旺店通旗舰版-售后单数据集成到MySQL的技术案例分享
在本文中,我们将详细探讨如何利用轻易云数据集成平台,将旺店通·旗舰奇门中的售后订单信息高效地接入至MySQL数据库。我们的具体任务是从2024年起,对接含退换单查询的售后单,并确保整个数据处理过程具备高可靠性与实时监控功能。
接口及API相关细节概述
首先,项目涉及的两个主要接口分别为:
- 旺店通·旗舰奇门的数据获取接口:
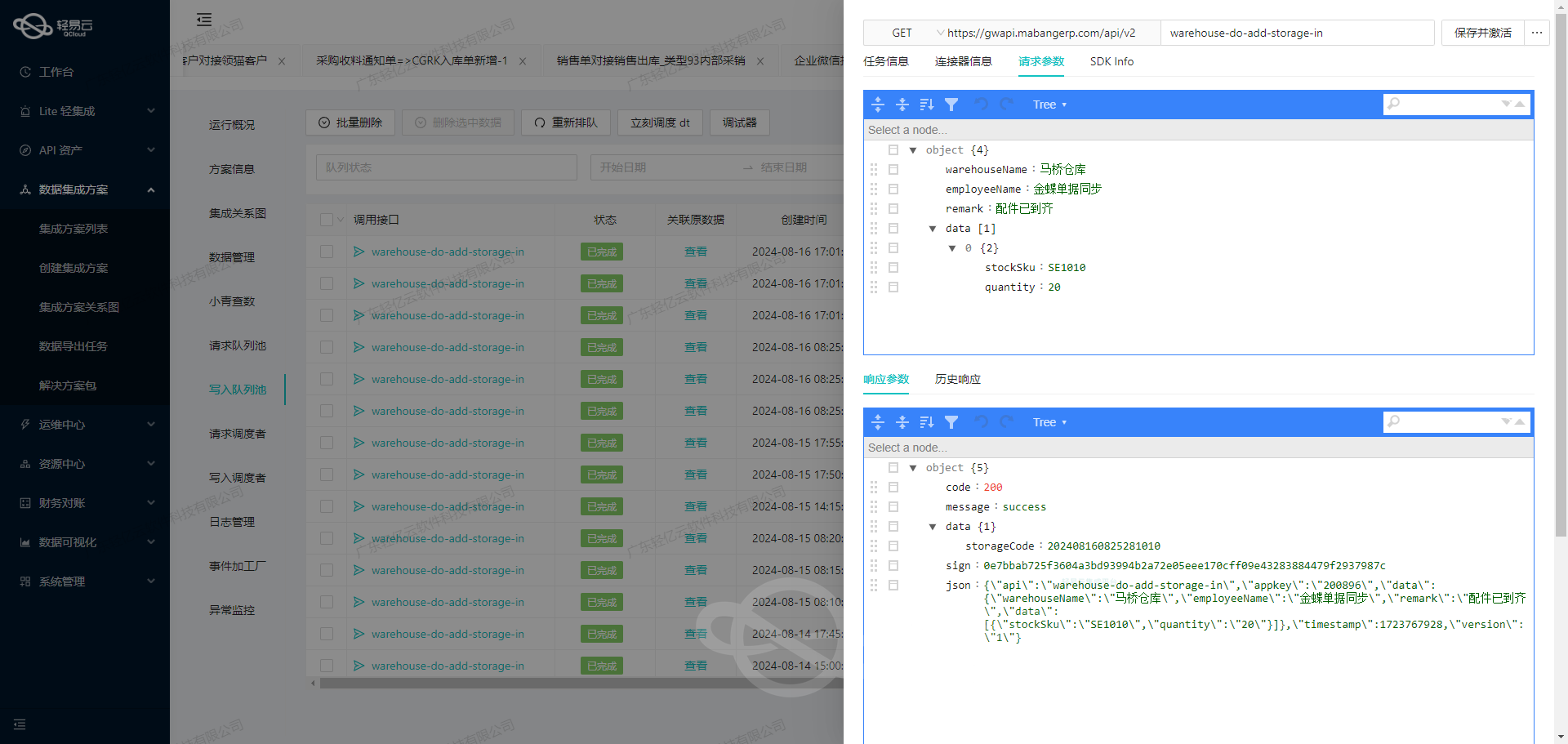
wdt.aftersales.refund.refund.search - MySQL的数据写入接口:
batchexecute
这两个接口构成了我们整个系统对接方案的重要组成部分。在实际操作中,需要解决以下几个重要技术问题:
-
高吞吐量的数据写入能力:由于旺店通·旗舰奇门每天会产生大量的售后订单记录,确保这些数据能够快速稳定地批量写入到MySQL数据库,是首要挑战。
-
分页和限流问题:面对海量数据时,通过分页机制和合理控制请求频率,可以有效避免对源系统造成负担,同时保证抓取效率。
-
自定义数据转换逻辑:由于两套系统间可能存在不同的数据结构,因此需灵活运用自定义转换逻辑以适应特定业务需求。
-
集中监控和异常处理机制:为了保障任何环节出现故障都能及时发现并处理,集中的监控告警系统以及错误重试机制必不可少。
数据质量与可视化管理
在实际配置过程中,可视化的数据流设计工具无疑让繁琐复杂的流程变得更为直观。同时,通过支持定制化映射规则,我们可以精确控制每一条进入MySQL表格内的数据格式及内容,从而实现高度一致性的维护。此外,有必要进行实时日志记录,便于随时追溯历史操作并定位潜在问题点。
实现步骤预览
为了进一步展开具体实施方案,我们将依次覆盖以下关键步骤:
- 配置并调用
wdt.aftersales.refund.refund.searchAPI,从源头获取所需售后订单信息; - 采用批量模式通过
batchexecuteAPI,高效完成大规模数据向MySQL表格导入; - 构建周期性调度任务,实现自动、可靠、多次触发爬取动作;
- 定义异常处理策略,包括事务回滚及重试逻辑等,以避免因临时网络或服务故障导致漏数情况发生;
- 设置全面、透明的性能监控体系
调用旺店通·旗舰奇门接口获取并加工数据
在数据集成生命周期的第一步,我们需要调用源系统的API接口获取数据,并对其进行初步加工。本文将详细探讨如何通过轻易云数据集成平台调用旺店通·旗舰奇门接口wdt.aftersales.refund.refund.search来获取售后订单数据,并为后续的数据处理和分析做好准备。
接口概述
接口wdt.aftersales.refund.refund.search用于查询售后退款单信息,支持分页查询。该接口采用POST请求方式,返回符合条件的售后退款单列表。主要字段包括退款单号(refund_no)、退款ID(refund_id)和交易ID(tid)。
请求参数配置
根据元数据配置,我们需要设置分页参数和业务参数,以确保能够正确地获取所需的数据。
-
分页参数:
page_size:每页返回的数据条数,默认为50。page_no:当前页号,从1开始。
-
业务参数:
modified_from:查询的开始时间,使用上次同步时间(LAST_SYNC_TIME)。modified_to:查询的结束时间,使用当前时间(CURRENT_TIME)。
请求参数的JSON结构如下:
{
"pager": {
"page_size": "50",
"page_no": "1"
},
"params": {
"modified_from": "{{LAST_SYNC_TIME|datetime}}",
"modified_to": "{{CURRENT_TIME|datetime}}"
}
}数据请求与清洗
在轻易云数据集成平台中,我们可以通过配置上述请求参数来调用API接口并获取数据。以下是具体步骤:
-
配置请求: 在平台中创建一个新的API调用任务,选择接口
wdt.aftersales.refund.refund.search,并填写上述请求参数。 -
发送请求: 平台会根据配置自动发送POST请求到旺店通·旗舰奇门系统,并接收返回的数据。
-
数据清洗: 接收到的数据可能包含嵌套结构或冗余信息,需要进行初步清洗。例如,将嵌套的detail_list字段展开,以便于后续处理。
数据转换与写入
经过清洗后的数据,需要进行格式转换以适应目标系统的要求。假设目标系统BI泰海需要特定格式的售后订单表,我们可以通过以下步骤完成转换:
-
字段映射: 将源系统中的字段映射到目标系统中的对应字段。例如,将refund_no映射为订单编号,将tid映射为交易ID等。
-
格式转换: 根据目标系统的要求,对日期、数值等字段进行格式转换。例如,将日期格式从ISO标准转换为目标系统所需的格式。
-
写入目标系统: 将转换后的数据写入BI泰海的售后订单表中。此过程可以通过轻易云平台提供的数据写入功能实现,确保数据无缝对接。
示例代码
以下是一个示例代码片段,用于展示如何在轻易云平台中实现上述过程:
import requests
import json
from datetime import datetime
# 设置请求URL和头部信息
url = "https://api.wangdian.cn/openapi2/wdt_aftersales_refund_refund_search.php"
headers = {"Content-Type": "application/json"}
# 构建请求参数
params = {
"pager": {
"page_size": "50",
"page_no": "1"
},
"params": {
"modified_from": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"modified_to": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
}
# 发送POST请求
response = requests.post(url, headers=headers, data=json.dumps(params))
# 处理响应数据
if response.status_code == 200:
data = response.json()
# 清洗和转换数据
cleaned_data = clean_and_transform(data)
# 写入目标系统
write_to_bi_taihai(cleaned_data)
else:
print("Error:", response.status_code, response.text)
def clean_and_transform(data):
# 清洗和转换逻辑
pass
def write_to_bi_taihai(data):
# 写入目标系统逻辑
pass通过以上步骤,我们可以高效地调用旺店通·旗舰奇门接口获取售后订单数据,并进行必要的清洗和转换,为后续的数据分析和处理奠定基础。
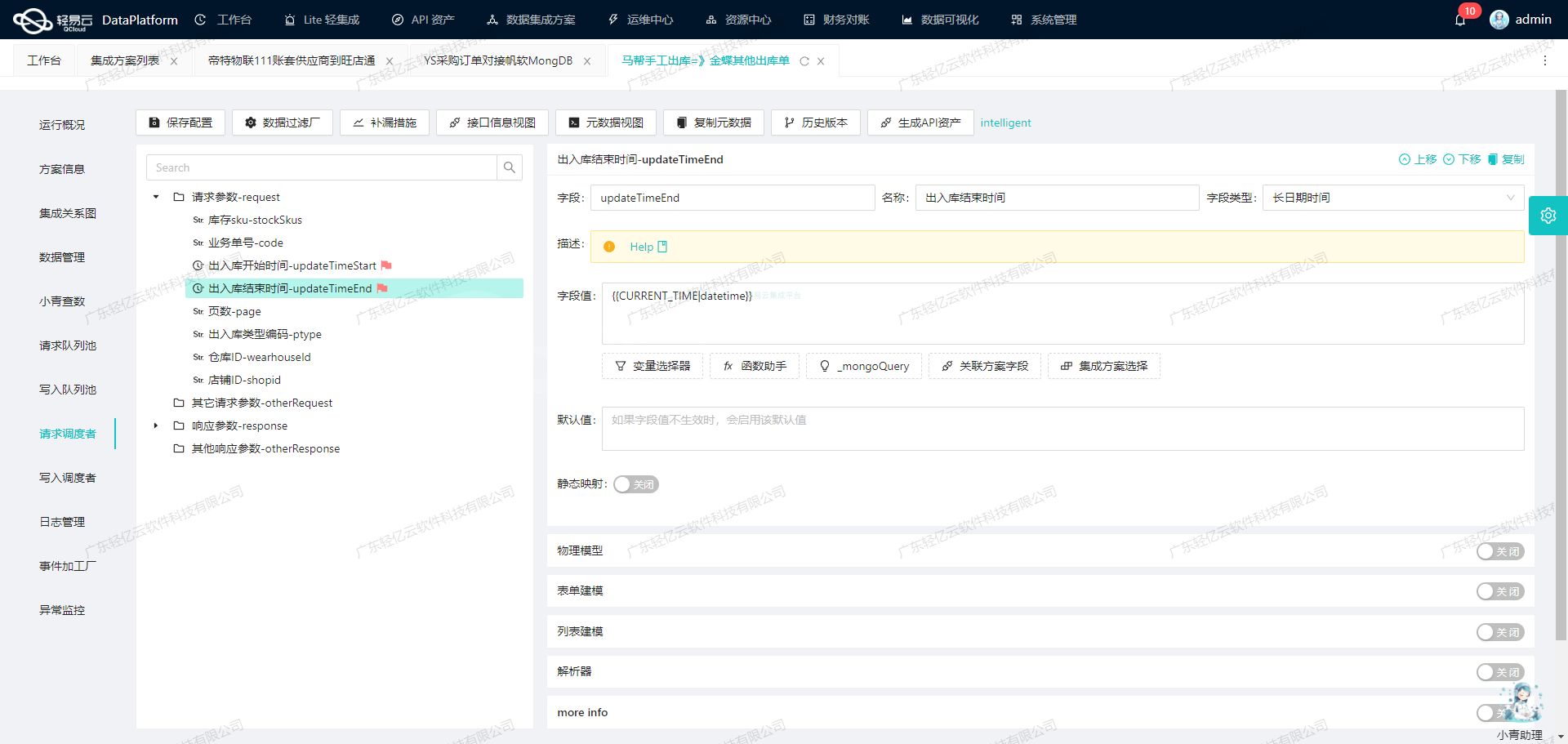
使用轻易云数据集成平台进行ETL转换并写入MySQLAPI接口
在数据集成的生命周期中,ETL(提取、转换、加载)是关键的一步。本文将详细探讨如何使用轻易云数据集成平台,将已集成的源平台数据进行ETL转换,并最终写入目标平台MySQLAPI接口。
数据请求与清洗
首先,我们需要从源平台获取原始数据。在本案例中,源平台为旺店通旗舰版的售后单。获取的数据可能包含各种格式和类型的信息,因此需要进行清洗和标准化处理,以确保数据的一致性和完整性。
数据转换与写入
接下来,我们进入数据转换阶段。根据提供的元数据配置,我们将详细介绍如何将这些数据字段映射到目标MySQLAPI接口所需的格式。
元数据配置解析
以下是元数据配置中的关键字段及其对应关系:
{
"api": "batchexecute",
"effect": "EXECUTE",
"method": "SQL",
"number": "id",
"id": "id",
"name": "id",
"idCheck": true,
"request": [
{"field":"refund_id","label":"退换单id","type":"string","value":"{refund_id}"},
{"field":"src_tids","label":"原始单号","type":"string","value":"{src_tids}"},
{"field":"refund_no","label":"退换单号","type":"string","value":"{refund_no}"},
{"field":"remark","label":"备注","type":"string","value":"{remark}"},
{"field":"type","label":"退换单类型","type":"string","value":"{type}"},
{"field":"stockin_status","label":"入库状态","type":"string","describe":"0:无需入库;1:待入库;2:部分入库;3:全部入库;4:终止入库","value":"{stockin_status}"}
// 更多字段...
],
"otherRequest": [
{
"field": "main_sql",
"label": "主语句",
"type": "string",
"describe": "SQL首次执行的语句,将会返回:lastInsertId",
"value":
`REPLACE INTO aftersales_refund_refund_search (
refund_id, src_tids, refund_no, remark, type, stockin_status, flag_name, return_goods_count,
receiver_telno, receiver_name, modified, note_count, shop_no, from_type, created,
settle_time, check_time, return_logistics_no, trade_no_list, guarantee_refund_amount,
return_goods_amount, return_logistics_name, reason_name, refund_reason,
buyer_nick, operator_name, actual_refund_amount,revert_reason_name,
return_warehouse_no,direct_refund_amount,receive_amount,
customer_name,fenxiao_nick_name,status,
shop_id,trade_id,raw_refund_nos,pay_id,
provider_refund_no,shop_platform_id,
tid_list ,sub_platform_id ,
return_warehouse_id ,platform_id ,
wms_owner_no ,warehouse_type ,
bad_reason ,modified_date ,
return_mask_info ,process_status ,
reason_id ,revert_reason ,
customer_id ,consign_mode ,
refund_time ,fenxiao_tid ,
fenxiao_nick_no ,wms_code ,
detail_list_rec_id ,detail_list_refund_id ,
detail_list_oid ,detail_list_trade_order_id ,
detail_list_platform_id ,detail_list_tid ,
detail_list_trade_no ,detail_list_num ,
detail_list_price ,detail_listal_price ,
detail_list_checked_cost_price ,
detail_list_refund_num ,
detail_list_total_amount ,
detail_list_refund_amount ,
detail_list_is_guarantee ,
detail_list_goods_no ,
detail_list_goods_name ,
detail_list_spec_name ,
detail_list_spec_no
) VALUES`
},
{"field": "limit", "label": "limit", "type": "string", "value": "1000"}
]
}SQL语句构建
在元数据配置中,main_sql字段定义了主SQL语句,用于将清洗后的数据插入到目标表aftersales_refund_refund_search中。该表包含多个字段,每个字段对应一个具体的数据属性。例如:
refund_id: 对应退款单IDsrc_tids: 对应原始单号refund_no: 对应退款单号remark: 对应备注信息type: 对应退款单类型stockin_status: 对应入库状态(0:无需入库;1:待入库;2:部分入库;3:全部入库;4:终止入库)
其他字段按照类似方式进行映射。
数据写入
通过执行上述构建的SQL语句,可以将转换后的数据批量插入到MySQL数据库中。为了确保操作的高效性和安全性,可以设置批量处理的限制,例如每次处理1000条记录(通过limit字段设置)。
实际操作步骤
- 提取源平台数据:使用API或其他方式从旺店通旗舰版提取售后单相关的数据。
- 清洗和标准化:根据业务需求对提取的数据进行清洗和标准化处理。
- 构建SQL语句:利用元数据配置中的模板,构建插入MySQL数据库的SQL语句。
- 执行批量插入:通过轻易云平台提供的接口,执行批量插入操作,将清洗后的数据写入目标数据库。
通过以上步骤,可以实现从源平台到目标平台的数据无缝对接,确保数据的一致性和完整性。这不仅提升了业务效率,也增强了系统间的数据协同能力。