查询VC学年列表对接金蝶学年:技术案例分享
在系统集成的实际项目中,我们经常会遇到需要将不同数据源进行无缝衔接和整合的需求。本次案例即通过美国人vc文档的数据集成到金蝶云星空,实现两大平台间的数据互通,尤其是针对学年信息(VC文档API: /v3/students)与金蝶云星空数据写入接口(batchSave)的数据对接。此项目不仅展示了高效的数据处理能力,还体现了实时监控和异常处理机制,为业务透明化管理提供强有力支持。
首先,在API调用过程中,需要关注以下关键技术要点:
- 高效数据抓取:为确保从美国人vc文档中抓取到最新且准确的学年信息,我们配置了定时任务,通过稳定可靠的调用/v3/students接口,使得数据能够准时进入我们的系统。
- 分页与限流控制:由于/v3/students接口返回的数据量可能较大,该过程采用分页处理,同时结合限流策略,以防止因大量请求导致服务器负载过重,从而影响数据获取效率。
- 批量写入优化:为了实现大量VC文档数据快速且准确地写入到金蝶云星空,batchSave API被设计用于批量提交。这里我们高度依赖于其自定义参数映射功能,确保所有字段都能正确匹配及转换。
- 实时监控及告警机制:整个集成过程中启用轻易云平台提供的集中监控系统,实时追踪每一个环节,包括数据获取、转换、加载等步骤。一旦发现异常情况,如网络故障或接口响应超时,即刻触发告警并执行相应错误重试策略,以减少因为突发问题带来的影响。
此外,为进一步提升项目实施效果,本次应用还特别关注以下几个方面:
- 数据质量检测,全程检查每一次传输过程中的完整性和一致性;
- 可视化设计工具,用于设计复杂多变的数据流逻辑,让开发者一目了然;
- 定制化映射规则,根据具体业务需求,对VC文档和金蝶云星空之间产生的问题进行细致调整,确保最终数据显示符合预期。
本实例不仅展现了一套成熟可行的跨平台联动方案,也给出了具体操作路径,为今后类似需求提供坚实基础。在下篇内容里,我将逐步详细拆解各个过程步骤,并分享更多工程实践经验。
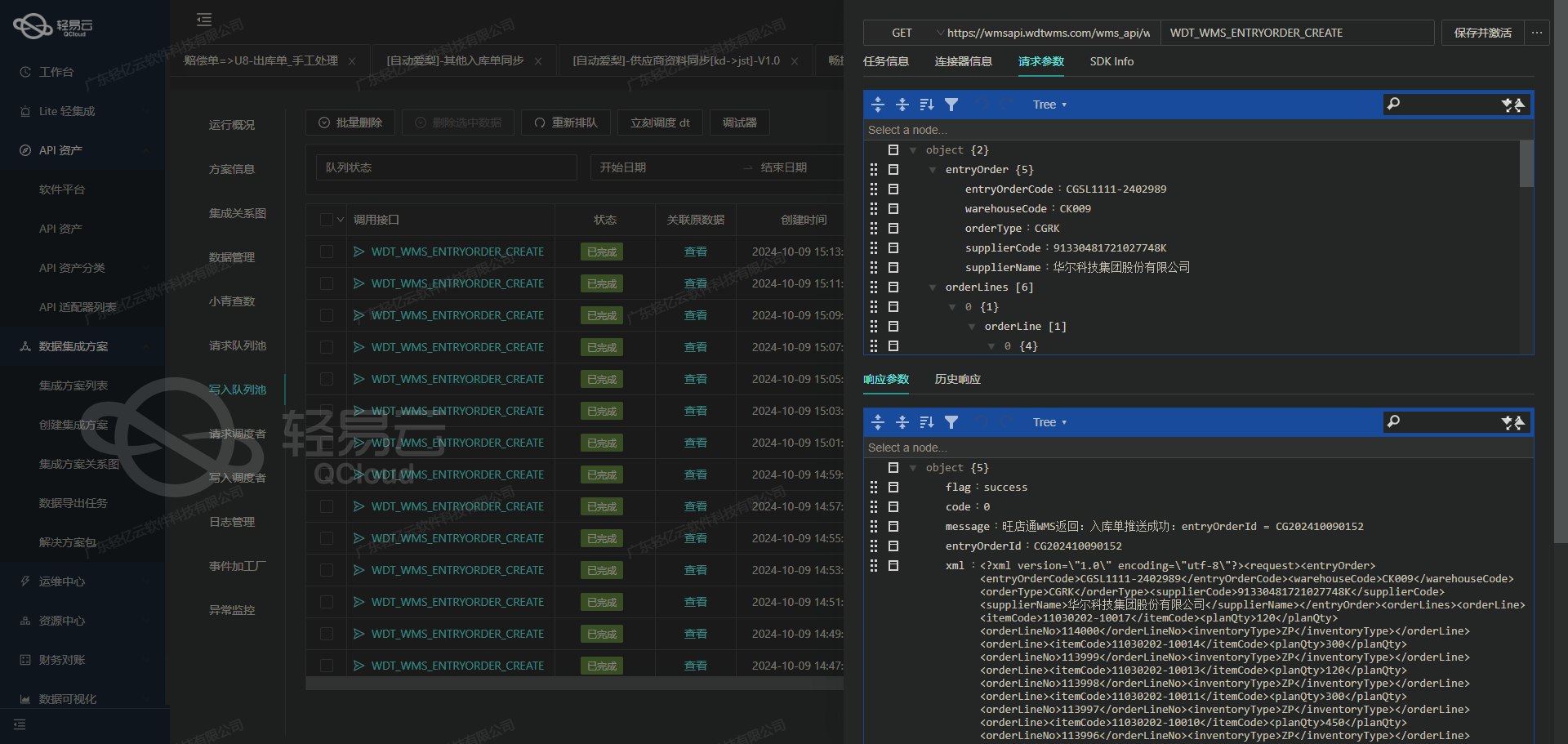
调用源系统美国人vc文档接口/v3/students获取并加工数据
在数据集成生命周期的第一步,我们需要调用源系统的API接口获取原始数据,并对其进行初步加工。本文将详细探讨如何通过轻易云数据集成平台调用美国人vc文档接口/v3/students,获取学生信息并进行必要的数据清洗和转换。
API接口调用配置
首先,我们需要配置API接口的元数据,以便轻易云平台能够正确地调用该接口。根据提供的元数据配置,我们可以看到以下关键信息:
- API路径:
/v3/students - 请求方法:
GET - 分页参数:
X-Page-Size: 每页记录数,设置为1000X-Page-Number: 页码,设置为1
这些参数确保我们能够一次性获取大量数据,并且可以通过分页机制获取所有学生信息。
配置示例
在轻易云平台上,我们需要按照以下步骤配置API调用:
-
定义API路径和请求方法:
{ "api": "/v3/students", "method": "GET" } -
设置请求头参数:
{ "request": [ {"field": "X-Page-Size", "label": "X-Page-Size", "type": "string", "value": "1000"}, {"field": "X-Page-Number", "label": "X-Page-Number", "type": "string", "value": "1"} ] } -
自动填充响应:
{ "autoFillResponse": true }
数据清洗与转换
在获取到原始数据后,下一步是对数据进行清洗和转换。根据元数据配置中的字段说明,我们需要关注以下几个字段:
- graduation_year: 毕业年份,用于唯一标识每个学生。
- name: 学生姓名,这里使用了随机生成器
{random}来模拟不同学生的名字。
为了保证数据的一致性和准确性,我们可以进行以下处理:
- 去除重复记录:根据
graduation_year字段去重,确保每个毕业年份只有一条记录。 - 格式化字段值:将
graduation_year转换为标准日期格式(如YYYY-MM-DD),以便后续处理。 - 校验字段值:检查
graduation_year是否为空或无效,如果无效则丢弃该记录。
实际操作示例
假设我们已经成功调用了API并获得了如下JSON响应:
[
{"graduation_year": 2022, "name": "John Doe"},
{"graduation_year": 2023, "name": "Jane Smith"},
{"graduation_year": 2022, "name": "{random}"}
]我们可以通过轻易云平台提供的可视化工具,对这些数据进行清洗和转换。例如:
-
去重操作:
unique_data = {} for record in response_data: if record['graduation_year'] not in unique_data: unique_data[record['graduation_year']] = record cleaned_data = list(unique_data.values()) -
格式化日期:
for record in cleaned_data: record['graduation_year'] = f"{record['graduation_year']}-01-01" -
校验字段值:
valid_data = [record for record in cleaned_data if record['graduation_year']]
经过以上处理后,我们得到了一组干净且格式统一的数据,可以进一步用于其他系统的集成或分析。
总结
通过上述步骤,我们成功地调用了美国人vc文档接口/v3/students,并对返回的数据进行了有效的清洗和转换。这不仅确保了数据的一致性和准确性,还为后续的数据处理奠定了坚实基础。在实际操作中,轻易云平台提供的全透明可视化界面极大简化了这一过程,使得复杂的数据集成任务变得更加直观和高效。
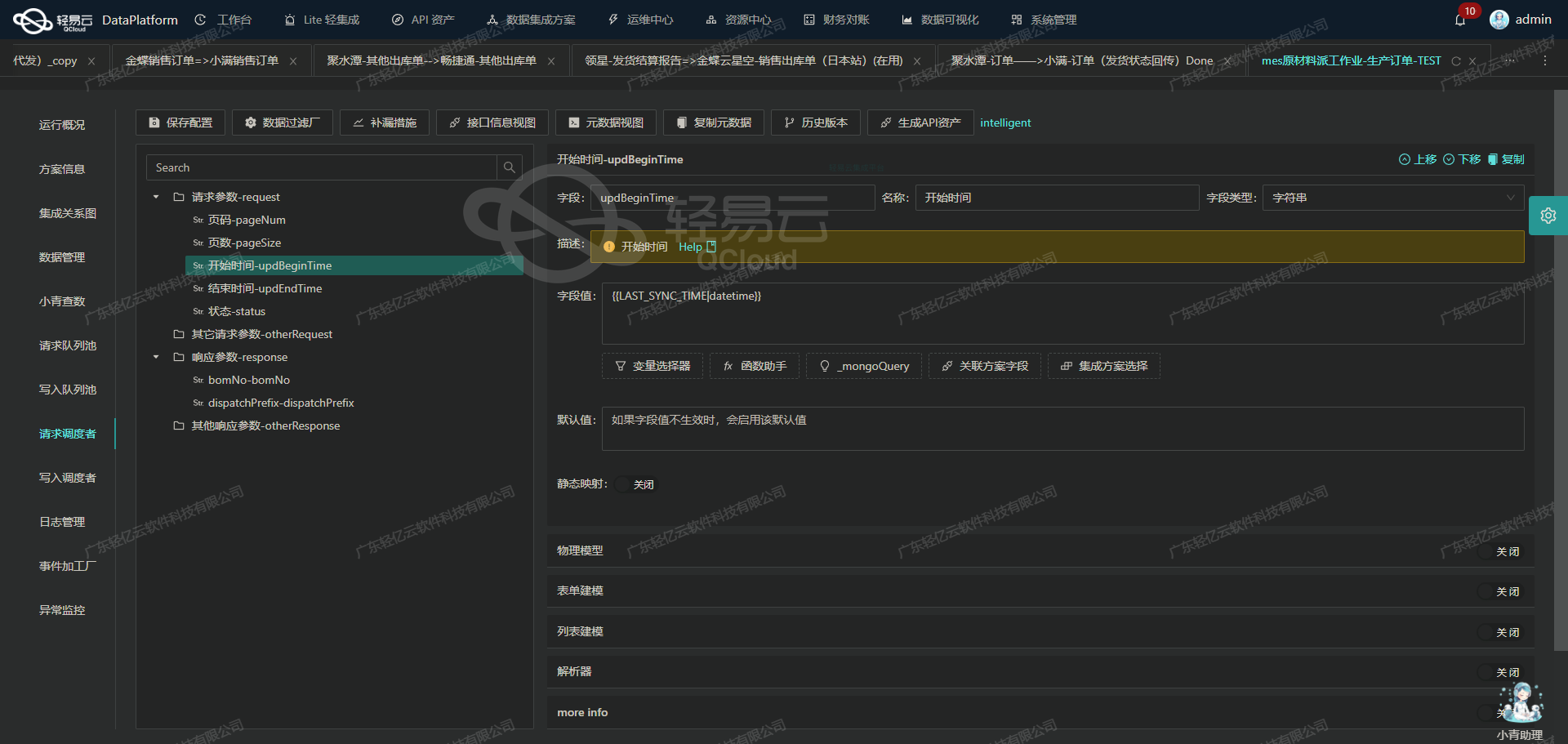
使用轻易云数据集成平台将源平台数据转换并写入金蝶云星空API接口的技术案例
在数据集成生命周期的第二步中,我们需要将已经集成的源平台数据进行ETL转换,并转为目标平台——金蝶云星空API接口所能够接收的格式,最终写入目标平台。以下是详细的技术实现步骤和配置解析。
数据请求与清洗
首先,我们从源系统获取学年列表数据。假设我们已经通过轻易云数据集成平台完成了数据请求与清洗阶段,接下来我们重点关注如何将这些数据转换为金蝶云星空所需的格式,并通过API接口写入目标系统。
配置元数据
我们使用以下元数据配置来定义如何将源数据转换并写入金蝶云星空:
{
"api": "batchSave",
"method": "POST",
"idCheck": true,
"operation": {
"rowsKey": "array",
"rows": 50,
"method": "batchArraySave"
},
"request": [
{
"field": "FCreateOrgId",
"label": "创建组织",
"type": "string",
"parser": {
"name": "ConvertObjectParser",
"params": "FNumber"
},
"value": "102"
},
{
"field": "FUseOrgId",
"label": "使用组织",
"type": "string",
"parser": {
"name": "ConvertObjectParser",
"params": "FNumber"
},
"value": "102"
},
{
"field": "FNumber",
"label": "金蝶组织编码",
"type": "string",
"value": "{graduation_year}"
},
{
"field": "FName",
...数据转换
-
创建组织和使用组织字段:
FCreateOrgId和FUseOrgId字段都需要通过ConvertObjectParser转换器,将其值解析为FNumber格式,固定值为102。 -
金蝶组织编码:
FNumber字段直接取自源数据中的graduation_year字段,无需额外转换。 -
金蝶组织名称:
FName字段需要将graduation_year转换为 JSON 格式,其中包含两个键值对,分别对应语言代码1033和2052。这一步通过ConvertJson转换器实现。 -
描述字段:
FDescription字段在本例中未提供具体值,但可以根据需求进行填充。
API接口调用配置
其他请求参数配置如下:
- 业务对象表单Id (
FormId):固定值为BAS_PreBaseDataFour - 执行的操作 (
Operation):固定值为BatchSave - 提交并审核 (
IsAutoSubmitAndAudit):布尔值true - 验证基础资料 (
IsVerifyBaseDataField):布尔值true
这些参数确保在批量保存操作中,系统会自动提交并审核,同时验证所有基础资料的有效性。
实现批量保存
通过上述配置,我们可以实现批量保存操作。具体步骤如下:
- 将清洗后的学年列表数据按每组50条记录进行分组。
- 调用金蝶云星空的批量保存API接口,将每组记录发送到目标系统。
- 确保每次调用都包含必要的请求参数和转换后的字段值。
以下是一个示例代码片段,用于演示如何通过HTTP POST请求调用API接口:
import requests
import json
url = 'https://api.kingdee.com/batchSave'
headers = {'Content-Type': 'application/json'}
data = {
'FormId': 'BAS_PreBaseDataFour',
'Operation': 'BatchSave',
'IsAutoSubmitAndAudit': True,
'IsVerifyBaseDataField': True,
'Model': [
{
'FCreateOrgId': {'FNumber': '102'},
'FUseOrgId': {'FNumber': '102'},
'FNumber': graduation_year,
'FName': [
{'Key': 1033, 'Value': graduation_year},
{'Key': 2052, 'Value': graduation_year}
],
...
}
for graduation_year in graduation_years_list
]
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
print('Data successfully saved to Kingdee Cloud.')
else:
print('Failed to save data:', response.text)以上代码片段展示了如何构建HTTP POST请求,并将转换后的学年列表数据发送到金蝶云星空API接口,实现批量保存操作。
通过这种方式,我们能够高效地完成从源系统到目标系统的数据ETL转换和写入过程,确保数据的一致性和完整性。