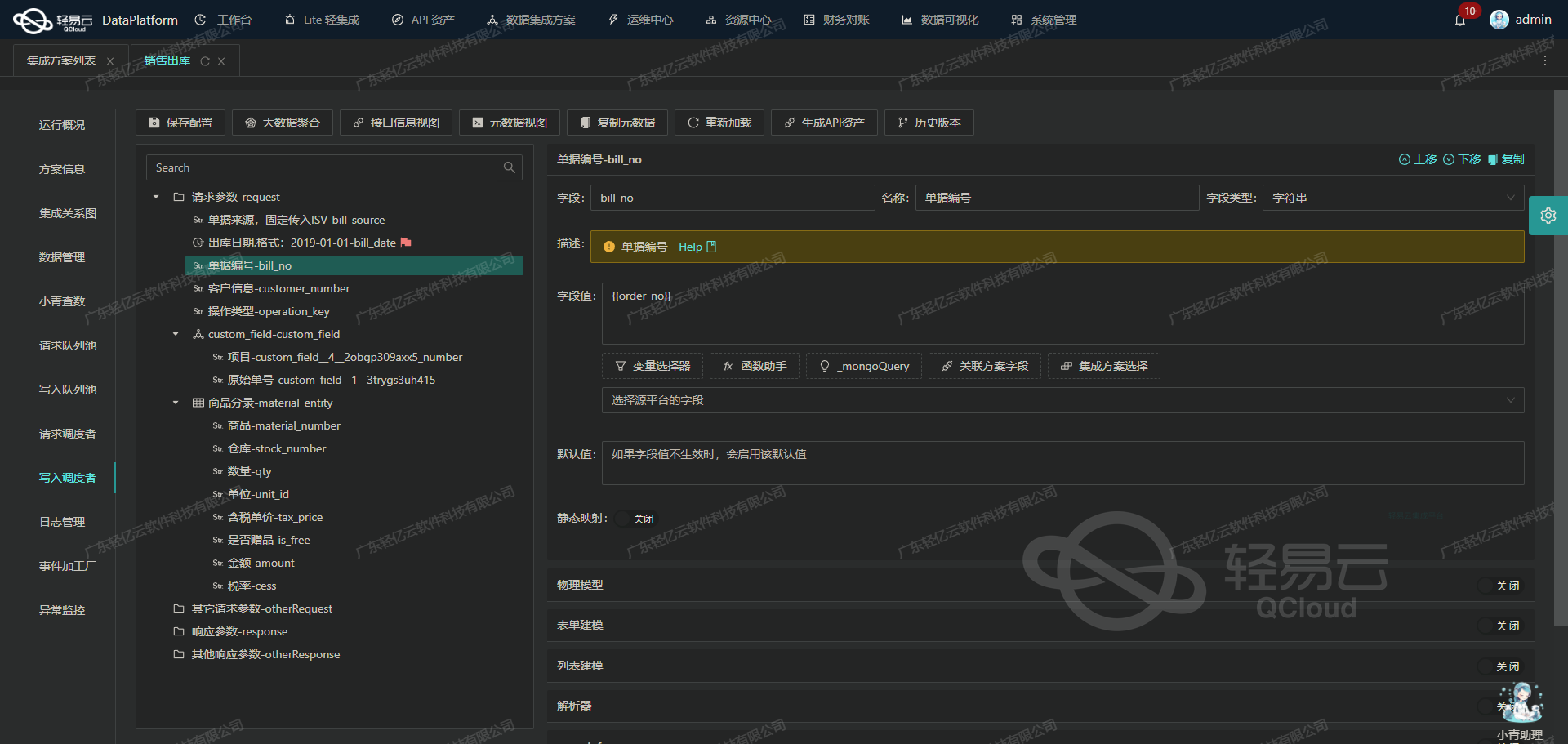
钉钉数据集成到金蝶云星空案例分享:修改下推的付款单③
在企业日常运营中,打通不同系统间的数据孤岛是实现高效管理与决策的重要手段。本文将探讨如何通过轻易云数据集成平台,将钉钉上的付款审批流程数据无缝对接至金蝶云星空,以提高财务处理的自动化和准确性。
一、确保集成钉钉数据不漏单
在这个技术方案中,为了解决可能存在的数据遗漏问题,我们特别关注了两方面:定时可靠地抓取钉钉接口数据和处理分页及限流问题。首先,通过调用topapi/processinstance/get接口,我们可以定期准确地获取付款审批申请记录,并且由于该接口有分页机制,在多次请求过程中需要小心处理页码和每页数量参数以防止丢失关键记录。同时,应用重试机制来应对偶发性的网络异常,从而保证稳定的数据同步。
二、大量数据快速写入到金蝶云星空
为了能够快速批量导入从钉钉获取的大量审批记录,我们采用了金蝶云星空提供的API: batchSave。该API允许一次性写入大量记录,大幅提升了数据传输效率。在实际操作过程中,还针对不同类型字段进行细致映射,以适应金蝶云要求的特定格式。这不仅减少人工干预,提高工作效率,也降低了因手工输入可能带来的错误率。
三、解决跨系统的数据格式差异问题
一个成功的系统对接,需要仔细解决各自平台之间的数据格式差异。在本案例中,从JSON解析开始,到生成符合目标系统要求的数据结构,都经过严格测试与验证。例如,考虑到金蝶云中的日期时间格式与标准ISO 8601有所不同,因此我们特别设计了一套转换方案,使其能无缝兼容。这一过程涵盖字符串格式化、数值单位换算等具体操作,力求确保每一项字段都精确对应。
四、实时监控与日志记录的实现
对于大规模复杂的数据传播任务,有效监控和日志记录显得尤为重要。本次实施方案在整个流程上也加入了全面的实时监控功能,能够随时查看当前任务状态,包括已处理条数、待处理条数、错误发生位置等。同时,每一步骤均进行了详细日志记录,为后续故障排查及性能优化提供宝贵依据。
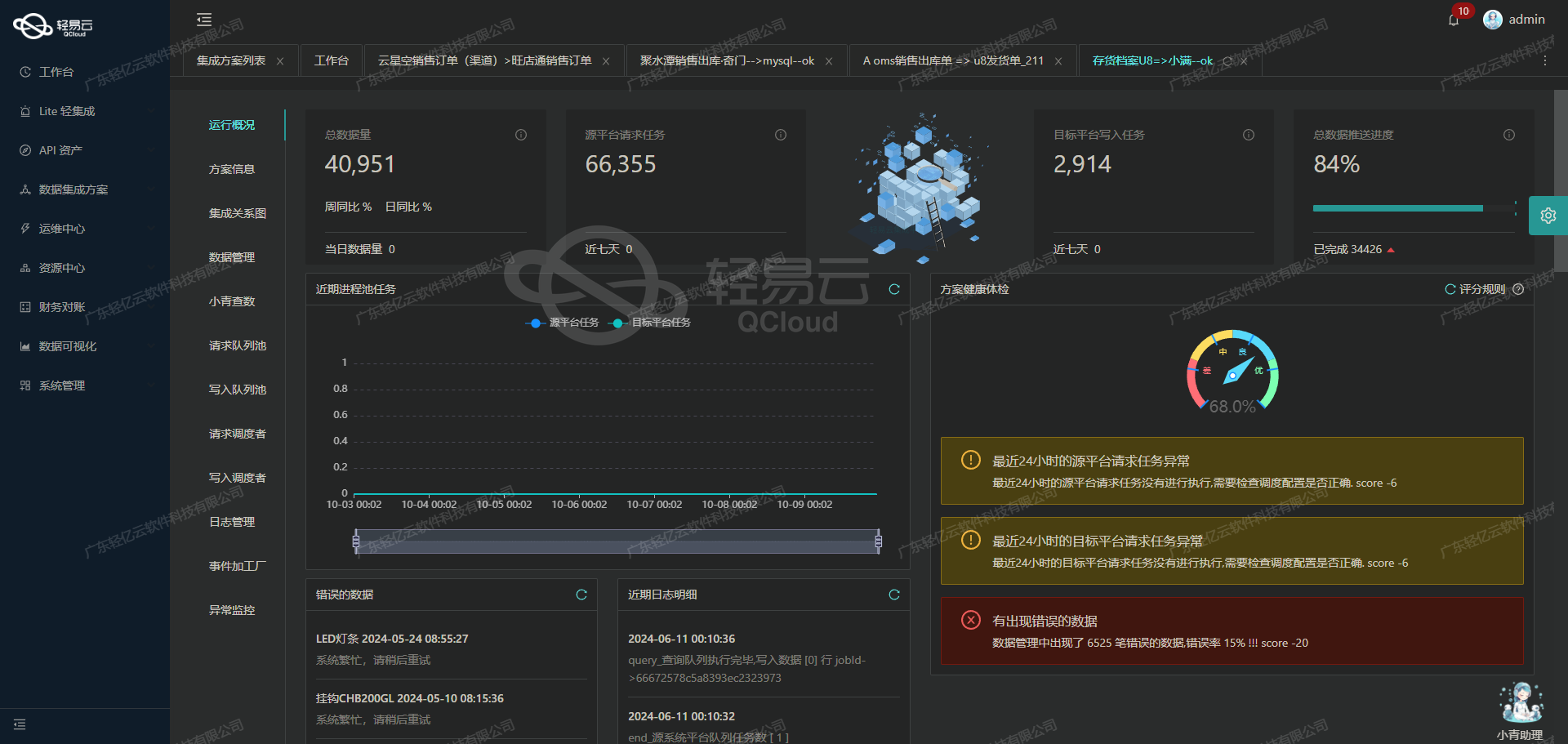
调用钉钉接口topapi/processinstance/get获取并加工数据
在数据集成的生命周期中,调用源系统接口是至关重要的一步。本文将深入探讨如何通过轻易云数据集成平台调用钉钉接口topapi/processinstance/get,获取并加工数据。
接口概述
钉钉接口topapi/processinstance/get用于获取审批实例的详细信息。该接口采用POST请求方式,支持分页查询,能够返回指定时间范围内的审批实例数据。以下是该接口的主要参数配置:
- api:
topapi/processinstance/get - method:
POST - number:
business_id - id:
单据编号 - idCheck:
true - condition:
[[{"field":"extend.status","logic":"eq","value":"COMPLETED"}]]
请求参数配置
根据元数据配置,我们需要设置以下请求参数:
-
process_code(审批流的唯一码):
- 类型:string
- 示例值:
PROC-B1959981-2CB9-42E9-A054-A975492A5DBB
-
start_time(审批实例开始时间,Unix时间戳,单位毫秒):
- 类型:string
- 示例值:
{LAST_SYNC_TIME}000
-
end_time(审批实例结束时间,Unix时间戳,单位毫秒):
- 类型:string
- 示例值:
{CURRENT_TIME}000
-
size(分页参数,每页大小,最多传20):
- 类型:string
- 示例值:
20
-
cursor(分页查询的游标,最开始传0,后续传返回参数中的next_cursor值):
- 类型:string
- 示例值:
0
数据请求与清洗
在实际操作中,我们首先需要构建请求体,并调用钉钉API获取原始数据。以下是一个示例请求体:
{
"process_code": "PROC-B1959981-2CB9-42E9-A054-A975492A5DBB",
"start_time": "1633046400000",
"end_time": "1633132800000",
"size": "20",
"cursor": "0"
}调用API后,我们会得到一个包含审批实例详细信息的响应。响应数据可能包含多个字段,但我们只关心特定字段,如审批状态、单据编号等。
数据转换与写入
在获取到原始数据后,需要对其进行清洗和转换,以便写入目标系统。在这个过程中,可以使用轻易云平台提供的数据处理工具,对数据进行过滤、映射和格式化。例如:
-
过滤条件: 根据元数据配置中的条件,只保留审批状态为“COMPLETED”的记录。
-
字段映射与转换: 将原始数据中的字段映射到目标系统所需的字段。例如,将“business_id”映射为“单据编号”。
-
格式化处理: 对日期、金额等字段进行格式化处理,以符合目标系统的要求。
以下是一个示例代码片段,用于处理和转换数据:
def process_data(raw_data):
processed_data = []
for record in raw_data:
if record['status'] == 'COMPLETED':
processed_record = {
'单据编号': record['business_id'],
'审批状态': record['status'],
'开始时间': format_timestamp(record['start_time']),
'结束时间': format_timestamp(record['end_time'])
}
processed_data.append(processed_record)
return processed_data
def format_timestamp(timestamp):
# 将Unix时间戳转换为可读格式
return datetime.fromtimestamp(int(timestamp) / 1000).strftime('%Y-%m-%d %H:%M:%S')通过上述步骤,我们可以实现从钉钉获取审批实例数据,并将其清洗、转换后写入目标系统。这一过程不仅提高了数据处理效率,还确保了数据的一致性和准确性。
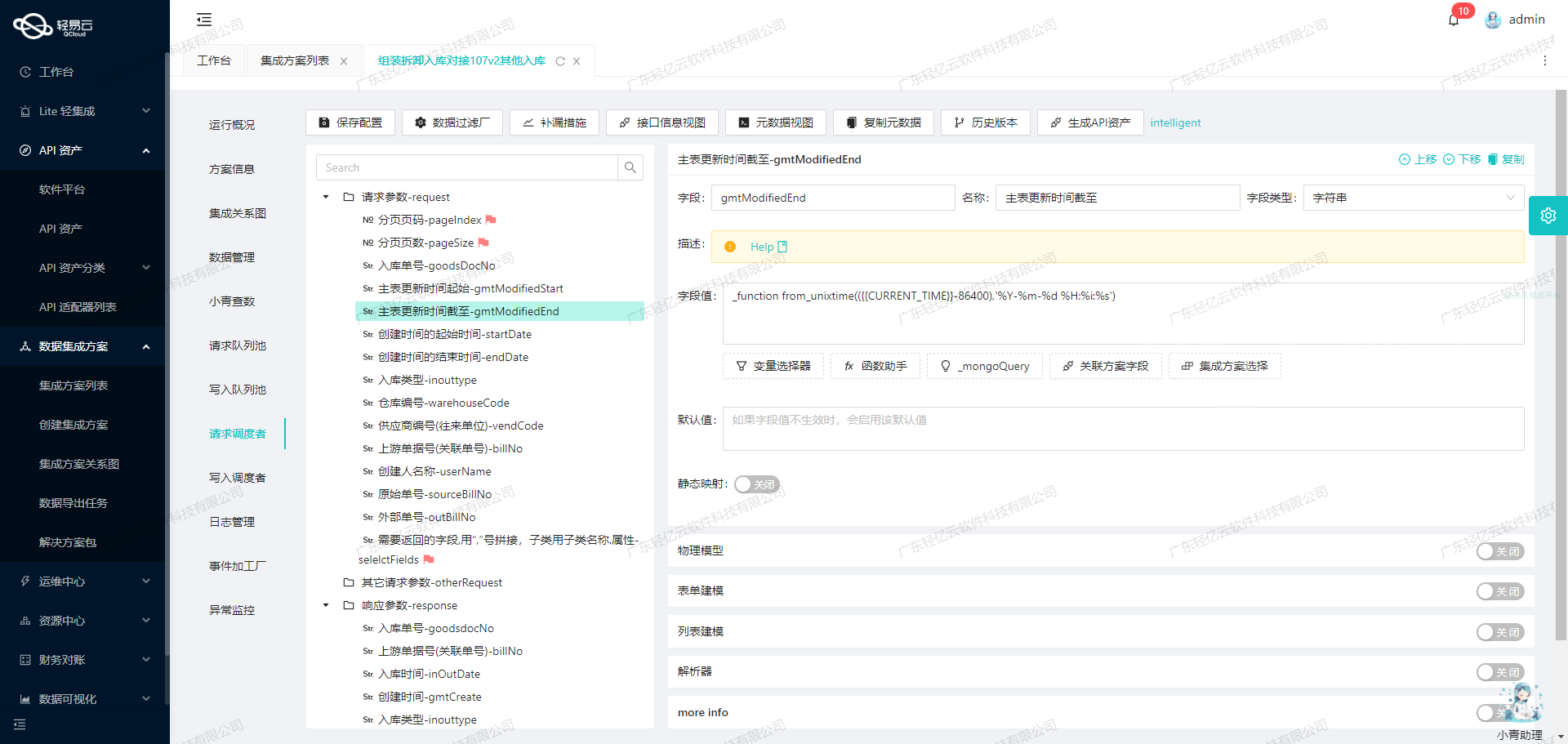
数据集成与ETL转换:将源数据写入金蝶云星空API接口
在数据集成生命周期的第二步,我们需要将已经集成的源平台数据进行ETL(Extract, Transform, Load)转换,转为目标平台——金蝶云星空API接口所能够接收的格式,最终写入目标平台。本文将详细探讨如何利用轻易云数据集成平台配置元数据,实现这一过程。
配置元数据
在进行ETL转换时,首先需要配置好元数据。以下是我们需要使用的元数据配置:
{
"api": "batchSave",
"method": "POST",
"idCheck": true,
"operation": {
"method": "batchArraySave",
"rows": 1,
"rowsKey": "array"
},
"request": [
{
"field": "FID",
"label": "单据编号",
"type": "string",
"describe": "单据编号",
"value": "_findCollection find FID from b91e58dd-b358-385e-a6e9-58ae2b8c37ff where FBillNo={Number}"
},
{
"field": "F_VAOJ_HKSX",
"label": "货款属性",
"type": "string",
"describe": "单据类型",
"value": "_function case '{{货款属性}}' when '成品' then 'CP' else 'FL' end"
},
{
"label": "备注",
"field": "FREMARK",
"type": "string",
"value": "{title}-{{收款人(公司名称)}}-{{备注}}"
},
{
"label": "单据编号",
"field": "FBillNo",
"type": "string",
"value": "{business_id}"
}
],
...
}数据请求与清洗
在这个阶段,我们通过API接口从源系统中获取原始数据,并对其进行初步清洗。具体操作如下:
-
获取单据编号:通过
_findCollection函数,从指定的集合中查找符合条件的单据编号。{ ... { "field":"FID", ... ... ... } } -
货款属性转换:利用
_function函数,根据不同的货款属性值,将其转换为金蝶云星空所需的格式。{ ... { ... ... ... ... } } -
生成备注信息:根据业务需求,将多个字段组合生成备注信息。
{ ... { ... ... ... ... } } -
设置单据编号:直接从业务ID中获取单据编号。
{ ... { ... ... ... ... } }
数据转换与写入
完成数据请求与清洗后,我们进入关键的ETL转换和写入阶段。此时,我们需要将清洗后的数据按照金蝶云星空API接口要求进行转换,并通过API接口将其写入目标系统。
- 配置业务对象表单ID:
{ ..., { ..., ..., ..., ..., ..., ..., ..., ..., ..., ..., ..., ..., ..., ..., ..., ...,
2. **执行批量保存操作**:
```json
{
...,
{
...
3. **自动提交并审核**:
```json
{
...
{
...
4. **验证基础资料有效性**:
```json
{
...
{
...
5. **更新字段列表**:
```json
{
...
{
...
### 实践案例
假设我们有一个付款单,需要将其从源系统迁移到金蝶云星空。在这个过程中,我们会执行以下步骤:
1. 从源系统获取付款单相关信息,包括单据编号、货款属性、备注等。
2. 根据元数据配置,对这些信息进行相应的清洗和转换。例如,将货款属性从“成品”转换为“CP”,其他则为“FL”。
3. 将清洗后的数据通过`batchSave` API接口写入金蝶云星空。
具体实现代码如下:
```python
import requests
# 定义请求头和URL
headers = {'Content-Type': 'application/json'}
url = 'https://api.kingdee.com/k3cloud/Kingdee.BOS.WebApi.ServicesStub.DynamicFormService.BatchSave.common.kdsvc'
# 构建请求体
payload = {
'FormId': 'AP_PAYBILL',
'Operation': 'BatchSave',
'IsAutoSubmitAndAudit': False,
'IsVerifyBaseDataField': False,
'NeedUpDateFields': ['F_VAOJ_HKSX', 'FREMARK', 'FBillNo'],
'Model': [
{
'FID': '_findCollection find FID from b91e58dd-b358-385e-a6e9-58ae2b8c37ff where FBillNo={Number}',
'F_VAOJ_HKSX': '_function case "{{货款属性}}" when \'成品\' then \'CP\' else \'FL\' end',
'FREMARK': '{title}-{{收款人(公司名称)}}-{{备注}}',
'FBillNo': '{business_id}'
}
]
}
# 发起POST请求
response = requests.post(url, headers=headers, json=payload)
# 输出响应结果
print(response.json())通过上述步骤和代码示例,我们可以高效地将源平台的数据经过ETL转换后,成功写入到金蝶云星空系统中。这不仅提高了数据处理效率,还确保了数据的一致性和准确性。