聚水潭数据集成到MySQL的技术案例分享
在本篇文章中,我们将深入探讨如何通过轻易云数据集成平台,实现聚水潭供应商信息查询接口的数据高效集成到MySQL数据库。在这个具体案例中,我们的目标是可靠地将聚水潭API /open/supplier/query 查询到的供应商信息,整合并写入至BI崛起-供应商信息表。
为了实现这一目标,本方案采用了多种核心技术特性,包括高吞吐量的数据写入能力、实时监控与告警系统以及自定义的数据转换逻辑等。以下是本次集成过程中的关键技术点和解决策略:
-
定时抓取与批量处理:
- 我们通过配置调度任务实现对聚水潭API接口数据的定时抓取,有效避免因过频请求导致的数据遗漏问题。
- 为保证大容量数据能够被快速且稳定地传输至MySQL数据库,采用了批量处理机制,从而提高整个数据流动过程的效率。
-
分页与限流管理:
- 在调用聚水潭接口时,通过设定合理分页大小以及实施限流管理来控制数据获取速率,以确保每次请求都能够获得完整且有效的数据。这一操作有助于缓解服务器压力,提高整体响应速度。
-
自定义转换逻辑与格式差异处理:
- 由于源端(聚水潭)和目标端(MySQL)的数据结构存在差异,通过轻易云提供的可视化数据流设计工具,设计自定义转换逻辑以适应业务需求。例如,对日期格式、数值单位等字段进行必要转换,使其符合MySQL数据库表格规范。
-
异常处理与错误重试机制:
- 集成过程中难免遇到各种异常情况,如HTTP请求失败或网络不稳定等。我们通过设置全面的异常捕获及错误重试机制,在短时间内自动重新尝试失败操作,保证总体流程不中断,从而提升系统健壮性。
-
集中监控和告警系统:
- 配置并启用了集中监控和告警功能,可以实时跟踪所有数据集成任务状态,并在出现问题时迅速发出预警,这样可以及时采取措施进行纠正。同时,与日志记录结合使用,对每一次操作进行详尽记载,为未来排查故障提供依据。
通过上述技术点及策略,有效保障了从聚水潭到MySQL全过程中的各个环节顺畅无误。此外,通过充分利用平台提供的一些高级功能,不仅使得整个方案运行更加平稳,也为后续优化奠定了坚实基础。接下来,我们将
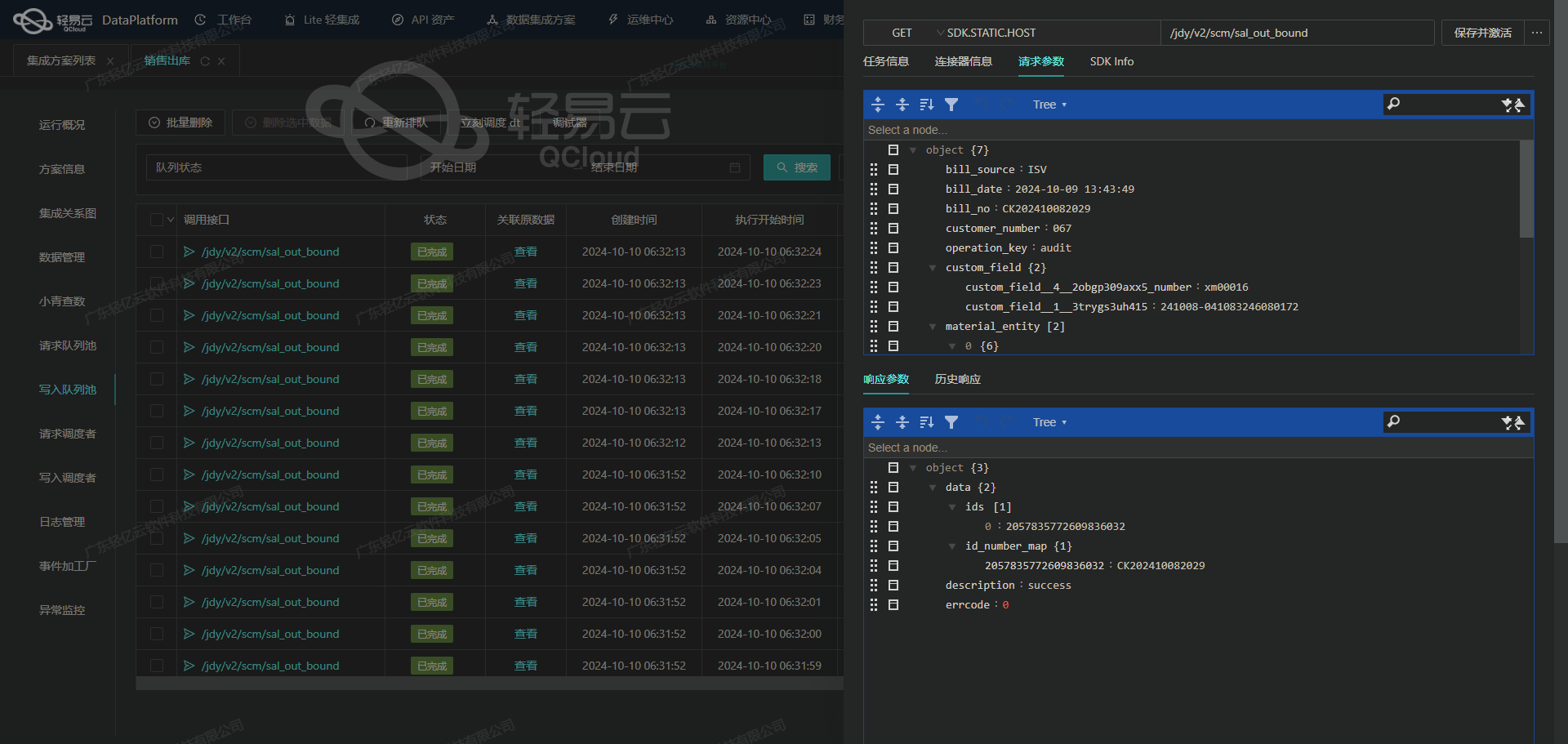
调用聚水潭接口获取并加工数据的技术实现
在轻易云数据集成平台中,生命周期的第一步是调用源系统的API接口获取数据,并对数据进行初步清洗和加工。本文将详细探讨如何通过调用聚水潭接口/open/supplier/query来获取供应商信息,并对数据进行处理。
接口配置与调用
首先,我们需要配置元数据以便正确调用聚水潭的供应商查询接口。以下是元数据配置的关键部分:
{
"api": "/open/supplier/query",
"effect": "QUERY",
"method": "POST",
"number": "supplier_id",
"id": "supplier_id",
"name": "supplier_id",
"idCheck": true,
"request": [
{"field":"page_index","label":"页数","type":"string","describe":"页数","value":"1"},
{"field":"page_size","label":"每页大小","type":"string","describe":"每页大小","value":"50"},
{"field":"modified_begin","label":"修改开始时间","type":"string","describe":"修改开始时间","value":"{{LAST_SYNC_TIME|datetime}}"},
{"field":"modified_end","label":"修改结束时间","type":"string","describe":"修改结束时间","value":"{{CURRENT_TIME|datetime}}"}
],
"autoFillResponse": true,
"condition_bk": [
[{"field": "enabled", "logic": "in", "value": "true"}]
]
}请求参数解析
- 页数 (page_index): 用于分页查询,默认值为
1。 - 每页大小 (page_size): 每次请求返回的数据条数,默认值为
50。 - 修改开始时间 (modified_begin): 数据同步的起始时间,使用占位符
{{LAST_SYNC_TIME|datetime}}动态填充。 - 修改结束时间 (modified_end): 数据同步的结束时间,使用占位符
{{CURRENT_TIME|datetime}}动态填充。
这些参数确保了我们能够灵活地控制数据请求的范围和数量。
数据请求与清洗
在发起POST请求后,系统会返回一个包含供应商信息的数据集。由于我们启用了autoFillResponse选项,平台会自动解析响应内容并填充到相应的数据结构中。接下来,我们需要对返回的数据进行初步清洗和处理。
假设我们收到如下响应:
{
"data": [
{
"supplier_id": "12345",
"name": "供应商A",
"contact_person": "张三",
...
},
...
],
...
}我们需要确保以下几点:
- 数据完整性:检查每条记录是否包含必要字段,如
supplier_id,name,contact_person等。 - 数据格式化:将日期、数字等字段转换为标准格式,以便后续处理。
数据转换与写入
在完成初步清洗后,我们需要将数据转换为目标系统所需的格式,并写入到BI崛起平台的供应商信息表中。这一步通常涉及以下操作:
- 字段映射:将源系统中的字段映射到目标系统中的对应字段。例如,将
supplier_id映射到目标表中的supplier_code。 - 数据类型转换:确保所有字段的数据类型符合目标表的要求。例如,将字符串类型的日期转换为Date类型。
- 批量写入:使用批量操作提高写入效率,减少网络开销。
示例代码片段如下:
def transform_and_write(data):
transformed_data = []
for record in data:
transformed_record = {
'supplier_code': record['supplier_id'],
'supplier_name': record['name'],
'contact': record['contact_person'],
# 更多字段映射...
}
transformed_data.append(transformed_record)
# 批量写入到目标系统
write_to_bi_rise(transformed_data)
def write_to_bi_rise(data):
# 假设有一个批量写入函数
bi_rise_client.bulk_insert('supplier_info', data)通过上述步骤,我们完成了从聚水潭接口获取供应商信息并加工处理后写入BI崛起平台的一整套流程。这不仅提升了数据集成效率,还保证了数据的一致性和准确性。

数据转换与写入MySQLAPI接口的技术实现
在数据集成的生命周期中,第二步是将已经集成的源平台数据进行ETL(提取、转换、加载)转换,并最终写入目标平台。本案例中,我们将聚水潭的供应商信息查询结果转化为BI崛起的供应商信息表,并通过MySQLAPI接口写入目标平台。
数据请求与清洗
首先,我们从聚水潭平台获取供应商信息。假设我们已经完成了数据请求和清洗步骤,得到了如下结构的数据:
{
"supplier_id": "12345",
"name": "供应商A"
}数据转换与写入
接下来,我们需要将上述数据转换为目标平台MySQLAPI接口能够接收的格式,并最终写入目标数据库。以下是详细的技术实现步骤:
元数据配置解析
根据提供的元数据配置,我们需要构建一个SQL插入语句并执行。元数据配置如下:
{
"api": "execute",
"effect": "EXECUTE",
"method": "SQL",
"number": "id",
"id": "id",
"name": "id",
"idCheck": true,
"request": [
{
"field": "main_params",
"label": "主参数",
"type": "object",
"describe": "对应主语句内的动态参数",
"children": [
{
"field": "co_name",
"label": "供应商公司名",
"type": "string",
"value": "{name}"
},
{
"field": "supplier_co_id",
"label": "供应商编号",
"type": "string",
"value": "{supplier_id}"
}
]
}
],
...
}动态参数映射
根据元数据配置中的main_params字段,我们需要将源数据中的字段映射到SQL语句中的动态参数。具体映射关系如下:
co_name对应{name}supplier_co_id对应{supplier_id}
因此,源数据中的 name 和 supplier_id 字段需要被替换为 SQL 插入语句中的相应占位符。
构建SQL语句
根据元数据配置中的 main_sql 字段,构建插入语句:
INSERT INTO querymysupplier (
co_name,
supplier_co_id
) VALUES (
:co_name,
:supplier_co_id
);通过动态参数映射,将上述 SQL 语句中的占位符替换为实际值:
INSERT INTO querymysupplier (
co_name,
supplier_co_id
) VALUES (
'供应商A',
'12345'
);执行SQL语句
使用 MySQLAPI 接口执行上述 SQL 插入语句。假设我们有一个执行 SQL 的 API 接口,如下所示:
POST /api/execute
Content-Type: application/json
{
...
// SQL 执行相关参数
}我们需要将构建好的 SQL 插入语句发送到该 API 接口进行执行。
API 请求示例
以下是一个完整的 API 请求示例:
POST /api/execute
Content-Type: application/json
{
...
// 动态参数
main_params: {
co_name: '供应商A',
supplier_co_id: '12345'
},
// 主SQL语句
main_sql: `
INSERT INTO querymysupplier (
co_name,
supplier_co_id
) VALUES (
:co_name,
:supplier_co_id
);
`
}返回结果处理
执行成功后,API 接口会返回插入操作的结果,例如 lastInsertId,用于后续操作或记录日志。
小结
通过上述步骤,我们成功地将聚水潭平台的供应商信息查询结果经过ETL转换,最终通过MySQLAPI接口写入到BI崛起的平台。这一过程充分利用了轻易云数据集成平台的强大功能,实现了不同系统间的数据无缝对接,提高了业务透明度和效率。