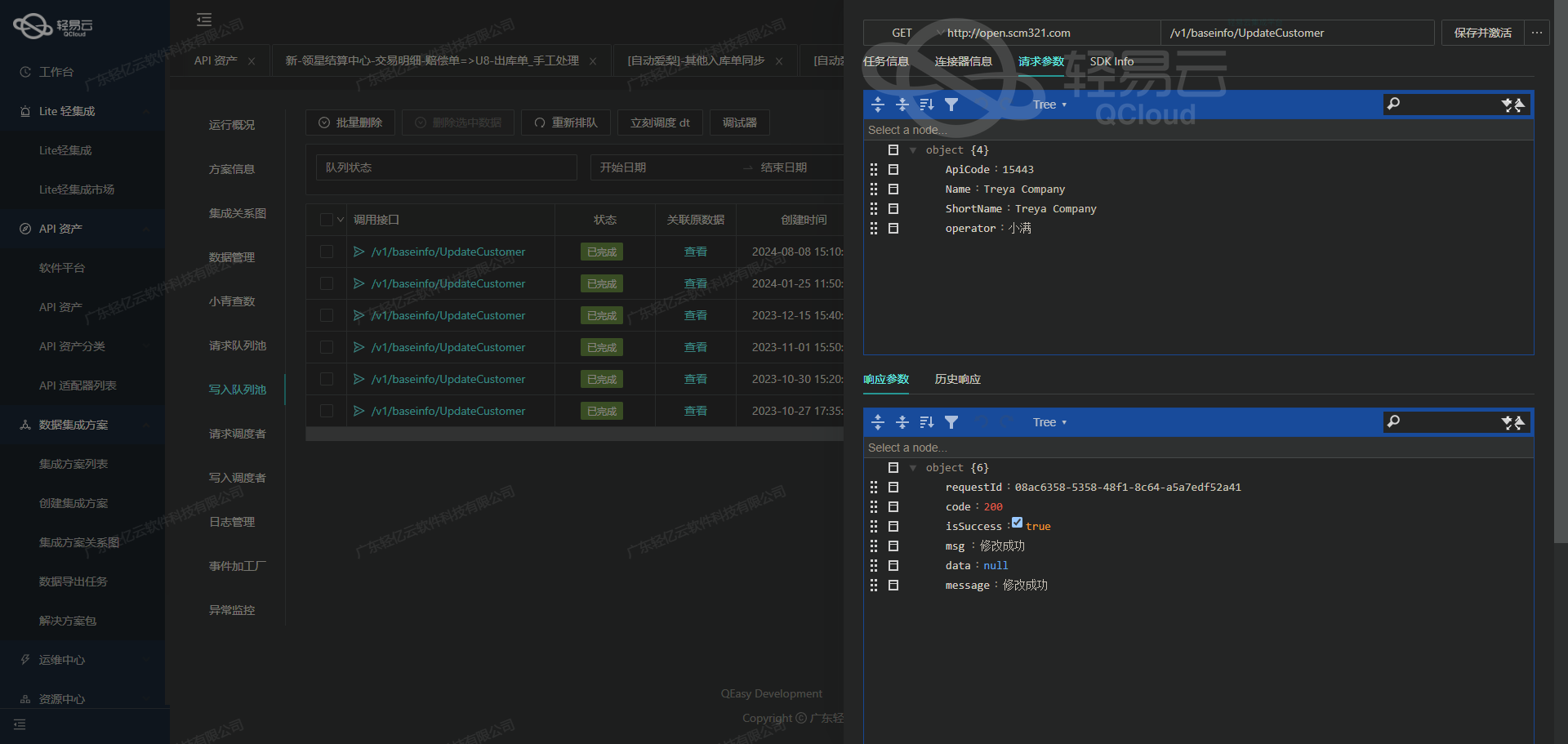
用友BIP数据集成至轻易云平台的技术实现
在这个案例中,我们将探讨如何高效可靠地将用友BIP系统中的采购单据数据集成到轻易云数据集成平台,并确保整个过程中的数据完整性和及时性。具体方案名为"YS采购单查询",通过对接用友BIP的数据接口/yonbip/scm/purchaseorder/list来获取所需信息。
API调用与数据抓取
为了从用友BIP系统中获取最新的采购订单信息,我们使用了API接口/yonbip/scm/purchaseorder/list。该接口支持分页查询,并能够返回符合条件的采购订单列表。在实际操作过程中,需要特别注意分页参数及限流策略,以达到最佳性能而不影响源系统的正常运行。
- 定时任务:我们通过设定一个定时任务,定期调用上述API接口。这不仅能确保及时捕捉到最新的数据变化,还能防止漏单现象发生。
- 异常处理机制:考虑到网络波动或者服务不可达等情况,设计了重试机制。如果首次请求失败,将会以指数退避(Exponential Backoff)算法进行多次重试,以提升成功率。
- 日志记录与监控:对每一次API调用的数据抓取结果进行详细记录,包括时间戳、响应码及核心业务指标,方便后续追溯和问题排查。同时,与实时监控工具联动,实现全程可视化管理,确保每个环节顺利完成。
数据格式转换与写入
不同系统之间往往存在数据结构差异,用友BIP提供的是标准JSON格式,而在写入轻易云平台之前,我们需要进行必要的数据映射和转换。
- 格式差异处理:通过自定义映射规则,将用友BIP输出的JSON字段按照所需格式重新整理。例如,如果源字段名为
purchaseOrderId, 目标字段则可能是po_id。这种一致性的保证,有助于后续的数据分析和利用。 - 批量写入操作: 由于每日产生的大量业务数据,我们采取分片批量写入方式,提高整体处理速度。同时,通过恰当设置并发延迟(如配置最大连接数),避免对目标数据库造成过大压力。
- **错误重试: 在传输过程中,如果出现网络故障或者其他不可预见因素导致部分数据未能成功写入,通过预设的错误检测模块,可以自动触发回滚或补偿事务,再次尝试直到确认所有关键业务条目都已安全存储。
以上步骤涵盖了实现从用友BIP到轻易云平台无缝对接的一
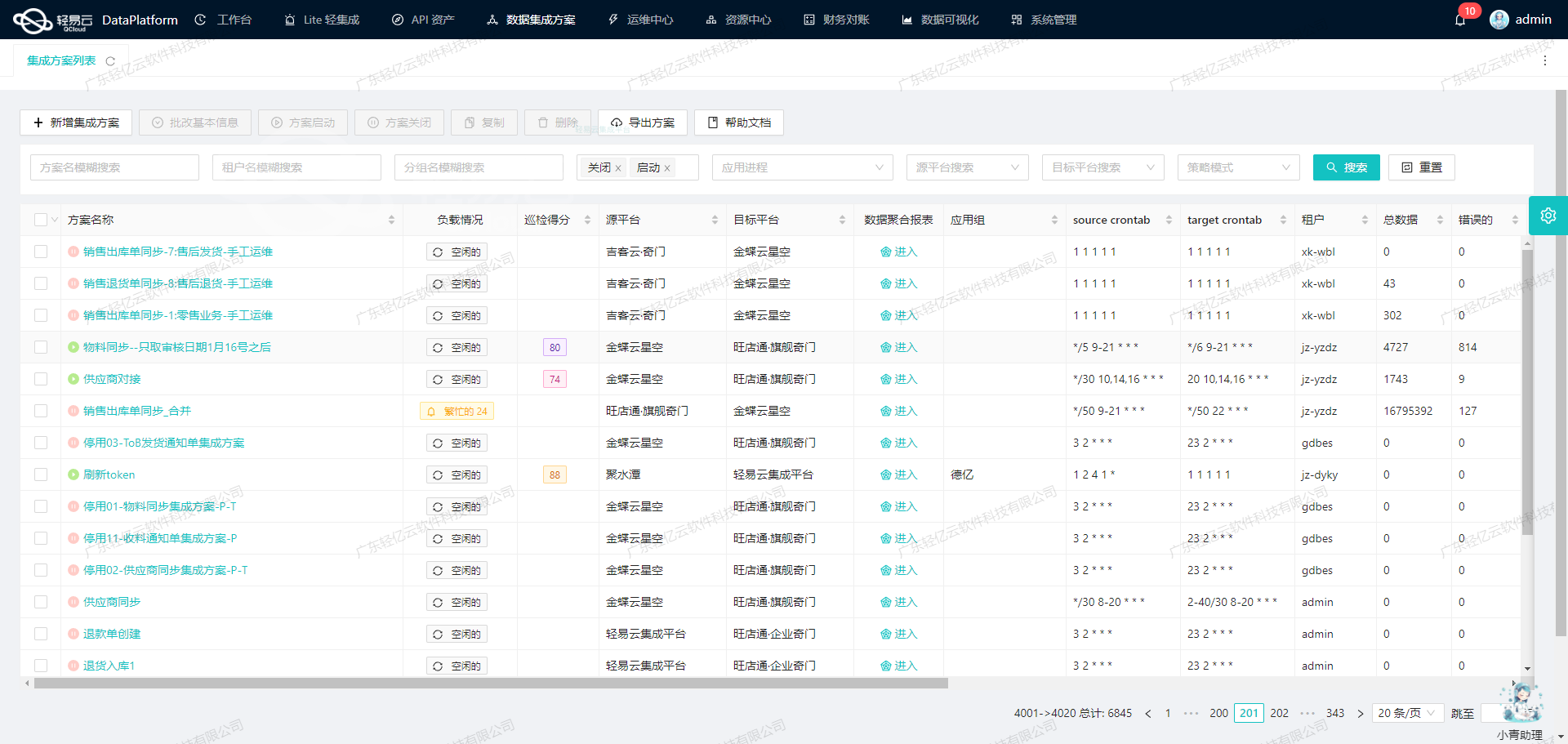
调用用友BIP接口获取并加工数据
在数据集成生命周期的第一步,我们需要调用源系统用友BIP接口/yonbip/scm/purchaseorder/list来获取采购单数据,并对其进行初步加工。本文将详细探讨如何通过轻易云数据集成平台配置元数据,完成这一过程。
接口调用与请求参数配置
首先,我们需要配置API调用的元数据。根据提供的元数据配置,我们使用POST方法调用/yonbip/scm/purchaseorder/list接口。请求参数包括分页信息、查询条件和排序字段。
{
"api": "/yonbip/scm/purchaseorder/list",
"method": "POST",
"request": [
{
"field": "pageIndex",
"label": "页码",
"type": "string",
"describe": "例:1 默认值:1",
"value": "1"
},
{
"field": "pageSize",
"label": "每页数",
"type": "string",
"describe": "例:10 默认值:10",
"value": "1000"
},
{
"field": "isSum",
"label": "查询表头",
"type": "string",
"describe": "例:false 默认值:false"
},
{
"field": "simpleVOs",
"label": "查询条件",
"type": "object",
...
},
{
...
}
]
}在上述配置中,pageIndex和pageSize用于分页控制,默认值分别为1和1000。isSum参数用于指定是否查询表头信息,默认为false。
查询条件与排序字段
查询条件通过simplVOs字段进行配置,其中包含一个过滤条件:
{
...
{
"field":"simpleVOs",
...
{
...
{
...
{
...
{
...
{
...
{
...
{
...
{
...
{
...
{"field":"value1","label":"值1","type":"string","describe":"“and” | “or” | “and not” | “or\nnot”,若设置,必填expr1和expr2属性,忽略\ncolumn和condition。","value":"{{LAST_SYNC_TIME|datetime}}","parent":"params"}
}
}
}
}
}
}
}
}
}
},
...
}该过滤条件用于筛选出最近同步时间之后的数据,确保我们获取到最新的采购单信息。
排序字段通过queryOrders字段进行配置:
{
...
{
...
{"field":"queryOrders","label":"排序字段","type":"array","children":[{"field":"field","label":"排序条件字段","type":"string","describe":"必须传实体上有的字段;主表字段查询时字段名(例: id);子表字段查询是子表对象.字段名(例:purchaseOrders.id);参照类型只能传id(例:按物料查询只能传物料id,不能传物料code) 例:id","value":"id","parent":"queryOrders"},{"field":"order","label":"顺序","type":"string","describe":"正序(asc);倒序(desc) 例:asc","value":"asc","parent":"queryOrders"}]}
},
...
}这里我们指定按ID进行升序排列,以确保数据的有序性。
数据格式化与转换
在获取到原始数据后,我们需要对其进行格式化和转换,以便后续处理。在元数据配置中,通过formatResponse字段定义了具体的转换规则:
{
...
{"old":"id","new":"new_id","format":"string"},
{"old":"purchaseOrders_id","new":"new_purchaseOrders_id","format":"string"},
{"old":"headFreeItem.define1","new":"new_headFreeItem","format":"string"},
{"old":"vendor","new":"new_vendor","format":"string"},
{"old":"warehouse","new":"new_warehouse","format":"string"}
}这些规则将原始数据中的特定字段重命名并转换为字符串格式。例如,将原始ID字段重命名为new_id,并将其格式化为字符串。这一步骤确保了数据的一致性和可读性,为后续的数据处理奠定基础。
实践案例
以下是一个实际调用用友BIP接口并处理返回数据的示例代码片段:
import requests
import json
# 定义API URL
url = 'https://api.yonyou.com/yonbip/scm/purchaseorder/list'
# 请求参数
payload = json.dumps({
'pageIndex': '1',
'pageSize': '1000',
'isSum': 'false',
'simpleVOs': [{
'field': 'pubts',
'op': 'egt',
'value1': '{{LAST_SYNC_TIME|datetime}}'
}],
'queryOrders': [{
'field': 'id',
'order': 'asc'
}]
})
# 设置请求头
headers = {'Content-Type': 'application/json'}
# 发起POST请求
response = requests.post(url, headers=headers, data=payload)
# 检查响应状态码
if response.status_code == 200:
data = response.json()
# 格式化响应数据
formatted_data = []
for item in data['data']:
formatted_item = {
'new_id': str(item['id']),
'new_purchaseOrders_id': str(item['purchaseOrders_id']),
'new_headFreeItem': str(item['headFreeItem']['define1']),
'new_vendor': str(item['vendor']),
'new_warehouse': str(item['warehouse'])
}
formatted_data.append(formatted_item)
# 输出格式化后的数据
print(json.dumps(formatted_data, indent=4))
else:
print(f"Error: {response.status_code}")该示例展示了如何通过Python脚本调用用友BIP接口,并对返回的数据进行格式化处理。首先构建请求参数,然后发起POST请求获取响应数据,最后根据预定义的格式化规则对响应数据进行处理并输出结果。
通过上述步骤,我们成功实现了从用友BIP系统获取采购单列表并进行初步加工,为后续的数据集成和分析打下坚实基础。这一过程充分体现了轻易云数据集成平台在异构系统间无缝对接和高效处理方面的优势。
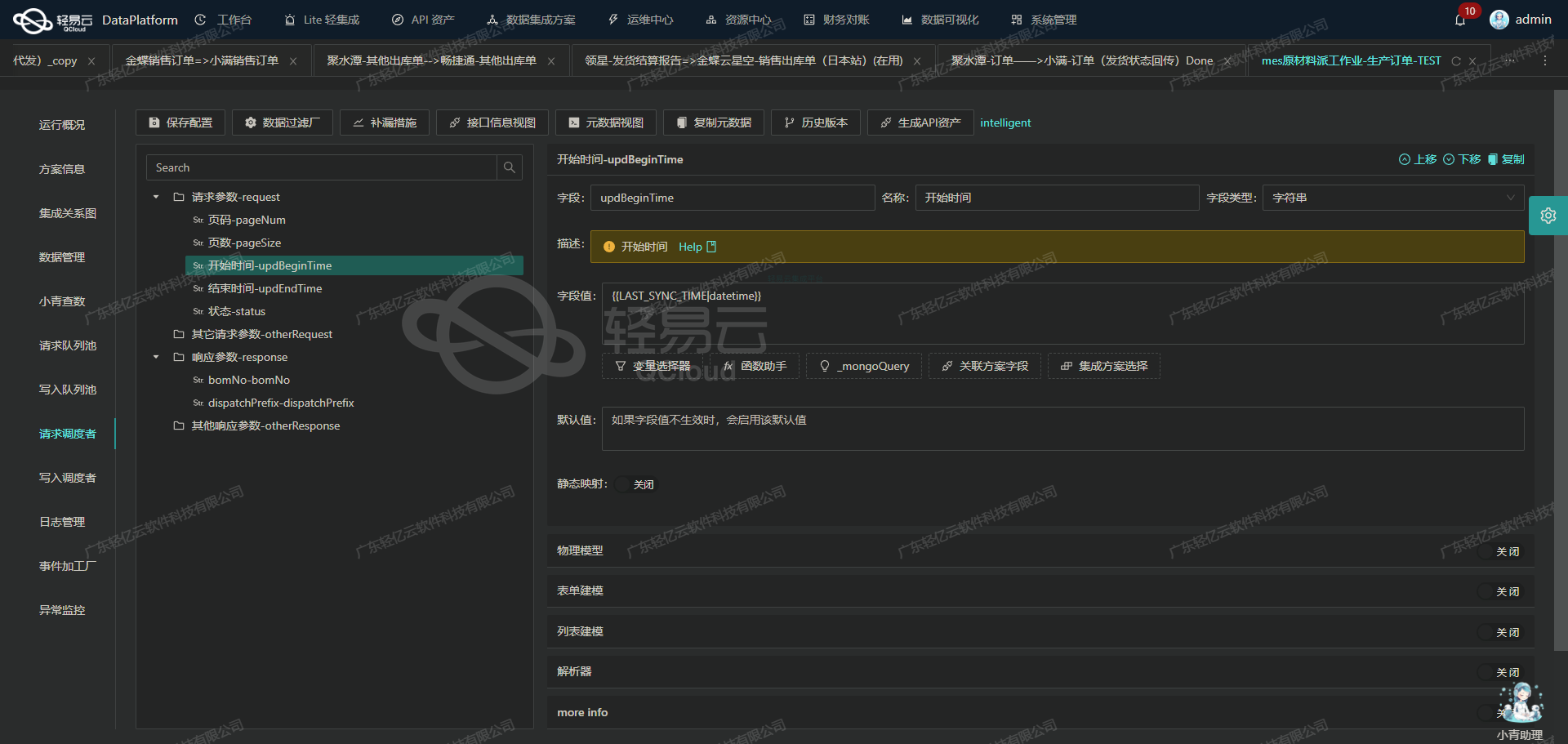
轻易云数据集成平台ETL转换与写入技术案例
在轻易云数据集成平台的生命周期中,数据请求与清洗完成后,接下来需要进行ETL转换,将数据转为目标平台所能接收的格式,并最终写入目标平台。本文将深入探讨这一过程中涉及的技术细节,特别是如何利用API接口进行高效的数据写入。
数据转换与API接口配置
在数据集成过程中,数据转换是一个关键环节。首先,我们需要确保从源系统获取的数据经过清洗和标准化处理,符合目标平台的要求。接下来,我们利用轻易云集成平台提供的API接口,将这些数据写入目标系统。
以下是一个典型的元数据配置示例:
{
"api": "写入空操作",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true
}这个配置表明,我们将使用POST方法调用写入空操作API,并且在执行前会进行ID检查(idCheck: true)。
数据转换步骤
-
数据标准化:首先,将源系统的数据进行标准化处理。例如,将日期格式统一为ISO 8601标准,将货币单位统一为美元等。这一步确保了不同来源的数据具有一致性。
-
字段映射:根据目标平台的要求,对源系统的数据字段进行映射。例如,源系统中的
order_id可能需要映射为目标系统中的purchase_order_id。 -
格式转换:将数据转换为目标平台所需的格式。例如,JSON、XML等。轻易云集成平台支持多种格式的转换,可以根据具体需求进行配置。
API接口调用
在完成数据转换后,需要通过API接口将数据写入目标平台。以下是一个示例代码片段,展示了如何使用Python调用上述API接口:
import requests
import json
# API URL
url = "https://api.example.com/write"
# Headers
headers = {
"Content-Type": "application/json"
}
# Data payload
data = {
"purchase_order_id": "12345",
"amount": 1000,
"currency": "USD",
"date": "2023-10-01T12:00:00Z"
}
# ID Check (if needed)
def id_check(data):
# Implement ID check logic here
return True
if id_check(data):
# Make POST request to API
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
print("Data written successfully")
else:
print(f"Failed to write data: {response.status_code}")
else:
print("ID check failed")实时监控与错误处理
为了确保数据集成过程的可靠性和透明度,实时监控和错误处理是必不可少的。在轻易云集成平台中,可以设置实时监控机制,对每个API调用进行日志记录和状态跟踪。一旦出现错误,可以快速定位并解决问题。
例如,可以通过以下方式实现简单的错误处理:
try:
response = requests.post(url, headers=headers, data=json.dumps(data))
response.raise_for_status()
except requests.exceptions.HTTPError as errh:
print(f"HTTP Error: {errh}")
except requests.exceptions.ConnectionError as errc:
print(f"Error Connecting: {errc}")
except requests.exceptions.Timeout as errt:
print(f"Timeout Error: {errt}")
except requests.exceptions.RequestException as err:
print(f"OOps: Something Else {err}")通过以上步骤,我们可以高效地将已经集成的源平台数据进行ETL转换,并通过API接口将其写入目标平台。这样不仅保证了数据的一致性和完整性,还提高了整个数据处理过程的透明度和效率。