查询班牛供应商代发虚拟仓:数据集成方案
在现代企业的数据管理中,如何高效、准确地实现系统间的数据对接成为了关键问题。本文将分享一个具体的技术案例:如何通过轻易云数据集成平台,将班牛供应商代发虚拟仓的数据无缝集成到班牛系统中。
为了确保数据集成过程的高效性和可靠性,我们采用了一系列先进的技术手段和工具。首先,通过支持高吞吐量的数据写入能力,使得大量数据能够快速被集成到班牛系统中,极大提升了数据处理的时效性。同时,利用轻易云提供的集中监控和告警系统,我们可以实时跟踪每个数据集成任务的状态和性能,及时发现并解决潜在的问题。
在具体实施过程中,我们调用了班牛提供的API接口column.list来获取所需的数据,并通过workflow.task.create接口将处理后的数据写入目标平台。为了适应特定业务需求,我们还自定义了数据转换逻辑,以确保不同系统间的数据格式差异得到有效处理。此外,为了保证数据质量,我们引入了异常检测机制,及时发现并处理任何可能出现的数据问题。
整个方案设计过程中,还特别关注了如何处理分页和限流问题,以确保在大规模数据传输时不漏单、不超时。通过可视化的数据流设计工具,使得整个集成过程更加直观、易于管理,并且可以根据实际需求进行灵活调整。
总之,本次案例展示了如何利用轻易云平台强大的功能,实现班牛与班牛之间复杂而精细的数据对接,为企业提供了一套高效、可靠的数据集成解决方案。在后续章节中,我们将详细介绍具体的实施步骤及技术细节。
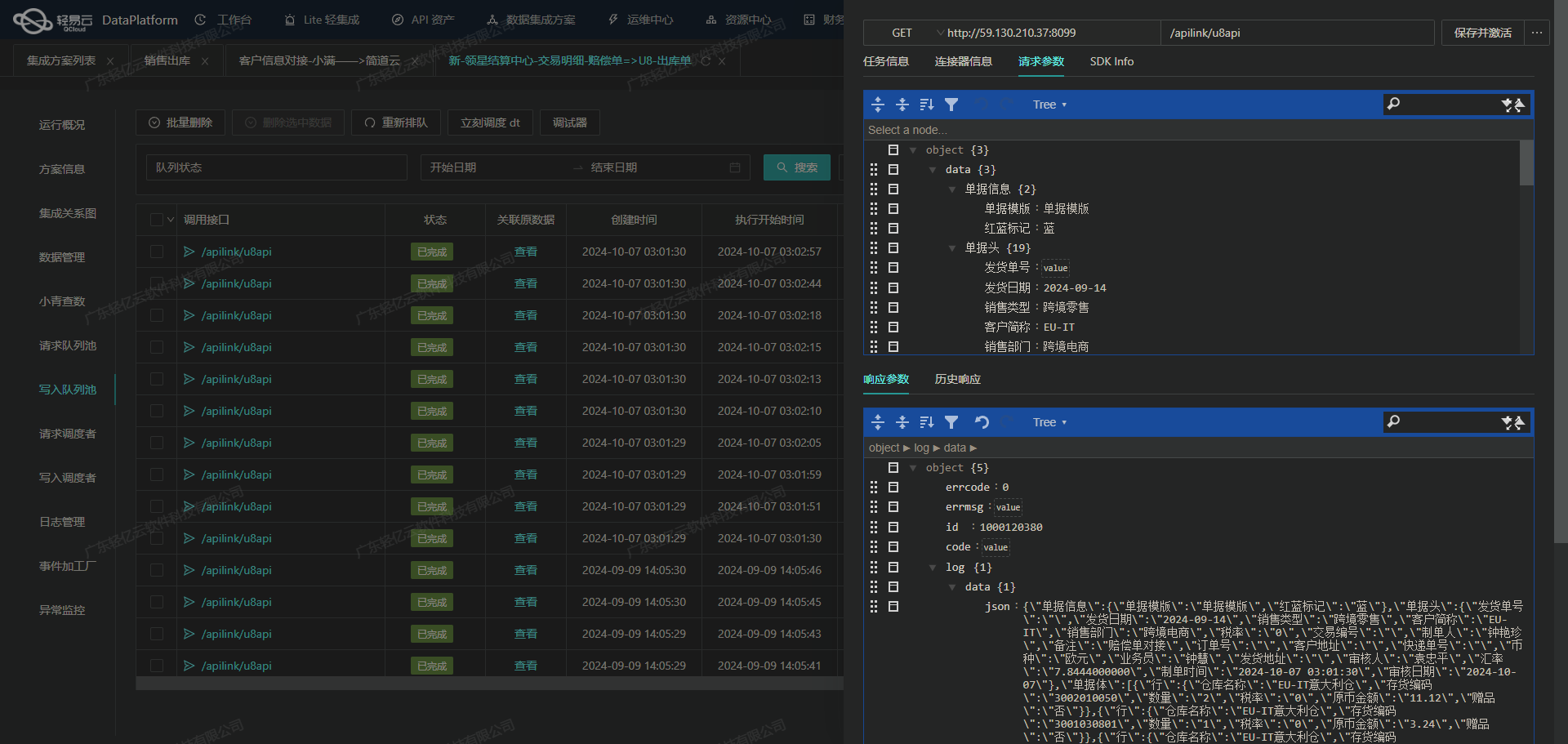
调用班牛接口column.list获取并加工数据
在轻易云数据集成平台的生命周期中,第一步是调用源系统班牛接口column.list来获取并加工处理数据。这一步至关重要,因为它决定了后续数据处理和集成的基础质量。本文将详细探讨如何高效地调用该接口,并对返回的数据进行必要的清洗和转换。
接口调用配置
首先,我们需要配置元数据以便正确调用班牛的column.list接口。根据提供的元数据配置,可以看到以下关键参数:
- API:
column.list - 请求方法: GET
- 请求字段: 包含
project_id,值为"77206" - 条件过滤:
column_id等于78530 - 自动填充响应: true
这些参数确保我们能够准确地从班牛系统中提取所需的数据。
数据请求与清洗
在发起GET请求时,我们需要特别注意以下几点:
- 参数校验:确保所有必需参数(如
project_id,column_id)都已正确设置。 - 分页处理:如果返回的数据量较大,需要实现分页机制,以避免一次性拉取过多数据导致性能问题。
- 限流控制:通过合理设置请求频率,防止触发班牛API的限流策略。
例如,一个典型的GET请求可能如下所示:
GET /api/column.list?project_id=77206&column_id=78530数据转换与写入
获取到原始数据后,下一步是对其进行清洗和转换。轻易云平台支持自定义的数据转换逻辑,这使得我们可以根据业务需求对数据进行灵活处理。例如:
- 字段映射:将班牛返回的数据字段映射到目标系统所需的字段。
- 格式转换:将日期、数值等字段转换为目标系统要求的格式。
- 异常处理:对于缺失或异常值进行补全或标记,以保证数据质量。
假设我们从班牛获取到如下JSON响应:
{
"columns": [
{"id": 78530, "name": "供应商代发虚拟仓", "status": "active"}
]
}我们可以通过轻易云的平台工具,将其转换为目标系统所需格式,例如:
{
"warehouseId": 78530,
"warehouseName": "供应商代发虚拟仓",
"isActive": true
}实时监控与日志记录
为了确保整个过程顺利进行,轻易云平台提供了实时监控和日志记录功能。这些功能帮助我们及时发现并解决问题,提高整体效率。例如,通过监控界面,可以实时查看每个API调用的状态、耗时以及是否成功。同时,对于失败或异常情况,可以通过日志快速定位问题原因,并采取相应措施。
异常重试机制
在实际操作中,不可避免会遇到网络波动或服务暂时不可用等情况。此时,轻易云平台内置的异常重试机制显得尤为重要。该机制允许我们针对特定错误类型(如超时、500内部服务器错误)设置自动重试策略,从而提高任务完成率。
综上所述,通过合理配置元数据、有效调用班牛接口、精细化的数据清洗与转换,以及完善的监控和异常处理机制,我们可以高效地完成轻易云数据集成平台生命周期中的第一步,为后续的数据集成工作打下坚实基础。

集成方案:查询班牛供应商代发虚拟仓
在数据集成过程中,ETL(Extract, Transform, Load)转换是关键环节之一。将源平台的数据转换为目标平台班牛API接口所能接收的格式,并最终写入目标平台,是确保数据流畅、准确的重要步骤。本文将详细探讨如何通过轻易云数据集成平台实现这一过程。
数据请求与清洗
首先,我们需要从源平台获取相关数据。这一步通常包括数据的提取和初步清洗,以确保数据的完整性和一致性。然而本文的重点在于第二步,即数据转换与写入。
数据转换与写入
在轻易云数据集成平台中,元数据配置是实现ETL转换的重要依据。以下是我们使用的元数据配置:
{
"api": "workflow.task.create",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true,
"request": [
{"field": "app_id", "label": "app_id", "type": "string", "value": "21151"},
{"field": "project_id", "label": "project_id", "type": "string", "value": "73625"},
{
"field": "contents",
"label": "contents",
"type": "object",
"children": [
{"field": "1", "label": "1", "type": "string", "value":"110529518"},
{"field": "3", "label": "3", "type":"string","value":"2023-05-03 19:10:22"},
{"field":"4","label":"4","type":"string","value":"2023-05-03 19:12:03"},
{"field":"5","label":"5","type":"string","value":"2"},
{"field":"73956","label":"73956","type":"string"}
]
}
]
}该元数据配置定义了如何将源平台的数据映射到班牛API接口所需的字段格式。在实际操作中,我们需要根据具体业务需求进行相应的字段映射和转换。
自定义数据转换逻辑
为了适应特定业务需求,可能需要对数据进行自定义转换。例如,将时间戳格式化为班牛API所要求的日期时间格式,或对某些字段进行计算处理。轻易云提供了灵活的自定义脚本功能,可以编写JavaScript或Python脚本来实现复杂的数据转换逻辑。
确保高吞吐量的数据写入
为了提升数据处理时效性,轻易云支持高吞吐量的数据写入能力。通过批量处理和并行写入机制,可以快速将大量数据集成到班牛系统中。这不仅提高了效率,还减少了单次请求的数据量,从而降低了接口调用失败的风险。
处理分页和限流问题
在调用班牛API时,需要注意分页和限流问题。通过合理设置分页参数和限流策略,可以避免因请求过多导致接口调用失败。同时,轻易云提供了自动重试机制,当接口调用失败时会自动进行重试,确保数据能够最终成功写入。
实现实时监控与日志记录
为了确保整个ETL过程的透明性和可控性,轻易云提供了实时监控和日志记录功能。通过集中监控系统,可以实时跟踪每个数据集成任务的状态和性能。一旦发生异常情况,可以及时发现并处理,确保数据集成过程顺利进行。
异常处理与错误重试机制
在实际操作中,不可避免地会遇到各种异常情况,如网络波动、接口响应超时等。轻易云提供了完善的异常处理与错误重试机制。当发生异常时,会自动记录详细日志并触发重试机制,以最大程度保证数据的完整性和一致性。
数据质量监控与异常检测
为了保证集成到班牛系统中的数据质量,需要对每个环节进行严格监控。轻易云的数据质量监控功能可以自动检测并报告潜在的问题,如缺失值、重复值等,并提供相应的解决方案。
定制化数据映射对接
根据不同业务需求,可以定制化映射规则,将源平台的数据精确地映射到班牛API所需的字段。这种灵活性使得我们能够更好地适应各种复杂业务场景,实现精准的数据对接。
综上,通过合理配置元数据、自定义转换逻辑、高效的数据写入机制以及完善的监控与异常处理功能,可以有效实现源平台到班牛系统的数据ETL转换,确保整个过程高效、可靠。