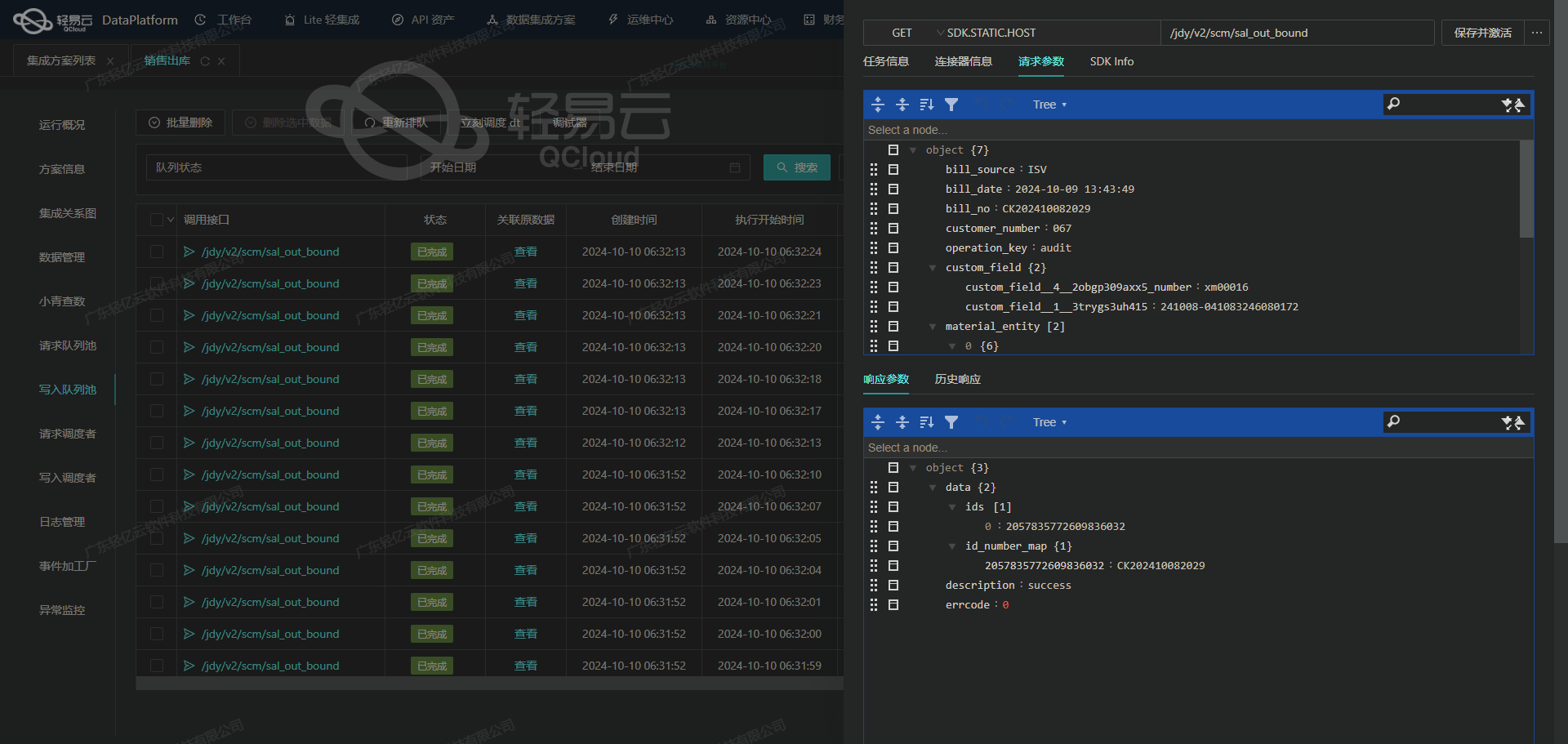
星辰商品查询:金蝶云星辰V2数据集成到轻易云平台
在某大型零售企业的信息系统优化项目中,我们面对的一个核心需求是将其使用的金蝶云星辰V2平台中的商品信息高效集成到轻易云数据集成平台,从而实现对商品数据的集中管理和快速查询。为了满足这一需求,我们设计并实施了名为“星辰商品查询”的方案,重点解决了多种技术挑战,包括如何确保集成过程中不漏单、大量数据的快速写入、定时可靠的数据抓取以及异常处理与错误重试机制。
首先,通过调用金蝶云星辰V2的数据接口/jdy/v2/bd/material,我们能够获取到最新的商品资料。在这个过程中,为避免因接口限流导致的数据丢失问题,我们采取了分页抓取策略,并结合轻易云自带的实时监控和日志记录功能,全程观察每一次请求及其响应状态。
其次,为应对两大系统间可能存在的数据格式差异问题,我们利用轻易云平台提供的定制化数据映射功能,对从金蝶云星辰V2获取的数据进行适配转换,使之符合目标数据库结构要求。这样不仅简化了后续处理流程,还保证了数据的一致性和完整性。
对于批量写入部分,由于需要频繁访问外部API且存在较大的迸发式请求压力,我们特别配置了一套异步调用与缓存队列相结合的数据传输机制,有效提升了大量数据从金蝶同步至轻易云平台过程中的速度和可靠性。同时,通过设置周期性的定时任务,将这些操作自动化,实现持续稳定地更新数据库内容。
以上只是我们在“星辰商品查询”方案中所采用的一部分关键技术点,这些实践不仅成功解决了一系列具体问题,也为类似场景下的数据整合提供了宝贵经验。接下来将详细介绍各个环节中的实现步骤及注意事项,以供借鉴。
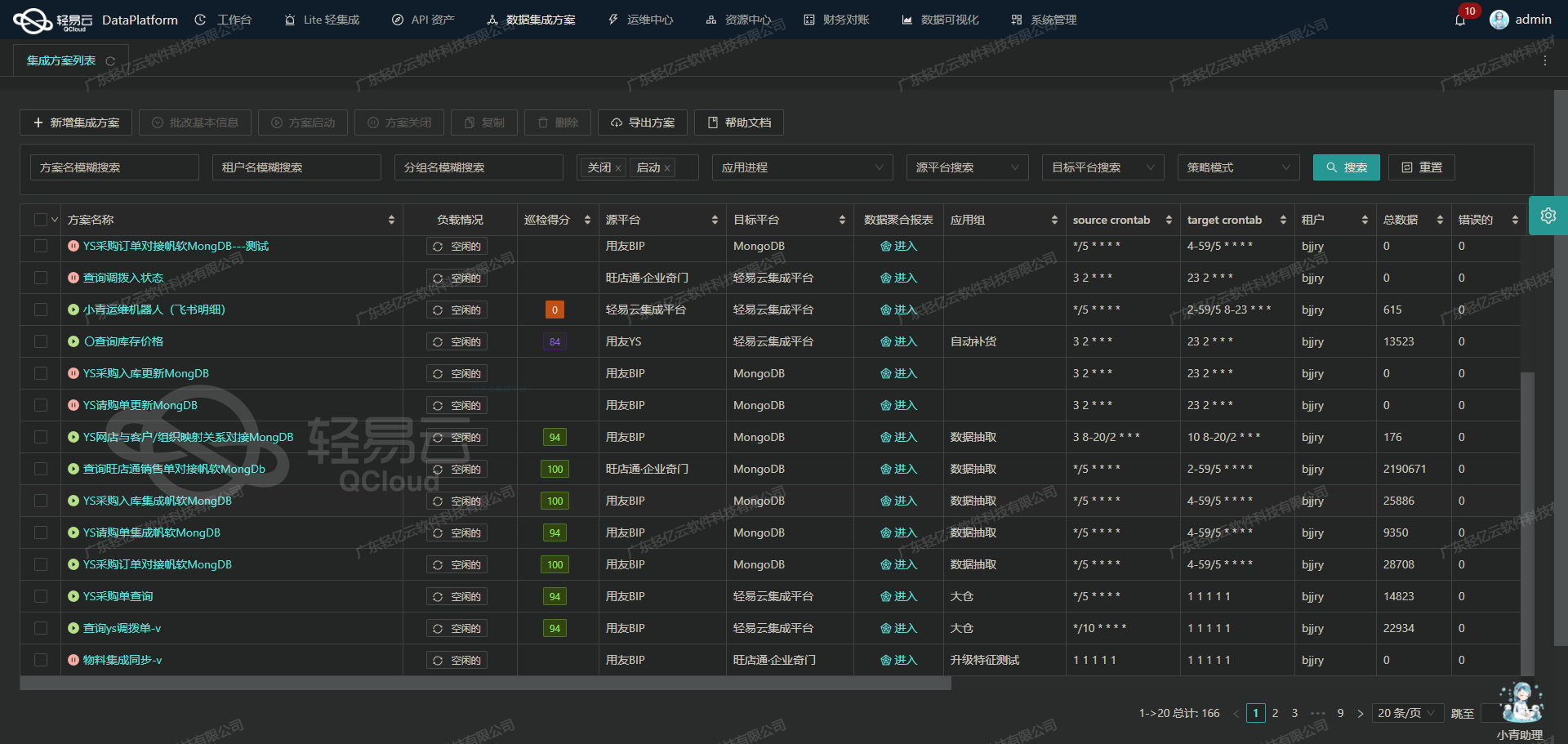
调用金蝶云星辰V2接口获取并加工数据的技术实现
在轻易云数据集成平台中,调用金蝶云星辰V2接口 /jdy/v2/bd/material 是数据集成生命周期的第一步。本文将详细探讨如何通过该接口获取商品数据,并进行必要的数据清洗和加工。
接口配置与请求参数
首先,我们需要理解接口的基本配置和请求参数。根据元数据配置,接口为 /jdy/v2/bd/material,采用 GET 方法进行查询操作。以下是请求参数的详细说明:
modify_end_time: 数据修改结束时间,格式为字符串,值为当前时间戳(精确到毫秒)。modify_start_time: 数据修改开始时间,格式为字符串,值为上次同步时间戳(精确到毫秒)。page: 页码,默认为1。page_size: 每页记录数,默认为20。
示例请求参数如下:
{
"modify_end_time": "20231010120000000",
"modify_start_time": "20231009120000000",
"page": "1",
"page_size": "20"
}数据请求与清洗
在发起请求后,我们将获得一组商品数据。为了确保数据质量,需要对返回的数据进行清洗和加工。以下是常见的数据清洗步骤:
- 字段校验:确保每个商品记录包含必要的字段,如
number、id和name。 - 数据格式化:将日期、时间等字段转换为标准格式,以便后续处理。
- 去重处理:移除重复的商品记录。
示例代码片段:
import requests
import json
# 定义请求URL和参数
url = "https://api.kingdee.com/jdy/v2/bd/material"
params = {
"modify_end_time": "20231010120000000",
"modify_start_time": "20231009120000000",
"page": "1",
"page_size": "20"
}
# 发起GET请求
response = requests.get(url, params=params)
data = response.json()
# 数据清洗
cleaned_data = []
for item in data['items']:
if 'number' in item and 'id' in item and 'name' in item:
cleaned_item = {
'number': item['number'],
'id': item['id'],
'name': item['name'],
# 格式化日期等其他处理
}
cleaned_data.append(cleaned_item)
# 去重处理
unique_data = {item['id']: item for item in cleaned_data}.values()数据转换与写入
在完成数据清洗后,需要将数据转换为目标系统所需的格式,并写入目标数据库或系统。这一步通常涉及以下操作:
- 字段映射:将源系统字段映射到目标系统字段。
- 数据类型转换:确保所有字段的数据类型符合目标系统要求。
- 批量写入:提高写入效率,减少网络开销。
示例代码片段:
# 假设目标系统需要的字段名不同
mapped_data = []
for item in unique_data:
mapped_item = {
'product_code': item['number'],
'product_id': item['id'],
'product_name': item['name']
}
mapped_data.append(mapped_item)
# 批量写入目标数据库(假设使用SQLAlchemy)
from sqlalchemy import create_engine, Table, MetaData
engine = create_engine('mysql+pymysql://user:password@host/db')
metadata = MetaData(bind=engine)
table = Table('products', metadata, autoload=True)
with engine.connect() as conn:
conn.execute(table.insert(), mapped_data)通过上述步骤,我们可以高效地从金蝶云星辰V2接口获取商品数据,并进行必要的数据清洗、转换和写入操作。这不仅确保了数据的一致性和完整性,还极大提升了业务流程的自动化程度。

数据集成生命周期中的ETL转换与写入
在数据集成的生命周期中,ETL(Extract, Transform, Load)过程是关键的一环。本文将深入探讨如何使用轻易云数据集成平台,将已经集成的源平台数据进行ETL转换,并最终写入目标平台。我们将重点关注API接口的技术细节和元数据配置。
数据请求与清洗
在开始ETL转换之前,首先需要完成数据请求与清洗。这一步骤确保了从源平台获取的数据是准确且符合预期的。假设我们已经完成了这一阶段,并且得到了干净的数据集。
数据转换
接下来,我们进入数据转换阶段。在这个阶段,我们需要将源平台的数据格式转换为目标平台所能接收的格式。根据提供的元数据配置,目标平台要求的数据格式如下:
{
"api": "写入空操作",
"effect": "EXECUTE",
"method": "POST",
"number": "number",
"id": "id",
"name": "编码",
"idCheck": true
}这意味着我们需要确保每个数据记录包含以下字段:
number: 数字类型,用于表示商品编号。id: 唯一标识符,用于标识每个商品。name: 商品名称,对应编码字段。idCheck: 布尔类型,用于检查ID是否存在。
假设我们从源平台获取到的数据如下:
[
{"商品编号": 1001, "唯一标识符": 1, "商品名称": "商品A"},
{"商品编号": 1002, "唯一标识符": 2, "商品名称": "商品B"}
]我们需要将其转换为目标平台所需的格式:
[
{"number": 1001, "id": 1, "name": "商品A", "idCheck": true},
{"number": 1002, "id": 2, "name": "商品B", "idCheck": true}
]数据写入
完成数据转换后,我们需要将其写入目标平台。根据元数据配置,目标平台使用POST方法,通过API接口写入空操作来接收数据。
以下是一个示例代码片段,展示了如何使用Python进行API调用,将转换后的数据写入目标平台:
import requests
import json
# 转换后的数据
data = [
{"number": 1001, "id": 1, "name": "商品A", "idCheck": True},
{"number": 1002, "id": 2, "name": "商品B", "idCheck": True}
]
# API接口URL
url = 'https://api.qingyiyun.com/execute'
# 请求头信息
headers = {
'Content-Type': 'application/json'
}
# 发起POST请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 检查响应状态码
if response.status_code == 200:
print("数据成功写入目标平台")
else:
print(f"写入失败,状态码: {response.status_code}")在上述代码中,我们首先定义了转换后的数据,然后通过requests.post方法将其发送到目标平台的API接口。请求头信息中指定了内容类型为application/json。最后,通过检查响应状态码来确认数据是否成功写入。
技术要点总结
- 元数据配置:理解并正确应用元数据配置是确保成功集成的关键。本文中的配置要求我们提供特定字段,并进行ID检查。
- API接口调用:通过HTTP POST方法,将经过ETL转换后的数据发送到目标平台。确保请求头和请求体格式正确,以满足API接口要求。
- 错误处理:在实际应用中,需要添加更多的错误处理机制,例如重试逻辑、日志记录等,以提高系统的健壮性和可靠性。
通过以上步骤,我们能够高效地完成从源平台到目标平台的数据集成过程,实现不同系统间的数据无缝对接。这不仅提升了业务透明度和效率,也确保了数据处理过程的全生命周期管理。