钉钉数据集成到SQL Server:查询钉钉报销表单
在企业日常运营中,报销流程的高效管理至关重要。为了实现这一目标,我们利用轻易云数据集成平台,将钉钉中的报销表单数据无缝对接到SQL Server数据库中。本案例将详细介绍如何通过API接口topapi/processinstance/get从钉钉获取数据,并使用SQL Server的写入API exec进行数据存储。
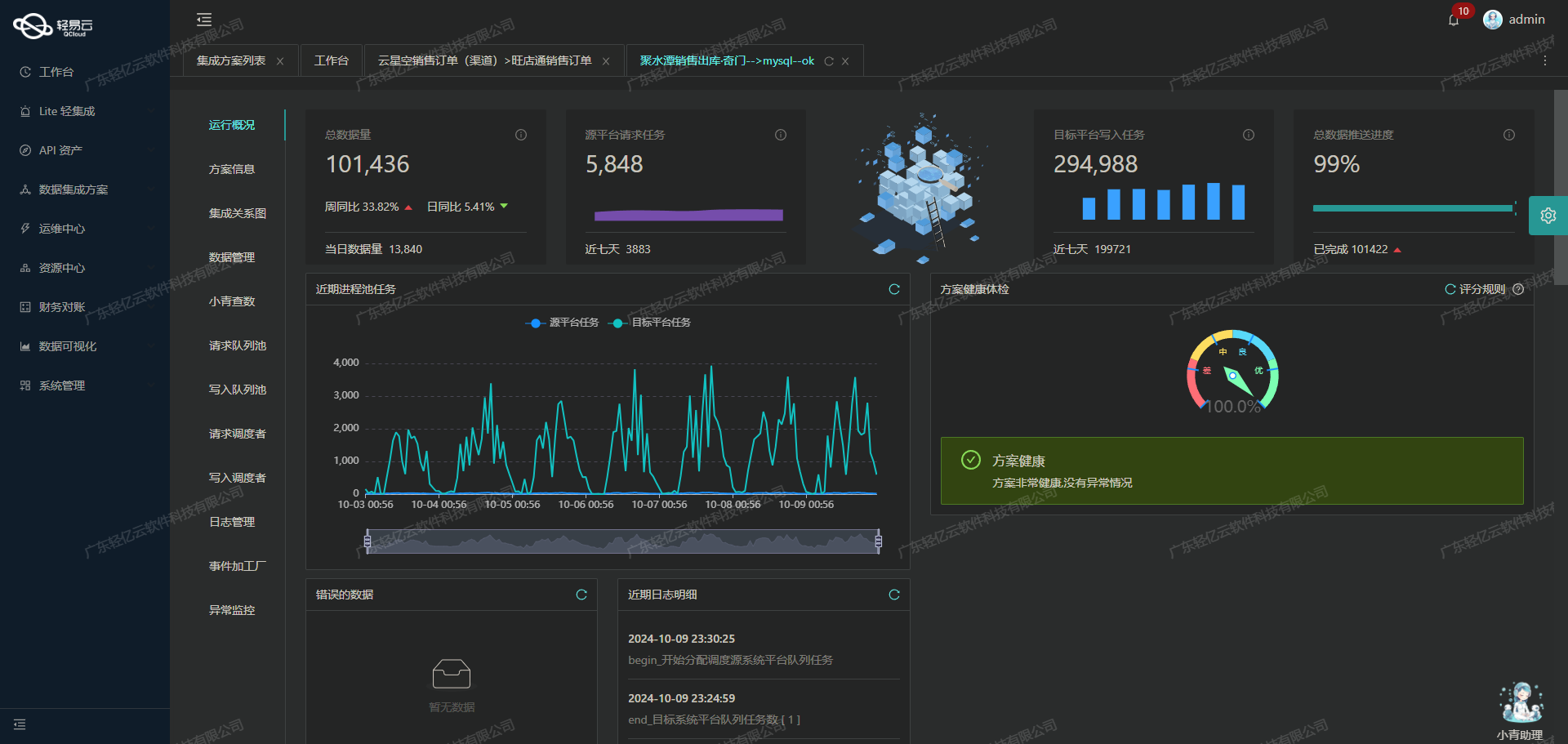
首先,轻易云平台提供了强大的高吞吐量数据写入能力,使得大量报销表单数据能够快速被集成到SQL Server中。这一特性极大提升了数据处理的时效性,确保业务部门能够及时获取最新的报销信息。
其次,为了保证整个集成过程的可靠性和透明度,我们利用了轻易云平台提供的集中监控和告警系统。该系统实时跟踪每个数据集成任务的状态和性能,一旦出现异常情况,能够及时发出告警并采取相应措施,从而避免因数据问题导致业务中断。
此外,在实际操作过程中,我们还需要处理钉钉与SQL Server之间的数据格式差异。轻易云平台支持自定义的数据转换逻辑,使得我们可以根据具体业务需求调整数据结构,确保两者之间的数据兼容性。同时,通过可视化的数据流设计工具,我们可以直观地管理和优化整个数据集成流程。
最后,为了应对API调用中的分页和限流问题,我们设计了一套定时可靠的数据抓取机制。这不仅保证了每次抓取操作都能成功执行,还有效防止了漏单现象的发生。结合SQL Server定制化的数据映射对接方案,我们实现了批量、高效、稳定的数据集成。
通过以上技术手段,本案例成功实现了从钉钉到SQL Server的报销表单查询与存储,为企业财务管理提供了一套高效、可靠的数据解决方案。在后续章节中,我们将进一步探讨具体实施步骤及相关技术细节。
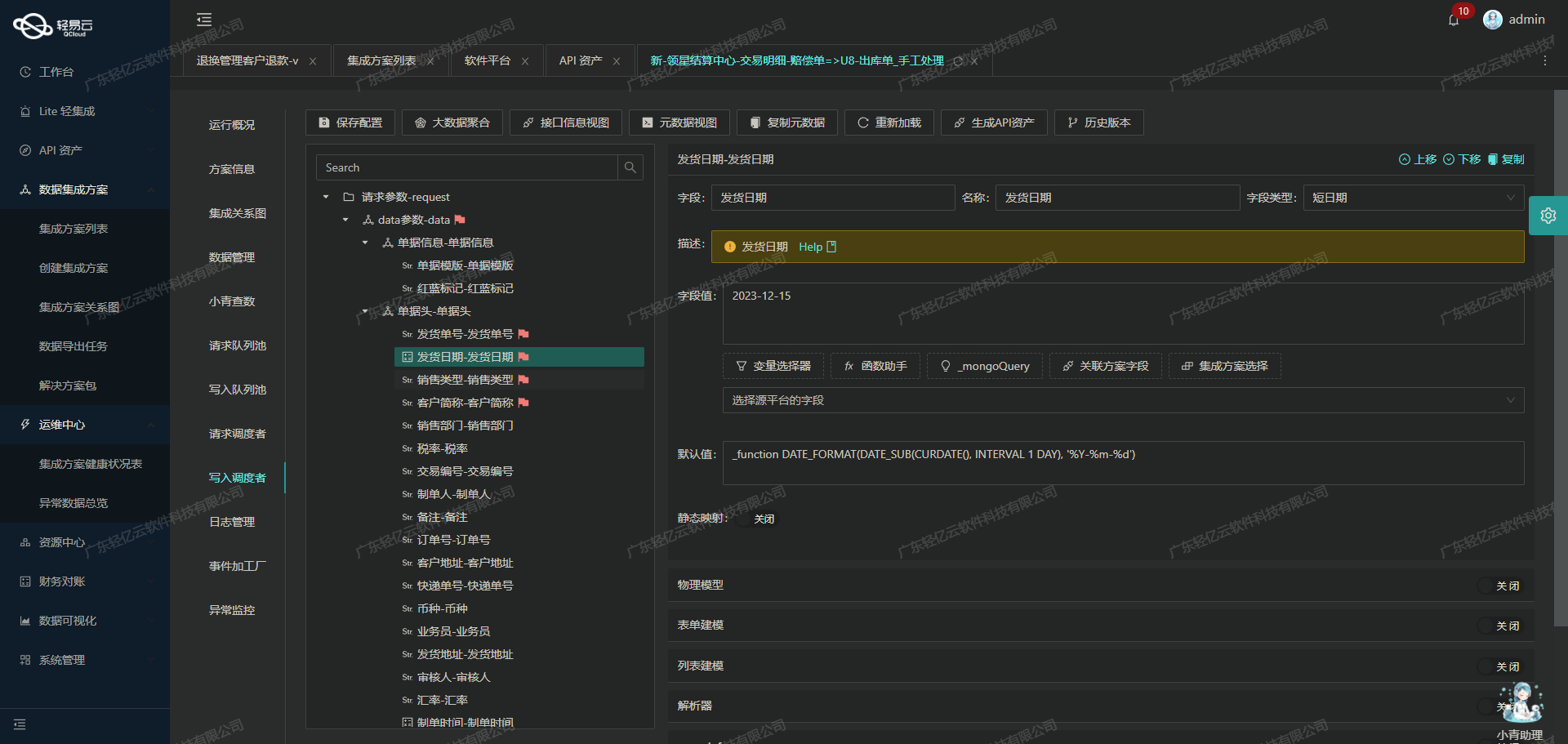
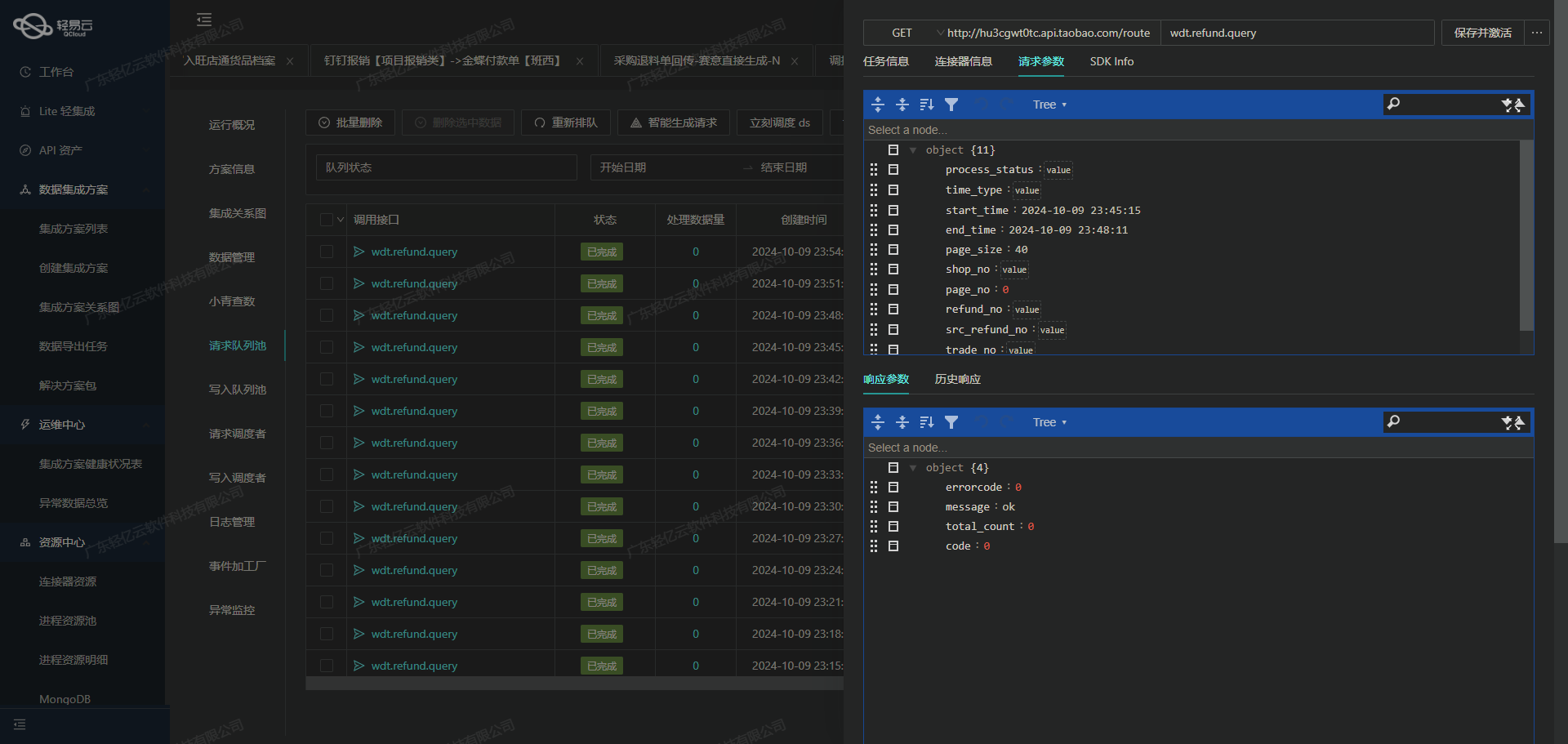
调用钉钉接口topapi/processinstance/get获取并加工数据
在轻易云数据集成平台的生命周期中,第一步是调用源系统接口以获取原始数据,并对其进行初步加工处理。本文将详细探讨如何通过调用钉钉接口topapi/processinstance/get来查询报销表单,并对获取的数据进行有效的处理和转换。
接口调用与元数据配置
首先,我们需要了解如何配置和调用钉钉的API接口。根据提供的元数据配置:
{
"api": "topapi/processinstance/get",
"effect": "QUERY",
"method": "POST",
"number": "number",
"id": "id",
"idCheck": true,
"autoFillResponse": true
}该配置表明我们将使用POST方法来查询特定报销表单的数据。关键参数包括number和id,其中idCheck确保了ID字段的唯一性,而autoFillResponse则自动填充响应结果。
数据请求与清洗
在实际操作中,首先需要构建请求体,以便向钉钉API发送查询请求。以下是一个简化的请求示例:
{
"process_instance_id": "<具体实例ID>"
}发送请求后,我们会收到包含报销表单详细信息的响应数据。在这一阶段,必须对原始数据进行清洗,以确保其符合后续处理需求。例如,去除冗余字段、标准化日期格式、校验金额字段等。
数据转换与写入准备
清洗后的数据通常仍需进一步转换,以适应目标系统(如SQL Server)的要求。这可能涉及到字段映射、类型转换以及结构调整。例如,将JSON格式的数据转换为关系型数据库所需的行列形式。
假设我们从钉钉API获得了如下部分响应:
{
"process_instance_id": "<具体实例ID>",
"title": "<报销标题>",
"create_time": "<创建时间>",
...
}在转换过程中,我们可能需要将这些字段映射到SQL Server中的相应列,如下所示:
process_instance_id -> instance_idtitle -> reimbursement_titlecreate_time -> created_at
这种映射可以通过轻易云平台提供的自定义数据转换逻辑来实现,从而确保每个字段都能准确地写入目标数据库。
分页与限流处理
由于API调用可能涉及大量数据,因此分页和限流是不可避免的问题。为了高效地处理大批量数据,可以利用轻易云平台内置的分页机制,通过循环逐页获取并处理数据。此外,还需考虑API限流策略,避免因频繁调用导致被封禁或延迟。
例如,在分页处理中,每次请求时可指定一个偏移量和限制数量:
{
"offset": <当前偏移量>,
"limit": <每页记录数>
}通过调整这两个参数,可以逐步获取所有所需的数据,同时遵守API服务商规定的速率限制。
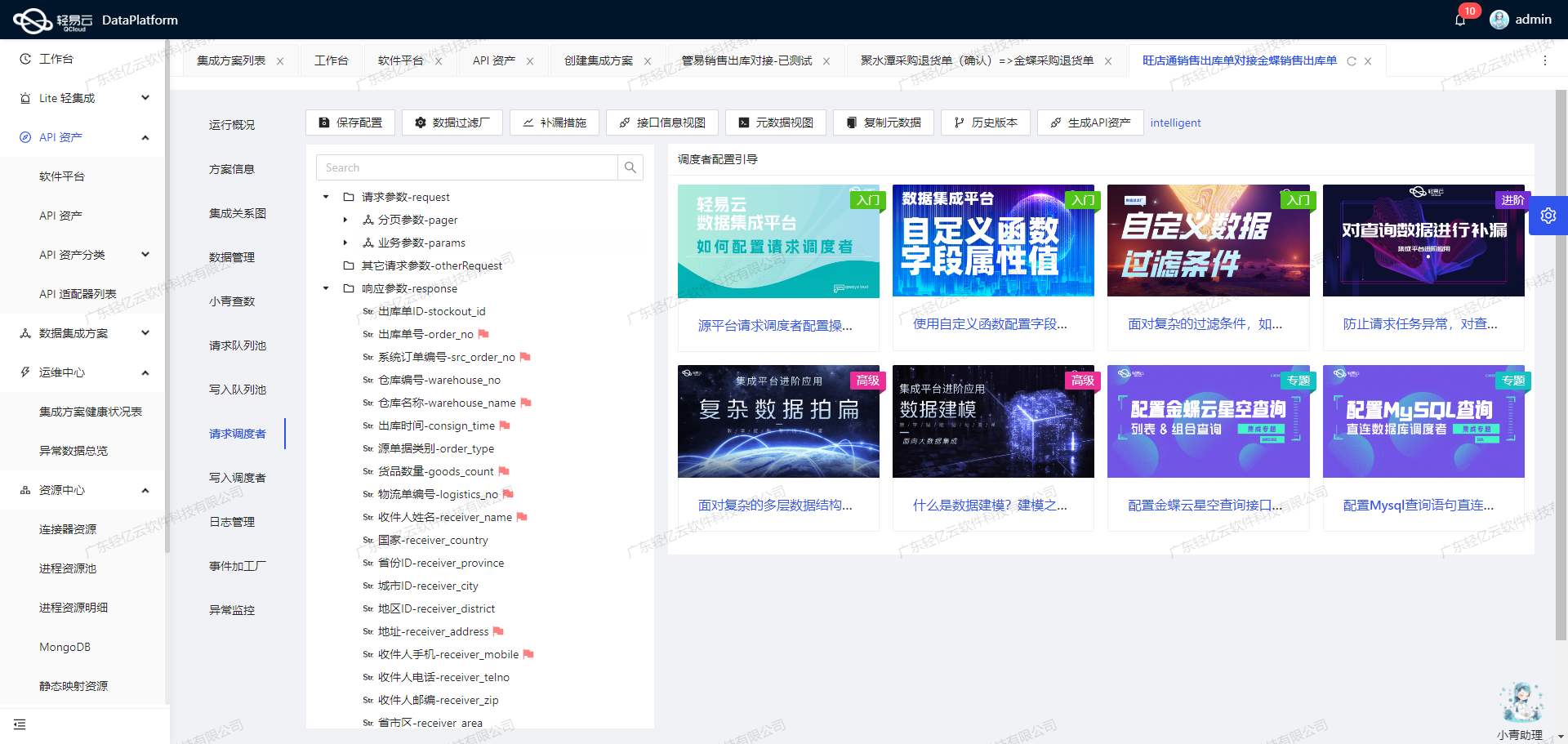
实时监控与异常处理
轻易云平台提供了强大的实时监控和告警系统,可用于跟踪每个集成任务的状态和性能。一旦出现异常情况,例如网络问题或API返回错误码,系统会自动触发告警,并根据预设策略执行重试或其他补救措施。这种机制确保了集成过程的稳定性和可靠性。
总结而言,通过合理配置元数据、精细化的数据清洗与转换,以及有效管理分页与限流问题,可以高效地实现从钉钉接口获取并加工报销表单数据,为后续的数据写入奠定坚实基础。
钉钉报销表单数据ETL转换及写入SQL Server的技术实现
在数据集成生命周期的第二步,我们主要关注如何将已经从钉钉系统中获取的报销表单数据进行ETL(提取、转换、加载)处理,并将其转为SQL Server API接口能够接收的格式,最终写入目标平台SQL Server。以下是详细的技术实现步骤和注意事项。
数据提取与清洗
首先,使用钉钉提供的API接口topapi/processinstance/get获取报销表单数据。为了确保数据完整性和准确性,需要处理分页和限流问题。可以通过设置合理的分页参数和限流策略,确保每次请求都能成功返回所需的数据。
# 示例代码:调用钉钉接口获取报销表单数据
response = requests.post('https://oapi.dingtalk.com/topapi/processinstance/get', data={
'process_instance_id': process_instance_id,
'access_token': access_token
})
data = response.json()数据转换
在获取到原始数据后,需要对其进行转换,以适应目标平台SQL Server的格式要求。根据元数据配置,我们需要将报销表单中的字段映射到SQL Server对应的字段,并进行必要的数据格式转换。
- 日期和时间字段转换:使用
DATE_FORMAT函数将日期字段转换为YYYY-MM-DD格式,并提取年度和期间信息。 - 金额字段转换:直接映射原始金额字段到目标字段。
- 摘要字段生成:通过字符串拼接生成摘要信息。
- 科目编码映射:根据部门名称和费用类型生成对应的科目编码。
{
"main_params": {
"Date": "_function DATE_FORMAT('{{extend.finish_time}}', '%Y-%m-%d')",
"Year": "_function YEAR('{{extend.finish_time}}')",
"period": "_function MONTH('{{extend.finish_time}}')",
"Group": "记",
"entryCount": "{{entry_count}}",
"Amount": "{{合计金额(元)}}",
"Note": "{{extend.finish_time}}付{title}",
"BillUser": "Manager",
"detailNumbers": "{{核算项目}}"
},
"extend_params_1": [
{
"borrow-1": {
"lastInsertId": ":lastInsertId",
"FEntryID": "{{FEntryID}}",
"FNote": "{{extend.finish_time|date}}付{title}{{报销明细.费用事由}}{{报销明细.费用类型}}",
...
},
...
}
]
}数据写入
在完成数据转换后,需要将其批量写入到SQL Server。这里我们采用存储过程(Stored Procedure)来执行插入操作,以提高性能和安全性。根据元数据配置,主语句和扩展语句分别对应存储过程sp_AddVoucher和sp_AddVoucherEntry。
EXEC sp_AddVoucher @Date, @Year, @period, @Group, @entryCount, @Amount, @Note, @BillUser, @detailNumbers;
EXEC sp_AddVoucherEntry @lastInsertId, @FEntryID, @FNote, @AccountNumber, @AccountNumber1, @FCurrencyNumber, @FExchangeRate, @FDC, @FAmountFor, @Famount, @Fquantity, @FUnitPrice, @FMeasureUnitNumber, @FDetailID;异常处理与重试机制
在实际操作过程中,可能会遇到各种异常情况,如网络故障、数据库连接失败等。因此,需要设计完善的异常处理与重试机制,确保数据能够可靠地写入目标平台。
try:
# 执行存储过程
cursor.execute("EXEC sp_AddVoucher ...")
except Exception as e:
logger.error(f"Error occurred: {e}")
# 实现重试逻辑实时监控与日志记录
通过集成平台提供的监控和告警系统,可以实时跟踪数据集成任务的状态和性能。一旦发现异常情况,可以及时采取措施。此外,通过日志记录功能,可以详细记录每次操作的输入输出及执行结果,为后续分析提供依据。
logger.info("Data integration task started")
# 执行ETL操作
logger.info("Data integration task completed successfully")以上是实现钉钉报销表单数据ETL转换并写入SQL Server的关键技术步骤。通过合理的数据清洗、格式转换、批量写入以及完善的异常处理机制,可以高效、可靠地完成整个数据集成过程。