假设我们需要查询最近20分钟内修改的数据,并且只查询特定生产组织的数据,可以设置如下过滤条件:
{
"FormId": "PRD_PPBOM",
"FieldKeys": [
"FID", "FBillNo", "FInventoryDate", "FPrdOrgId.FNumber",
"FSupplyOrg.FNumber", "FWorkshopID.FNumber", "FMoBillNo",
"FMaterialId.FNumber", "FMaterialName", "FMustQty"
],
"FilterString": "FModifyDate>='{{MINUTE_AGO_20|datetime}}' and FPrdOrgId.FNumber in ('T01.06','T04') and left(FMoBillNo,2)='HJ'",
"Limit": "{PAGINATION_PAGE_SIZE}",
"StartRow": "{PAGINATION_START_ROW}"
}数据清洗与转换
在获取到原始数据后,需要对其进行清洗和转换,以便后续处理。轻易云平台提供了丰富的数据处理工具,可以自动化执行这些任务。例如,可以使用批量保存方法(batchArraySave)将处理后的数据保存到目标系统中。
以下是一个简单的数据清洗示例:
def clean_data(raw_data):
cleaned_data = []
for record in raw_data:
cleaned_record = {
'单据编号': record['FBillNo'],
'库存日期': record['FInventoryDate'],
'生产组织': record['FPrdOrgId.FNumber'],
'发料组织': record['FSupplyOrg.FNumber'],
'生产车间': record['FWorkshopID.FNumber'],
'生产订单编号': record['FMoBillNo'],
'产品编码': record['FMaterialId.FNumber'],
'产品名称': record['FMaterialName'],
'应发数量': record['FMustQty']
}
cleaned_data.append(cleaned_record)
return cleaned_data
# 假设 raw_data 是从金蝶云星空接口获取的原始数据列表
cleaned_data = clean_data(raw_data)自动化与监控
为了确保数据集成过程的稳定性和连续性,可以设置自动化任务和监控机制。例如,通过定时任务(crontab)每5分钟执行一次查询,并接管上次同步时间后的增量数据:
{
"crontab": "*\/5 * * * *",
"takeOverRequest": [
{
"field": "FilterString",
"value": "FModifyDate>='{{MINUTE_AGO_20|datetime}}' and FPrdOrgId.FNumber in ('T01.06','T04') and left(FMoBillNo,2)='HJ'",
"type": "string"
}
]
}通过以上配置,可以实现对金蝶云星空系统中生产用料清单数据的高效获取、清洗和转换,为后续的数据处理打下坚实基础。
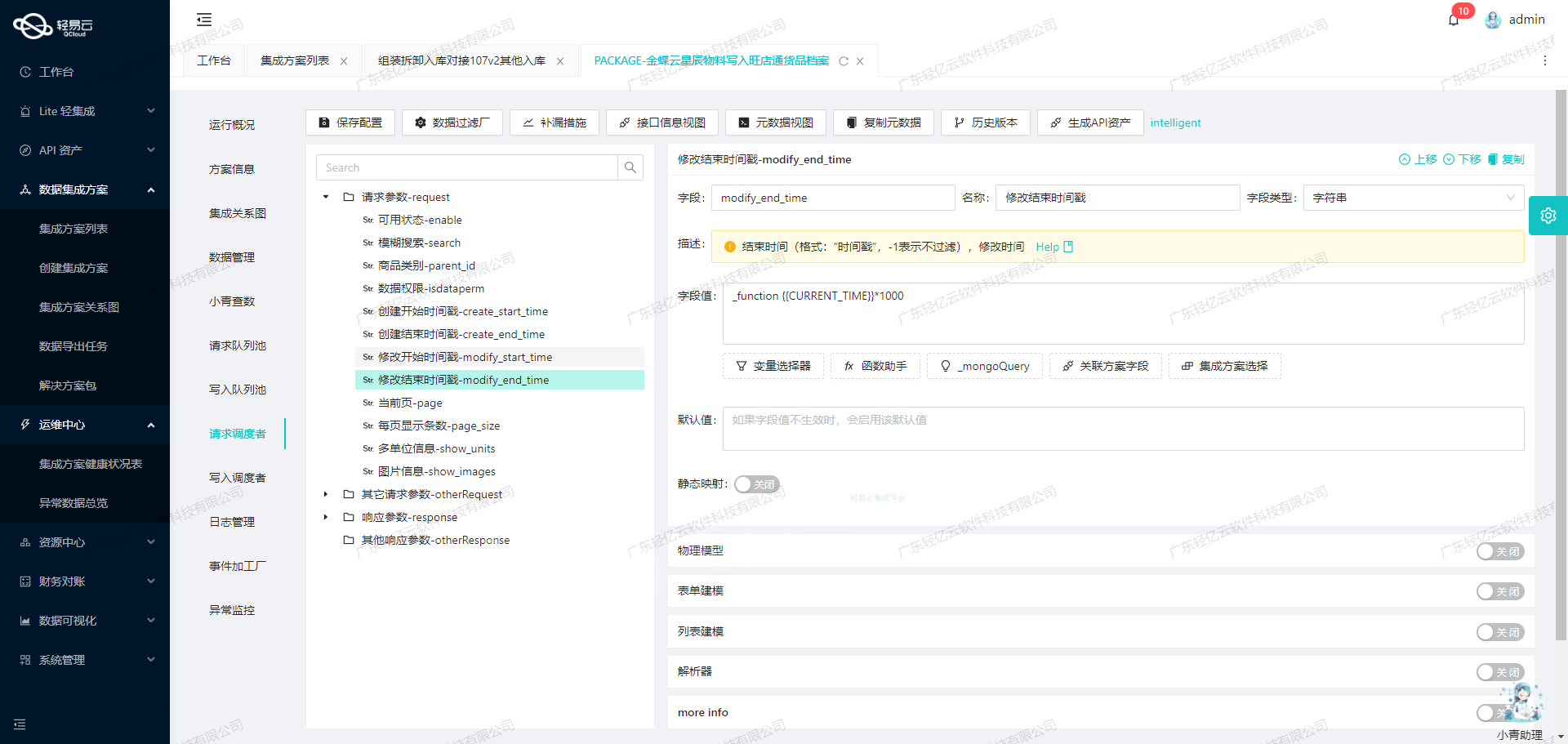
使用轻易云数据集成平台进行ETL转换和数据写入
在数据集成过程中,ETL(提取、转换、加载)是一个关键步骤。本文将详细探讨如何利用轻易云数据集成平台,将源平台的数据进行ETL转换,并通过API接口将其写入目标平台。
数据提取与清洗
首先,我们从源平台提取所需的数据。在本案例中,我们需要查询金蝶生产用料清单。假设我们已经通过轻易云数据集成平台完成了数据请求和清洗步骤,接下来我们重点关注如何将这些清洗后的数据进行转换并写入目标平台。
数据转换
为了确保数据能够被目标平台的API接口接收,我们需要对数据进行适当的格式转换。以下是一个典型的元数据配置:
{
"api": "写入空操作",
"effect": "EXECUTE",
"method": "POST",
"number": "number",
"id": "id",
"name": "编码",
"idCheck": true
}根据上述配置,我们需要确保以下几点:
- API接口:目标API为“写入空操作”,这是我们将调用的具体接口。
- HTTP方法:使用POST方法进行数据提交。
- 字段映射:源数据中的
number、id和编码字段分别映射到目标API的对应字段。 - ID检查:
idCheck设置为true,表示在写入前需要检查ID的唯一性。
数据写入
在完成数据转换后,我们需要通过API接口将其写入目标平台。以下是一个示例代码片段,展示如何使用Python实现这一过程:
import requests
import json
# 源数据示例
source_data = [
{"number": 123, "id": 1, "编码": "A001"},
{"number": 456, "id": 2, "编码": "A002"}
]
# API配置信息
api_url = 'https://example.com/api/写入空操作'
headers = {'Content-Type': 'application/json'}
# 遍历源数据并进行处理
for item in source_data:
payload = {
'number': item['number'],
'id': item['id'],
'name': item['编码']
}
# 检查ID唯一性(假设有一个函数check_id_unique来执行此操作)
if check_id_unique(item['id']):
response = requests.post(api_url, headers=headers, data=json.dumps(payload))
if response.status_code == 200:
print(f"Data for ID {item['id']} successfully written.")
else:
print(f"Failed to write data for ID {item['id']}. Status code: {response.status_code}")
else:
print(f"Duplicate ID found: {item['id']}")
def check_id_unique(id):
# 假设这是一个检查ID唯一性的函数,返回True或False
# 实际实现可能涉及数据库查询或其他逻辑
return True在这个示例中,我们首先定义了源数据,然后根据元数据配置构建了请求负载,并通过POST请求将其发送到目标API。如果ID检查通过,则执行写入操作,并根据响应状态码判断操作是否成功。
关键技术点总结
- 字段映射:确保源数据与目标API字段一一对应,这是成功写入的基础。
- ID唯一性检查:在执行写入操作前,必须确保每个记录的ID是唯一的,以避免重复和冲突。
- 错误处理:对每个API请求的响应进行检查,及时捕捉并处理错误,以保证整个流程的稳定性。
通过以上步骤,我们可以高效地完成从源平台到目标平台的数据ETL转换和写入过程。这不仅提高了业务流程的透明度和效率,也确保了数据的一致性和完整性。