聚水潭盘点单集成到金蝶云星辰V2中的技术方案分享
在数据处理和系统集成的实际应用中,企业往往需要将不同平台间的数据高效、准确地对接,以确保业务流程的畅通无阻。本案例聚焦于如何通过轻易云数据集成平台,将聚水潭系统中的盘点单(API: /open/inventory/count/query)与金蝶云星辰V2中的盘亏单(API: /jdy/v2/scm/inv_check_loss_bill)进行无缝对接,实现跨平台的数据同步。
首先,为了保障大量数据能够快速写入到金蝶云星辰V2,必须充分利用轻易云提供的高吞吐量数据写入能力。这不仅能提升数据处理的时效性,还能从根本上避免因流量限制导致的延迟或丢失。
为了实时掌握整个数据集成任务的状态和性能,我们部署了集中监控和告警系统。该系统能够有效跟踪每一个环节的数据流动情况,并在出现异常时及时发出告警。此外,通过支持自定义的数据转换逻辑,解决了聚水潭与金蝶云星辰V2之间的数据格式差异问题,从而确保两边系统都能顺利解读传输过来的信息。
在具体操作步骤中,首先抓取聚水潭接口上的盘点单数据信息。为了解决分页和限流的问题,我们设计了一套可靠定时抓取机制,以批量方式获取所需数据。同时,通过可视化的数据流设计工具,使得整个过程更加直观且便于管理。
特别值得一提的是,在调用聚水潭API时,我们加入了严格的数据质量监控和异常检测功能。一旦发现异常,不仅会立刻通知相关人员,而且还会自动触发错误重试机制,大大提高了整体对接过程的可靠性。而对于最终写入金蝶云星辰V2 API 的操作,则包含了一系列定制化的数据映射及校验规则,以适应其特有的业务需求和结构要求。
综上所述,本次集成方案不仅实现了两个不同行业应用软件之间的信息互通,更通过多种技术手段确保每一步骤都精准、高效、安全,无疑为复杂业务环境下的信息整合提供了一套成熟且可行的方法。
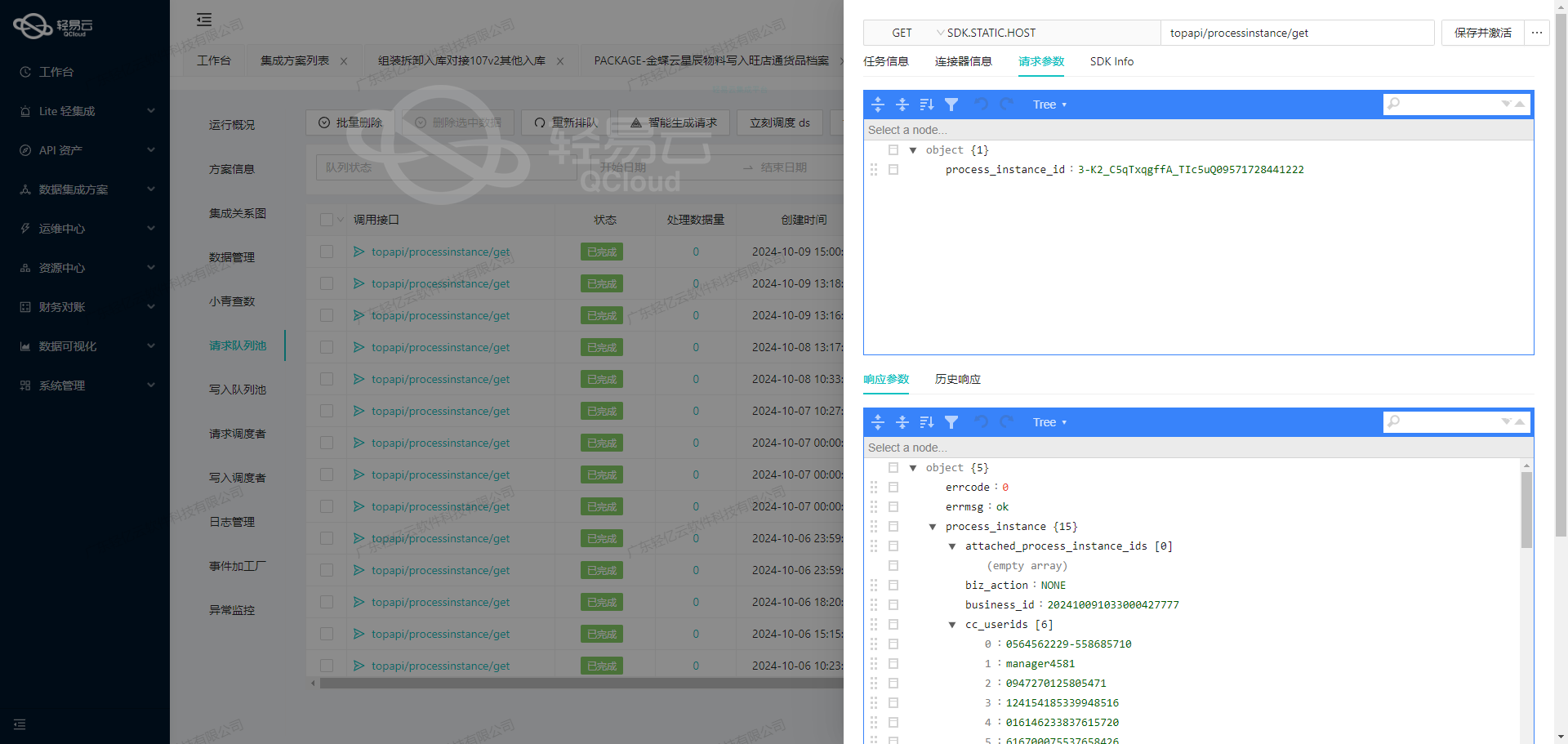
调用聚水潭接口/open/inventory/count/query获取并加工数据
在数据集成生命周期的第一步,我们需要调用聚水潭的接口/open/inventory/count/query来获取盘点单数据,并进行必要的数据加工。以下是详细的技术实现过程和关键配置。
接口调用配置
首先,我们需要配置API调用的元数据。根据提供的元数据配置,我们可以看到该接口使用POST方法进行请求,主要参数如下:
page_index: 页码,从第一页开始,默认值为1。page_size: 每页条数,默认30,最大50。modified_begin: 修改起始时间,与结束时间必须同时存在,时间间隔不能超过七天。modified_end: 修改结束时间,与起始时间必须同时存在。io_ids: 指定盘点单号,多个用逗号分隔,最多50,与时间段不能同时为空。status: 单据状态,默认值为Confirmed。
这些参数确保了我们能够精准地获取到所需的数据。
请求参数设置
在实际调用过程中,我们需要动态设置一些参数,比如modified_begin和modified_end。这两个参数通常会使用系统当前时间和上次同步时间来填充:
{
"page_index": "1",
"page_size": "30",
"modified_begin": "{{LAST_SYNC_TIME|datetime}}",
"modified_end": "{{CURRENT_TIME|datetime}}",
"status": "Confirmed"
}其中,{{LAST_SYNC_TIME|datetime}}和{{CURRENT_TIME|datetime}}是动态变量,用于获取上次同步时间和当前时间。
数据过滤与清洗
根据元数据配置中的条件部分,我们需要对返回的数据进行过滤和清洗。具体条件如下:
items.qty < 0remark not like '包材'
这意味着我们只需要那些数量小于0且备注不包含“包材”的记录。这一步骤可以通过编写过滤逻辑来实现,例如:
def filter_data(data):
return [item for item in data if item['items']['qty'] < 0 and '包材' not in item['remark']]自动填充响应与补救措施
为了确保数据的完整性和连续性,元数据配置中还包含了自动填充响应和遗漏补救机制:
- 自动填充响应:当接口返回的数据不完整时,可以通过自动填充机制补全缺失的数据。
- 遗漏补救:通过定时任务(crontab)定期检查并补救遗漏的数据。例如,每天零点执行一次检查任务:
{
"crontab": "0 0 * * *",
"takeOverRequest": [
{
"field": "modified_begin",
"value": "_function FROM_UNIXTIME( unix_timestamp() -604800 , '%Y-%m-%d %H:%i:%s' )",
"type": "string"
}
]
}这个配置确保了即使某些数据在第一次请求时被遗漏,也能在后续的定时任务中被捕获并处理。
数据转换与写入
在完成数据请求与清洗后,我们需要将处理后的数据转换为目标系统(如星辰盘亏单)所需的格式,并写入目标系统。这一步骤通常涉及到字段映射、格式转换等操作。例如:
def transform_data(data):
transformed_data = []
for item in data:
transformed_item = {
'target_field_1': item['source_field_1'],
'target_field_2': item['source_field_2'],
# 更多字段映射...
}
transformed_data.append(transformed_item)
return transformed_data最后,将转换后的数据通过相应的API接口写入目标系统,实现完整的数据集成流程。
通过以上步骤,我们可以高效地调用聚水潭接口获取盘点单数据,并进行必要的数据加工,为后续的数据集成奠定基础。
将聚水潭盘点单数据转换并写入金蝶云星辰V2
在数据集成的生命周期中,第二步是将已经集成的源平台数据进行ETL转换,并转为目标平台所能够接收的格式。本文将详细探讨如何将聚水潭盘点单数据通过ETL转换,最终写入金蝶云星辰V2 API接口。
元数据配置解析
根据提供的元数据配置,我们需要将聚水潭盘点单的数据转换为金蝶云星辰V2 API接口所需的格式。以下是元数据配置的详细解析:
{
"api": "/jdy/v2/scm/inv_check_loss_bill",
"effect": "EXECUTE",
"method": "POST",
"number": "1",
"id": "1",
"name": "1",
"idCheck": true,
"request": [
{
"field": "bill_date",
"label": "单据日期",
"type": "string",
"describe": "条形码",
"value": "{io_date}"
},
{
"field": "bill_no",
"label": "单据编码",
"type": "string",
"describe": "商品编码,不传递则由后台生成(不设置有编码规则和更新时必传)",
"value": "{io_id}"
},
{
"field": "operation_key",
"label": "操作类型",
"type": "string",
"describe": "规格型号",
"value": "audit"
},
{
...
}
]
}数据字段映射与转换
在这个过程中,我们需要将源平台的数据字段映射到目标平台所需的字段,并进行必要的转换。以下是具体步骤:
-
单据日期(bill_date):将聚水潭盘点单中的
io_date字段映射到金蝶云星辰V2 API中的bill_date字段。 -
单据编码(bill_no):将聚水潭盘点单中的
io_id字段映射到bill_no字段。如果不传递该字段,系统会自动生成。 -
操作类型(operation_key):固定值为
audit,表示审核操作。 -
备注(remark):将聚水潭盘点单中的
remark字段直接映射到目标平台的remark字段。 -
商品分录(material_entity):
- 商品ID(material_id):通过
_findCollection函数从指定集合中查找商品ID。 - 数量(qty):使用
_function abs()函数取绝对值。 - 单位ID(unit_id):通过
_findCollection函数从指定集合中查找单位ID。 - 仓库ID(stock_id):通过
_findCollection函数从指定集合中查找仓库ID。
- 商品ID(material_id):通过
示例代码实现
以下是一个示例代码片段,用于实现上述数据转换和写入操作:
import requests
import json
# 聚水潭盘点单数据
source_data = {
'io_date': '2023-10-01',
'io_id': 'PD123456',
'remark': '月度盘点',
'items': [
{'sku_id': 'SKU001', 'qty': -10},
{'sku_id': 'SKU002', 'qty': -5}
],
'wms_co_id': 'WMS001',
'wh_id': 'WH001'
}
# 转换后的目标平台数据
target_data = {
'bill_date': source_data['io_date'],
'bill_no': source_data['io_id'],
'operation_key': 'audit',
'remark': source_data['remark'],
'material_entity': []
}
for item in source_data['items']:
material_entry = {
'material_id': find_material_id(item['sku_id']),
'qty': abs(item['qty']),
'unit_id': find_unit_id(item['sku_id']),
'stock_id': find_stock_id(source_data['wms_co_id'], source_data['wh_id'])
}
target_data['material_entity'].append(material_entry)
# 将转换后的数据写入目标平台
api_url = '/jdy/v2/scm/inv_check_loss_bill'
headers = {'Content-Type': 'application/json'}
response = requests.post(api_url, headers=headers, data=json.dumps(target_data))
if response.status_code == 200:
print("Data successfully written to the target platform.")
else:
print(f"Failed to write data: {response.text}")
def find_material_id(sku):
# 模拟查找商品ID的函数
return f"material_{sku}"
def find_unit_id(sku):
# 模拟查找单位ID的函数
return f"unit_{sku}"
def find_stock_id(wms_co, wh):
# 模拟查找仓库ID的函数
return f"stock_{wms_co}_{wh}"注意事项
- API请求配置:确保API URL、请求方法、请求头等配置正确无误。
- 错误处理:在实际应用中,需要添加更多错误处理逻辑,以应对可能出现的数据异常或网络问题。
- 性能优化:对于大批量数据处理,可以考虑批量提交或异步处理,以提高效率。
通过以上步骤,我们可以成功地将聚水潭盘点单的数据转换并写入金蝶云星辰V2,实现不同系统间的数据无缝对接。
