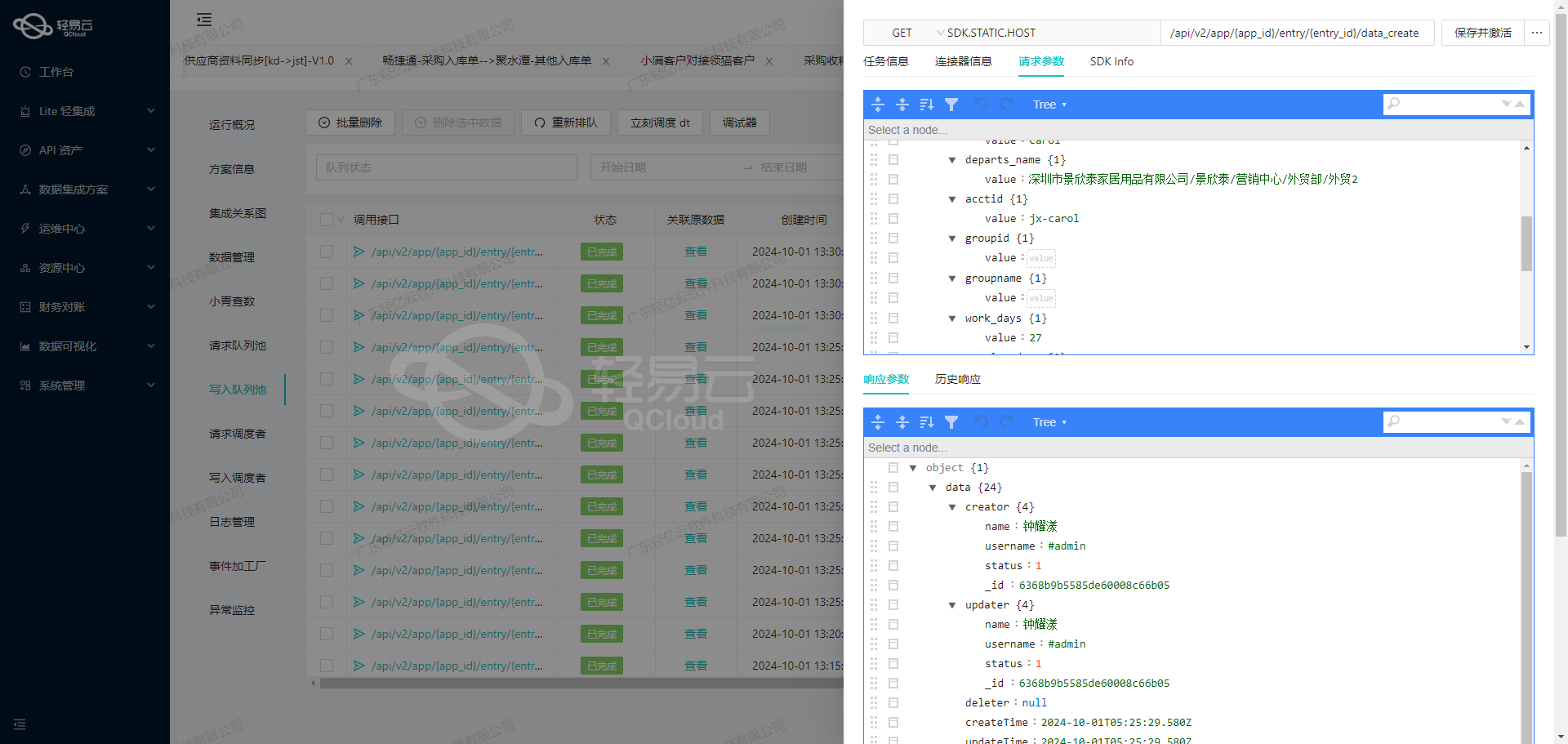
星辰-查询商品信息:金蝶云星辰V2数据集成到轻易云集成平台
在本技术案例中,我们将详细分享如何通过轻易云数据集成平台实现金蝶云星辰V2的数据无缝对接,并确保数据高效可靠地进行处理。本次任务的核心是实时抓取并写入商品信息,具体方法包括调用金蝶云星辰V2接口获取所需数据,同时解决分页和限流的问题。
为了同步金蝶云星辰V2上的商品数据,需要使用其 /jdy/v2/bd/material API 接口。该接口返回的数据需要在轻易云上完成格式转换和批量写入操作。下面描述了几个关键步骤及注意事项:
-
定时可靠的抓取策略: 定时任务在系统对接中极为重要。我们配置了一套可靠的调度机制,以定期拉取最新的数据。这不仅提升了效率,还能确保每一个产品条目不被遗漏。
-
API调用与分页处理: 由于每次API请求返回的数据量有限,必须设计良好的分页逻辑来不断循环调用接口直至所有记录都被成功获取。在此过程中特别关注频率限制问题,避免因超过请求上限导致服务不可用。
-
数据格式转换与批量写入: 金蝶云星辰V2原始数据显示格式可能与目标平台不完全匹配。因此,我们需构建一套灵活的映射规则,将源端字段精确对应到目的端。同时,为了提高写入性能,我们采取批量操作方式,在保证准确信息传递基础上缩减响应时间,提高整体效率。
-
异常处理与重试机制: 数据传输过程中难免会遇到网络波动或其他异常情况,因此我们设置了完备的错误捕获和重试机制。一旦某个环节出现故障,该机制可自动检测并重新尝试,保障业务流程连续性,不影响最终结果达成。
以下内容将具体介绍这些步骤及实现细节,包括各种配置文件、代码示例以及潜在的问题解决方案,从而帮助读者更全面地理解这一系统对接过程。
调用金蝶云星辰V2接口获取并加工数据
在轻易云数据集成平台中,调用源系统接口是数据处理生命周期的第一步。本文将详细探讨如何通过调用金蝶云星辰V2接口/jdy/v2/bd/material来获取商品信息,并对数据进行初步加工。
接口配置与调用
首先,我们需要了解接口的基本配置和调用方式。根据提供的元数据配置,金蝶云星辰V2接口/jdy/v2/bd/material是一个GET请求,用于查询商品信息。以下是该接口的主要配置参数:
- API路径:
/jdy/v2/bd/material - 请求方法: GET
- 功能: 查询(QUERY)
- 主要字段:
number: 商品编号id: 商品IDmodify_start_time: 修改时间的开始时间戳(毫秒)modify_end_time: 修改时间的结束时间戳(毫秒)page: 当前页,默认值为1page_size: 每页显示条数,默认值为20
请求参数设置
在实际操作中,我们需要根据业务需求设置请求参数。以下是具体的请求参数配置:
{
"modify_start_time": "{LAST_SYNC_TIME}000",
"modify_end_time": "{CURRENT_TIME}000",
"page": "1",
"page_size": "20"
}- modify_start_time 和 modify_end_time 用于指定查询时间范围,这里使用了占位符
{LAST_SYNC_TIME}和{CURRENT_TIME}来动态生成时间戳。 - page 和 page_size 用于分页查询,确保每次请求返回的数据量可控。
数据获取与初步加工
在成功调用接口并获取数据后,需要对返回的数据进行初步加工。这一步骤通常包括数据清洗、格式转换等操作,以便后续的数据处理和写入。
假设我们从接口获取到以下JSON格式的数据:
{
"data": [
{
"id": "12345",
"number": "P001",
"name": "商品A",
"modify_time": "1633024800000"
},
{
"id": "12346",
"number": "P002",
"name": "商品B",
"modify_time": "1633024800000"
}
],
"total_count": 2,
"page": 1,
"page_size": 20
}我们需要对这些数据进行清洗和转换。例如,将时间戳转换为人类可读的日期格式,并过滤掉不必要的字段:
import json
from datetime import datetime
# 假设response_data是从API获取到的JSON数据
response_data = '''
{
"data": [
{
"id": "12345",
"number": "P001",
"name": "商品A",
"modify_time": "1633024800000"
},
{
"id": "12346",
"number": "P002",
"name": "商品B",
"modify_time": "1633024800000"
}
],
...
}
'''
# 将JSON字符串转换为Python字典
data = json.loads(response_data)
# 定义一个函数将时间戳转换为日期格式
def convert_timestamp(timestamp):
return datetime.fromtimestamp(int(timestamp) / 1000).strftime('%Y-%m-%d %H:%M:%S')
# 对数据进行清洗和转换
cleaned_data = []
for item in data['data']:
cleaned_item = {
'id': item['id'],
'number': item['number'],
'name': item['name'],
'modify_date': convert_timestamp(item['modify_time'])
}
cleaned_data.append(cleaned_item)
print(cleaned_data)上述代码将原始数据中的modify_time字段转换为可读日期,并保留了id、number和name字段。
自动填充响应
在轻易云平台中,可以利用自动填充响应功能(autoFillResponse)来简化部分操作。根据元数据配置,该功能已经启用,这意味着平台会自动处理一些常见的数据填充任务,例如分页信息和总记录数。
通过以上步骤,我们完成了从调用金蝶云星辰V2接口获取商品信息到初步加工数据的全过程。这一过程不仅展示了如何高效地集成异构系统,还体现了轻易云平台在简化复杂操作方面的强大能力。

数据集成生命周期中的ETL转换与写入
在数据集成生命周期的第二步,我们将已经集成的源平台数据进行ETL转换,转为目标平台所能接收的格式,并最终写入目标平台。本文将详细探讨如何利用轻易云数据集成平台实现这一过程,特别是通过API接口完成数据的转换与写入。
元数据配置解析
在本案例中,我们的目标是将星辰平台上的商品信息查询结果写入轻易云集成平台。我们使用如下元数据配置:
{
"api": "写入空操作",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true
}该配置包含以下关键元素:
api: 指定要调用的API接口,这里是“写入空操作”。effect: 定义操作类型,这里是“EXECUTE”表示执行操作。method: HTTP请求方法,这里是“POST”。idCheck: 指示是否需要进行ID校验,这里设置为true。
数据请求与清洗
在进入ETL转换之前,首先需要从星辰平台获取商品信息。这一步通常包括发送HTTP请求并接收响应数据。假设我们已经获取到如下JSON格式的数据:
{
"items": [
{"id": 1, "name": "商品A", "price": 100},
{"id": 2, "name": "商品B", "price": 200}
]
}数据转换
接下来,我们需要将上述数据转换为轻易云集成平台API接口所能接收的格式。假设目标格式要求每个商品信息包含productId、productName和productPrice字段。我们可以编写如下Python代码进行转换:
import json
source_data = {
"items": [
{"id": 1, "name": "商品A", "price": 100},
{"id": 2, "name": "商品B", "price": 200}
]
}
def transform_data(source):
transformed_items = []
for item in source["items"]:
transformed_item = {
"productId": item["id"],
"productName": item["name"],
"productPrice": item["price"]
}
transformed_items.append(transformed_item)
return transformed_items
transformed_data = transform_data(source_data)
print(json.dumps(transformed_data, ensure_ascii=False))输出结果为:
[
{"productId": 1, "productName": "商品A", "productPrice": 100},
{"productId": 2, "productName": "商品B", "productPrice": 200}
]数据写入
完成数据转换后,我们需要将其通过API接口写入轻易云集成平台。根据元数据配置,我们使用POST方法,并且需要进行ID校验。以下是一个示例HTTP请求:
import requests
url = 'https://api.qingyiyun.com/write'
headers = {'Content-Type': 'application/json'}
data = json.dumps(transformed_data, ensure_ascii=False)
response = requests.post(url, headers=headers, data=data)
if response.status_code == 200:
print("Data written successfully")
else:
print(f"Failed to write data: {response.status_code}")该代码段通过POST方法将转换后的数据发送到指定URL,并检查响应状态码以确认操作是否成功。
ID校验机制
由于元数据配置中idCheck设置为true,我们必须确保每条记录在写入前都进行了ID校验。这通常涉及检查每个商品的ID是否已经存在于目标系统中,以避免重复插入或覆盖已有记录。实现这一功能可以通过在发送请求前增加一个验证步骤:
def check_id_exists(product_id):
# 假设有一个API可以查询现有记录
check_url = f'https://api.qingyiyun.com/check/{product_id}'
response = requests.get(check_url)
return response.status_code == 200
valid_data = [item for item in transformed_data if not check_id_exists(item['productId'])]
if valid_data:
data = json.dumps(valid_data, ensure_ascii=False)
response = requests.post(url, headers=headers, data=data)
if response.status_code == 200:
print("Data written successfully")
else:
print(f"Failed to write data: {response.status_code}")
else:
print("No new data to write")通过上述步骤,我们确保了只有未存在于目标系统中的新记录才会被写入,从而实现了ID校验机制。
以上内容展示了如何利用轻易云数据集成平台,通过ETL过程将源平台的数据转换并写入目标平台。在实际应用中,根据具体需求和环境可能需要进一步调整和优化这些步骤。