聚水潭数据集成到MySQL的技术实现与优化探讨
在本篇文章中,我们将详细介绍如何通过聚水潭的数据接口,与MySQL数据库进行有效对接,并确保数据处理过程中的精准与高效。具体案例以“聚水潭-采购入库单-->BI邦盈-采购入库表”为核心,分析其运行方案和关键技术要点。
在系统对接过程中,首先需要解决的是如何从聚水潭获取所需的数据。这涉及调用/open/purchasein/query API接口,以定时抓取最新的采购入库单数据。在这一阶段,要特别注意处理分页和限流问题,保证所有数据都能被完整捕获且不漏单。同时,通过实时监控及日志记录功能,可以及时发现并解决潜在的问题。
一旦成功获取到聚水潭的数据,下一个步骤是将这些数据批量快速写入到MySQL数据库中。这里我们使用了MySQL的batchexecute API进行大规模、高吞吐量的数据写操作。这种方法不仅提升了数据写入的效率,还确保了整个流程的稳定性。在此期间,集中监控和告警系统会持续跟踪任务状态,并提供即时反馈,以便快速响应任何异常情况。
此外,为了解决两端系统之间的数据格式差异,我们通过自定义数据转换逻辑,实现了针对不同业务需求和结构特点的数据映射对接。这一步骤同样重要,因为它直接影响最终存储在MySQL中的数据质量。如果出现异常,将触发错误重试机制,从而保障整体集成过程不会因个别失败操作而停滞。
综上所述,本文旨在分享实际应用中的技术细节与挑战,希望为读者提供有价值的信息参考。接下来我们将深入探讨上述各个环节中的具体实现策略及代码示例,帮助您更好地掌握相关技巧。
调用聚水潭接口获取并加工数据
在数据集成生命周期的第一步,我们需要调用源系统聚水潭的接口/open/purchasein/query来获取采购入库单的数据,并对其进行初步加工。以下是具体的技术实现细节和注意事项。
接口配置与请求参数
首先,我们需要配置元数据,以便正确调用聚水潭的API接口。根据提供的元数据配置,接口的基本信息如下:
- API路径:
/open/purchasein/query - 请求方法:
POST - 主要字段:
page_index: 第几页,从1开始page_size: 每页数量,最大不超过50modified_begin: 修改起始时间modified_end: 修改结束时间po_ids: 采购单号列表io_ids: 采购入库单号列表so_ids: 线上单号
这些字段中,modified_begin和modified_end是必填项,它们定义了查询的时间范围。为了确保数据的一致性和完整性,我们通常会使用上次同步时间(LAST_SYNC_TIME)和当前时间(CURRENT_TIME)作为这两个字段的值。
请求示例
以下是一个典型的请求示例:
{
"page_index": 1,
"page_size": 30,
"modified_begin": "{{LAST_SYNC_TIME|datetime}}",
"modified_end": "{{CURRENT_TIME|datetime}}",
"po_ids": "",
"io_ids": "",
"so_ids": ""
}在这个请求中,我们设置了分页参数以及时间范围,但没有指定具体的采购单号或入库单号。这种情况下,系统会返回在指定时间范围内所有符合条件的数据。
数据清洗与转换
一旦我们从聚水潭接口获取到原始数据,需要对其进行清洗和转换,以便后续处理。轻易云平台提供了自动填充响应(autoFillResponse)功能,可以简化这一过程。我们可以利用这个功能将嵌套的数据结构拍平(beatFlat),例如将items字段中的数组元素展开为独立记录。
假设我们从接口获取到以下响应:
{
"total_count": 100,
"items": [
{
"io_id": "12345",
"po_id": "67890",
"warehouse_code": "WH001",
...
},
...
]
}通过自动填充响应功能,我们可以将每个item中的字段直接映射到目标表中。例如,将每个入库单记录映射到BI邦盈系统中的采购入库表。
实践案例
以下是一个实际应用案例,展示如何调用聚水潭接口并处理返回的数据:
-
配置请求参数: 根据业务需求设置分页参数和时间范围。
-
发送请求: 使用HTTP POST方法向聚水潭API发送请求,并接收响应。
-
处理响应数据: 利用轻易云平台的自动填充响应功能,将嵌套数据拍平,并将每条记录插入目标数据库表中。
import requests
import json
# 配置请求参数
payload = {
"page_index": 1,
"page_size": 30,
"modified_begin": last_sync_time,
"modified_end": current_time,
"po_ids": "",
"io_ids": "",
"so_ids": ""
}
# 发起POST请求
response = requests.post("https://api.jushuitan.com/open/purchasein/query", data=json.dumps(payload))
# 检查响应状态码
if response.status_code == 200:
data = response.json()
# 清洗并转换数据
for item in data["items"]:
io_id = item["io_id"]
po_id = item["po_id"]
warehouse_code = item["warehouse_code"]
# 插入到目标数据库表中(示例代码)
insert_into_target_table(io_id, po_id, warehouse_code)
else:
print(f"Error: {response.status_code}")通过上述步骤,我们可以高效地从聚水潭系统获取采购入库单数据,并将其集成到目标系统中。这不仅提升了数据处理效率,还确保了数据的一致性和准确性。
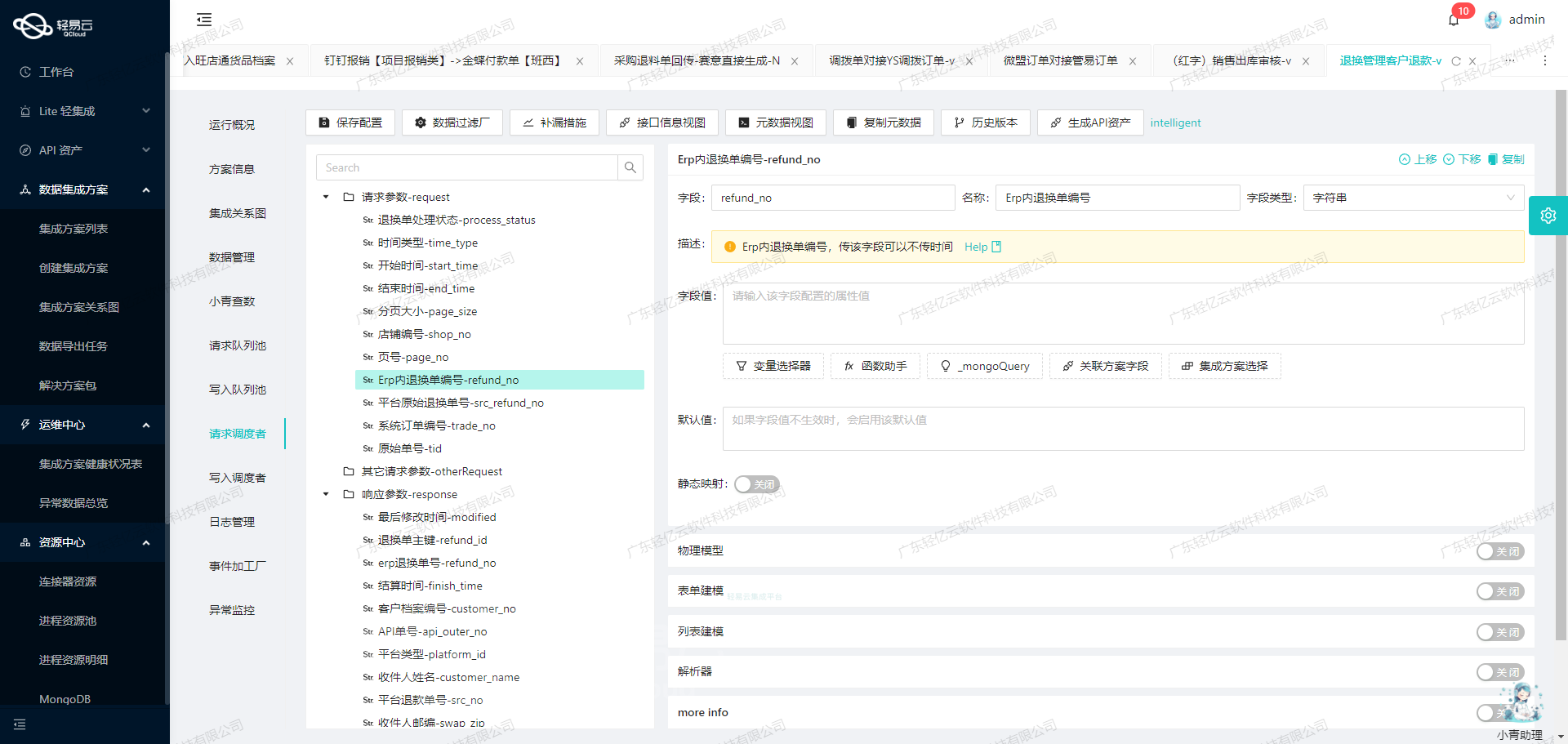
利用轻易云数据集成平台进行ETL转换并写入MySQL API接口
在数据集成的生命周期中,第二步至关重要,即将源平台的数据进行ETL(提取、转换、加载)处理,并最终写入目标平台。在本案例中,我们将聚水潭的采购入库单数据转换为BI邦盈的采购入库表,并通过MySQL API接口写入目标数据库。
数据请求与清洗
在数据集成过程中,首先需要从源系统(聚水潭)获取原始数据。此阶段涉及到数据的请求和初步清洗,以确保数据质量和一致性。轻易云平台提供了全透明可视化的操作界面,使得这一过程变得直观且高效。
数据转换与写入
接下来,我们重点探讨如何将清洗后的数据进行转换,并通过MySQL API接口写入目标平台。以下是元数据配置及其应用。
元数据配置解析
根据提供的元数据配置,我们可以看到以下关键字段:
api: "batchexecute" 表示批量执行SQL语句。method: "SQL" 表示使用SQL方法。number,id,name,idCheck: 这些字段用于唯一标识记录。request: 包含所有需要映射的字段及其对应关系。otherRequest: 包含一些额外的配置,如主语句和限制条件。
主语句解析
主语句定义了如何将记录插入到目标表中:
REPLACE INTO purchasein_query(id, io_id, ts, warehouse, po_id, supplier_id, supplier_name, modified, so_id, out_io_id, status, io_date, wh_id, wms_co_id, remark, tax_rate, labels, archived, merge_so_id, type, creator_name, f_status, l_id, items_ioi_id, items_sku_id, items_i_id, items_unit, items_name, items_qty, items_io_id, items_cost_price, items_cost_amount, items_remark, items_batch_no, items_tax_rate,sns_sku_id,sns_sn) VALUES这条SQL语句使用REPLACE INTO,表示如果记录已存在则更新,否则插入新记录。该语句涵盖了所有必要字段,确保每个字段都能正确映射到目标表。
字段映射与转换
在request部分,每个字段都有详细的配置,包括字段名称、标签、类型和值。例如:
{
"field": "id",
"label": "主键",
"type": "string",
"value": "{io_id}-{items_ioi_id}"
}这个配置表示目标表中的id字段由源表中的io_id和items_ioi_id组合而成。这种灵活的映射方式使得我们可以根据业务需求自定义字段值。
另一个例子是状态字段:
{
"field": "status",
"label": "状态",
"type": "string",
"describe": "状态(WaitConfirm待入库;Confirmed已入库;Cancelled取消;Archive归档;OuterConfirming外部确认中)",
"value": "{status}"
}这个配置直接将源系统中的状态值映射到目标系统中的状态字段,确保状态信息的一致性。
批量执行与限制条件
为了提高性能,我们可以设置批量执行限制:
{
"field": "limit",
"label": "limit",
"type": "string",
"value": "1000"
}这表示每次批量处理最多1000条记录,有助于控制资源消耗并提高效率。
实际操作步骤
- 提取数据:通过轻易云平台从聚水潭系统提取采购入库单数据。
- 清洗数据:对提取的数据进行初步清洗,去除冗余或错误信息。
- 转换数据:根据元数据配置,将清洗后的数据转换为目标格式。
- 写入数据库:使用MySQL API接口,通过批量执行方式将转换后的数据写入BI邦盈的采购入库表。
通过上述步骤,我们实现了从聚水潭到BI邦盈的数据无缝对接,并确保了每个环节的数据质量和一致性。这不仅提升了业务透明度,也极大地提高了工作效率。