MSSQL-demo: SQL Server到SQL Server的数据集成案例
在数据驱动的业务环境中,确保数据流动的高效性和准确性是企业成功的关键。本文将探讨一个具体的系统对接集成案例:如何通过MSSQL-demo方案实现SQL Server到SQL Server的数据集成。
MSSQL-demo方案充分利用了轻易云数据集成平台的多项特性,以确保数据在两个SQL Server实例之间无缝传输。首先,该方案支持高吞吐量的数据写入能力,使得大量数据能够快速被集成到目标SQL Server系统中,极大提升了数据处理的时效性。此外,通过提供可视化的数据流设计工具,用户可以直观地管理和优化整个数据集成过程。
为了保证数据质量和任务稳定性,MSSQL-demo还引入了实时监控与告警系统。这一功能不仅能实时跟踪每个数据集成任务的状态,还能及时发现并处理潜在异常,从而降低因错误导致的数据丢失风险。同时,通过自定义数据转换逻辑,该方案能够适应不同业务需求和复杂的数据结构,实现更为灵活的数据映射。
在API接口层面,MSSQL-demo方案采用select API从源SQL Server获取数据,并使用insert API将其写入目标SQL Server。在此过程中,特别注意处理分页和限流问题,以确保接口调用的效率与可靠性。此外,为应对可能出现的对接异常,该方案设计了完善的错误重试机制,以保障任务执行的一致性。
通过这些技术手段,MSSQL-demo不仅实现了高效、可靠的数据对接,还为企业提供了一种可持续优化的数据管理模式。后续章节将详细介绍该方案中的具体实施步骤及最佳实践。
调用SQL Server接口进行数据获取与加工处理
在轻易云数据集成平台的生命周期中,调用源系统SQL Server接口以获取并加工数据是至关重要的一步。通过配置元数据,我们可以高效地实现这一过程。
首先,利用API接口select来从SQL Server中提取数据。该接口采用POST方法进行请求,并支持分页机制,以确保在处理大量数据时能够保持稳定性和效率。在元数据配置中,我们定义了一个分页参数pageSize为100,这意味着每次请求将获取100条记录。这种分页策略不仅提高了吞吐量,还有效避免了单次请求过多导致的性能瓶颈。
为了确保数据不漏单,我们启用了idCheck功能,通过检查唯一标识符字段id来保证每条记录都被准确抓取。此外,使用参数化查询进一步增强了灵活性。例如,在我们的配置中,字段updated_at用于动态筛选最近更新的数据,其值通过模板变量{{LAST_SYNC_TIME|datetime}}自动填充。这种动态参数化设计使得我们能够定时可靠地抓取最新的数据,而无需手动调整查询条件。
在调用SQL Server接口时,需要特别注意处理分页和限流问题。通过合理设置分页大小和请求频率,可以有效控制对数据库的压力,避免影响其他业务操作。同时,为应对可能出现的异常情况,我们设计了错误重试机制。一旦检测到请求失败或超时,将自动触发重试逻辑,以确保任务的连续性和完整性。
此外,对于不同系统间的数据格式差异,我们提供了自定义数据转换逻辑。用户可以根据特定业务需求,对接收到的数据进行格式转换和映射,从而实现与目标系统的无缝对接。这种灵活性极大地提升了集成方案的适应能力,使其能够满足各种复杂场景下的数据处理要求。
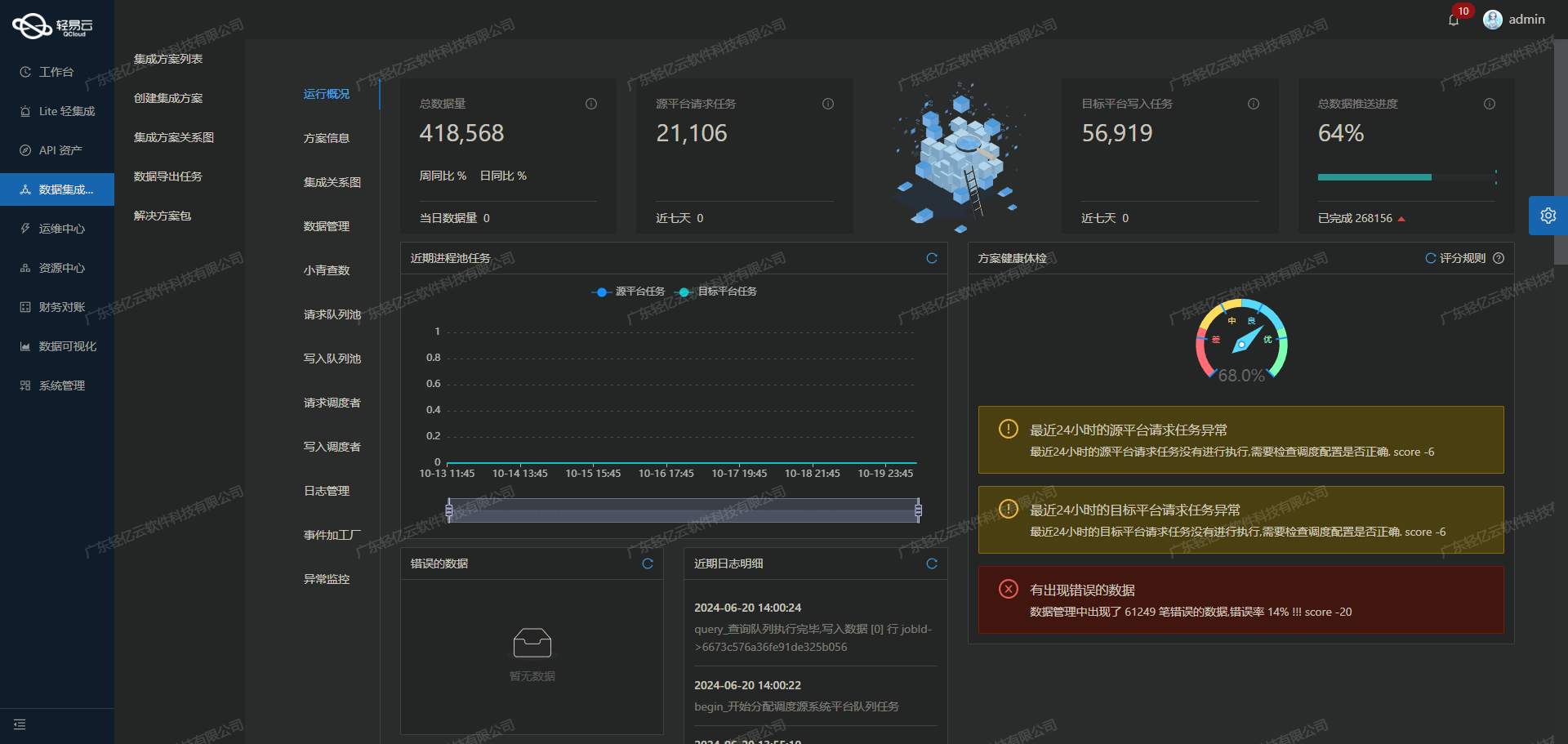
实时监控与日志记录也是不可或缺的一部分。在整个集成过程中,通过集中监控系统,可以实时跟踪任务状态及性能指标。一旦发现异常情况,系统会及时告警并记录详细日志,为后续分析和优化提供依据。这种透明化管理不仅提高了运维效率,也保障了数据处理过程的安全性和可靠性。
综上所述,通过精细化配置元数据以及充分利用轻易云平台提供的技术特性,我们能够高效、稳定地完成SQL Server接口的数据获取与加工处理任务,实现不同系统间的数据无缝集成。
数据集成中的ETL转换与SQL ServerAPI接口对接
在数据集成过程中,将源平台的数据转化为目标平台能够接收的格式是关键的一步。本文将聚焦于如何通过ETL过程将数据转换为SQL ServerAPI接口能够处理的格式,并最终写入到SQL Server中。
在元数据配置中,我们定义了一个名为MSSQL-demo的集成方案,目标是将数据写入SQL Server。为了实现这一目标,我们需要关注几个关键点:数据转换逻辑、自定义映射、以及接口调用的细节。
首先,在元数据配置中,定义了主表和扩展表参数。这些参数通过对象和数组结构来表示源数据的层次关系。例如,主表参数包括编码和名称,而扩展表参数则涵盖商品编码和数量。这种结构化的定义使得我们可以灵活地将复杂的数据结构映射到SQL ServerAPI所需的格式。
在进行ETL转换时,需要特别注意如何将这些参数与SQL语句相结合。元数据配置中提供了两个主要的SQL语句:主SQL语句用于插入主表数据,而扩展SQL语句用于插入扩展表的数据。通过使用占位符(如:no、:name等),我们能够动态地将源数据填充到目标SQL语句中,从而实现精准的数据写入。
对于高效的数据写入,支持高吞吐量能力是必不可少的。这意味着在批量处理大量数据时,系统能够快速响应并将其准确写入SQL Server。此外,通过实时监控与日志记录功能,我们可以随时跟踪数据处理状态,及时发现并解决潜在的问题。
在调用SQL ServerAPI接口时,需要注意分页和限流问题,以防止因请求过多导致系统性能下降。通过配置合理的分页策略,可以确保每次请求都能成功返回结果,同时不影响系统稳定性。
异常处理也是一个重要环节。在对接过程中可能会遇到各种异常情况,如网络故障或接口返回错误。此时,可以通过错误重试机制来提高系统的鲁棒性,确保即使出现短暂故障,也能最终完成数据写入任务。
最后,自定义数据映射对接功能允许我们根据特定业务需求调整数据转换逻辑。这种灵活性使得我们能够应对各种复杂的数据结构和业务场景,确保集成过程顺利进行。
综上所述,通过合理应用ETL转换、精细化配置元数据,以及有效管理接口调用,我们能够高效地实现源平台到SQL ServerAPI接口的数据集成,为企业提供可靠的数据支持。