星辰-查询仓库信息:金蝶云星辰V2数据集成案例分享
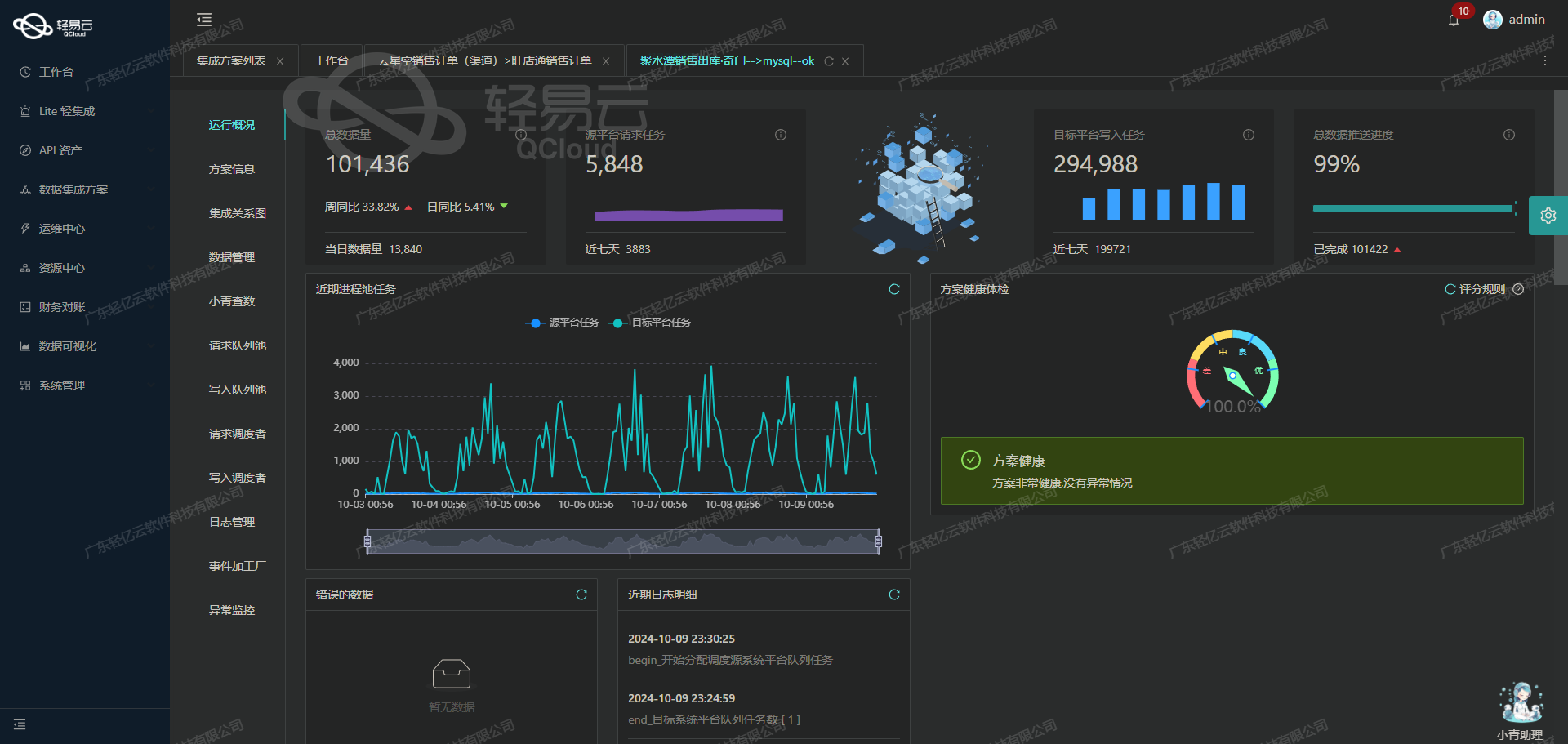
在实际业务场景中,如何高效、精准地获取和处理来自不同系统的数据是每个企业面临的关键挑战。本次分享的技术案例将重点介绍如何通过轻易云集成平台,将金蝶云星辰V2系统中的仓库信息无缝对接到综合数据管理平台。此解决方案依托轻易云强大的数据写入能力与实时监控机制,实现了高吞吐量的数据传输和全程跟踪,使得大规模数据集成任务得以顺利完成。
首先,需要从金蝶云星辰V2获取仓库信息,这里使用其提供的API接口/jdy/v2/bd/store进行定时可靠的数据抓取。在实现过程中,我们需要应对多个技术性难题,包括但不限于接口分页处理、限流控制以及数据格式差异适配。以下列举几个主要步骤及注意事项:
-
定时可靠的数据抓取: 通过配置任务调度器,确保定时调用接口
/jdy/v2/bd/store。这是为了保证新增加或更新的仓库数据信息能够被及时且稳定地获取。 -
批量处理与限流控制: 金蝶云星辰V2 API存在一定的请求频率限制,因此需要实现有效的限流策略。同时,为了提升效率,可以采用批量拉取方式,对返回的大量记录做合理分页处理,以防止单次请求超出服务端响应能力。
-
自定义转换逻辑与映射配置: 获取到原始数据后,需要根据业务需求进行相应字段转换和映射。例如,不同系统间可能存在日期格式、数值类型等方面的不一致,这就要求我们在轻易云平台上自行编写转化规则,并利用可视化工具来直观地设计并调整这些规则。
-
高效写入与异常重试机制: 数据清洗完毕后,通过轻易云的平台API执行“写入空操作”,大规模、高速地将整理后的信息导入目标数据库。在整个过程中,还需保证有完善的异常检测和错误重试机制,以提高整体流程鲁棒性,避免漏单现象发生。
-
集中监控与日志记录: 借助中央监控系统,对整个ETL(抽取-转换-加载)过程进行实时监督。一旦某环节出现问题,可即时收到告警通知,同时详细日志也会帮助对于出现的问题根因定位,从而尽快采取补救措施。
以上,仅仅是该技术案例的一部分概述内容,在接下来的具体实施方案中,会更加详细分析每
调用金蝶云星辰V2接口获取并加工数据
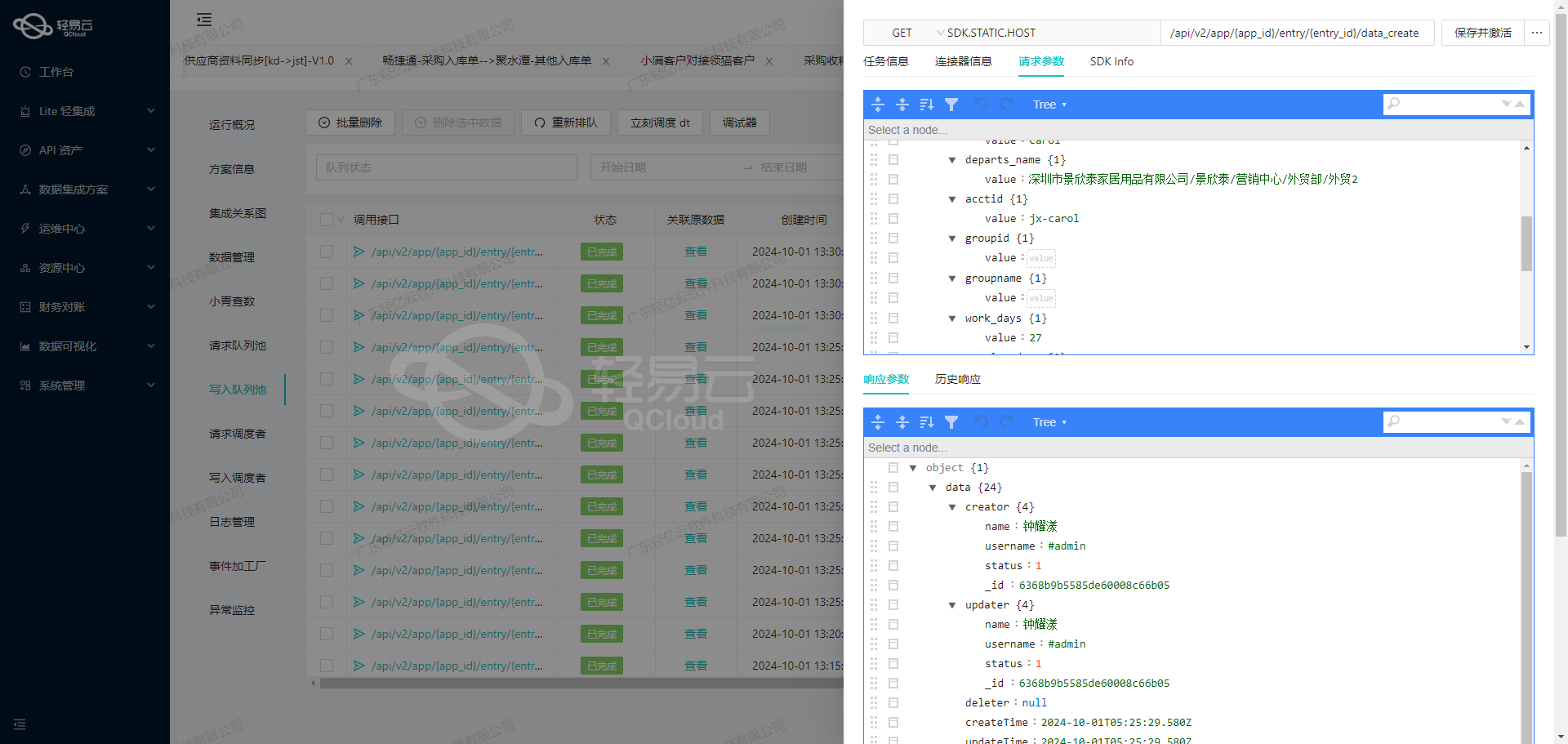
在数据集成生命周期的第一步,我们需要调用源系统的API接口以获取原始数据。本文将详细探讨如何通过轻易云数据集成平台调用金蝶云星辰V2接口/jdy/v2/bd/store来查询仓库信息,并对获取的数据进行初步加工。
接口配置与请求参数
首先,我们需要了解接口的基本配置和请求参数。根据提供的元数据配置,接口为/jdy/v2/bd/store,请求方法为GET,主要用于查询仓库信息。以下是具体的请求参数:
enable: 是否启用,固定值为"1"。page_size: 每页个数,通过占位符{PAGINATION_PAGE_SIZE}动态设置。modify_start_time: 修改时间的开始时间戳,通过占位符{LAST_SYNC_TIME}000动态设置。modify_end_time: 修改时间的结束时间戳,通过占位符{CURRENT_TIME}000动态设置。group_id: 类别ID,可选参数,用于过滤特定类别的仓库信息。page: 当前页码,固定值为"1"。
这些参数确保了我们能够灵活地分页查询,并根据时间范围筛选出需要的数据。
请求示例
为了更好地理解如何调用该接口,以下是一个具体的请求示例:
GET /jdy/v2/bd/store?enable=1&page_size=100&modify_start_time=1672531200000&modify_end_time=1672617600000&page=1 HTTP/1.1
Host: api.kingdee.com
Authorization: Bearer {ACCESS_TOKEN}在这个示例中,我们假设分页大小为100条记录,每次同步的时间范围从2023年1月1日00:00:00到2023年1月2日00:00:00。
数据清洗与转换
获取到原始数据后,需要对其进行清洗和转换,以便后续处理。轻易云平台提供了自动填充响应(autoFillResponse)的功能,可以简化这一过程。以下是一个典型的数据清洗与转换步骤:
-
字段映射:将API返回的数据字段映射到目标系统所需的字段。例如,将返回结果中的
number映射到目标系统中的仓库编号,将id映射到仓库ID。 -
数据过滤:根据业务需求过滤掉不必要的数据。例如,只保留启用状态为"1"的仓库信息。
-
格式转换:将日期、时间等字段转换为目标系统所需的格式。例如,将时间戳转换为标准日期格式。
代码实现
以下是一个使用Python实现上述过程的示例代码:
import requests
import json
from datetime import datetime
# 定义API URL和请求头
api_url = "https://api.kingdee.com/jdy/v2/bd/store"
headers = {
"Authorization": "Bearer {ACCESS_TOKEN}"
}
# 定义请求参数
params = {
"enable": "1",
"page_size": "100",
"modify_start_time": f"{int(datetime.timestamp(LAST_SYNC_TIME))}000",
"modify_end_time": f"{int(datetime.timestamp(CURRENT_TIME))}000",
"page": "1"
}
# 发起GET请求
response = requests.get(api_url, headers=headers, params=params)
# 检查响应状态码
if response.status_code == 200:
data = response.json()
# 数据清洗与转换
cleaned_data = []
for item in data['data']:
cleaned_item = {
"warehouse_number": item["number"],
"warehouse_id": item["id"],
# 添加其他需要映射和转换的字段
}
cleaned_data.append(cleaned_item)
# 输出或进一步处理cleaned_data
print(json.dumps(cleaned_data, indent=4))
else:
print(f"Failed to fetch data: {response.status_code}")在这个示例中,我们首先定义了API URL和请求头,然后构建了请求参数并发起GET请求。接着,我们检查响应状态码,如果成功,则对返回的数据进行清洗和转换,最后输出处理后的数据。
通过以上步骤,我们完成了从调用金蝶云星辰V2接口获取原始数据,到对数据进行清洗和初步加工,为后续的数据写入和进一步处理打下基础。这一过程展示了轻易云数据集成平台在处理异构系统间数据无缝对接方面的强大能力。
星辰-查询仓库信息:数据ETL转换与写入轻易云集成平台
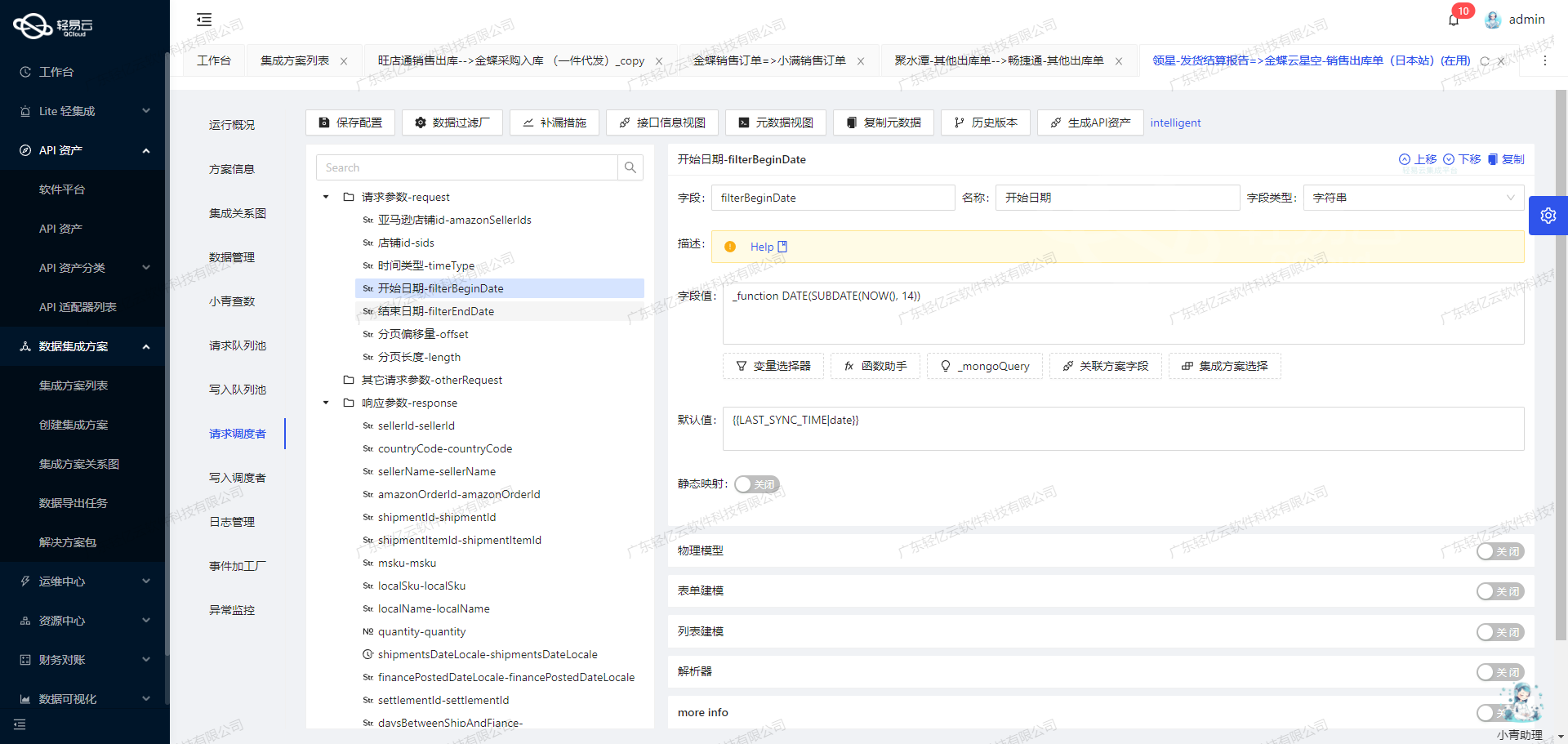
在数据集成的生命周期中,第二步是将已经集成的源平台数据进行ETL转换,并转为目标平台所能够接收的格式,最终写入目标平台。本文将深入探讨这一过程,尤其是如何通过API接口实现数据的无缝对接。
数据请求与清洗
首先,我们需要从源平台获取原始数据,并对其进行清洗。这一步骤通常包括数据验证、去重、标准化等操作,以确保数据的准确性和一致性。
数据转换
在清洗完毕后,下一步是将数据转换为目标平台所能接受的格式。假设我们从星辰系统中查询到以下仓库信息:
{
"warehouse_id": "WH123",
"warehouse_name": "Main Warehouse",
"location": "Beijing",
"capacity": 1000
}为了将这些数据写入轻易云集成平台,我们需要根据元数据配置进行相应的转换。元数据配置如下:
{
"api": "写入空操作",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true
}根据配置,我们需要执行一个POST请求,并且需要进行ID检查。具体步骤如下:
- 构建API请求:根据元数据配置,构建API请求。
- ID检查:确保
warehouse_id在目标系统中是唯一的,以避免重复写入。 - 执行POST请求:将转换后的数据通过POST方法发送到目标平台。
构建API请求
首先,我们需要构建一个符合目标平台API接口要求的数据包。假设轻易云集成平台要求的数据格式如下:
{
"id": "WH123",
"name": "Main Warehouse",
"loc": "Beijing",
"cap": 1000
}我们可以使用以下代码来完成这个转换:
import requests
# 原始数据
source_data = {
"warehouse_id": "WH123",
"warehouse_name": "Main Warehouse",
"location": "Beijing",
"capacity": 1000
}
# 转换后的数据
transformed_data = {
"id": source_data["warehouse_id"],
"name": source_data["warehouse_name"],
"loc": source_data["location"],
"cap": source_data["capacity"]
}
# API请求URL
api_url = "<轻易云集成平台API URL>"
# 执行POST请求
response = requests.post(api_url, json=transformed_data)
if response.status_code == 200:
print("Data successfully written to the target platform.")
else:
print("Failed to write data:", response.content)ID检查
在执行POST请求之前,需要进行ID检查,以确保warehouse_id在目标系统中是唯一的。可以通过查询接口或数据库检查来实现这一点。
def check_id_unique(warehouse_id):
# 假设有一个查询接口用于检查ID是否存在
query_url = f"<轻易云集成平台查询接口>?id={warehouse_id}"
response = requests.get(query_url)
if response.status_code == 200:
return not response.json().get("exists", False)
else:
raise Exception("Failed to check ID uniqueness")
# 检查ID唯一性
if check_id_unique(source_data["warehouse_id"]):
# 执行POST请求写入数据
response = requests.post(api_url, json=transformed_data)
if response.status_code == 200:
print("Data successfully written to the target platform.")
else:
print("Failed to write data:", response.content)
else:
print("Warehouse ID already exists in the target platform.")通过上述步骤,我们可以确保从星辰系统获取的仓库信息经过清洗、转换后,成功写入到轻易云集成平台。这一过程不仅保证了数据的一致性和准确性,还实现了不同系统间的数据无缝对接,提高了业务流程的效率和透明度。