钉钉数据集成到金蝶云星空——案例分享:修改下推的付款单③
在本篇技术文章中,我们将深入分析如何通过轻易云数据集成平台,实现企业内部系统间的数据交互。具体来说,我们将探讨一个实际运行的方案,即从钉钉获取支付相关数据,并批量写入到金蝶云星空,以实现高效和可靠的业务数据同步。
集成场景与接口概述
为了确保全部付款单据能准确无误地被记录和处理,首先要解决的是如何从钉钉中定时、可靠地抓取接口topapi/processinstance/get所提供的数据。此API允许我们访问指定流程实例的详细信息,其中包括付款审批、日期等关键字段。这些信息将在后续步骤中被转换并匹配到金蝶云星空所需的数据格式。
另一方面,对于大量数据快速写入金蝶云星空,我们使用了其提供的batchSave接口。这一接口支持批量插入操作,可以有效提升大规模数据处理速度,同时减少对网络资源的占用,从而保障系统在高负载情况下依旧保持稳定性和高效性。
主要挑战与解决方案
-
如何确保不漏单: 为了防止任何需要追踪或存储的重要数据信息丢失,通过定制化脚本及自动重试机制进行多次验证。在抓取过程中,还加入实时监控与日志记录,针对异常情况可迅速响应。
-
分页和限流问题:由于钉钉API有分页限制,每次请求只能返回部分结果,因此需编写相应逻辑处理连续分页请求。同时,为避免频繁调用触发限流,对请求进行了合理延迟设置。
-
数据格式差异:因为两套系统间的数据结构存在明显不同,需要额外关注关键字段之间的一致性。在此案例中,通过自定义映射配置,将来自钉钉中的JSON格式解析为适用于金蝶云星空要求的数据字段形式,如日期时间转换、金额单位调整等。
-
异常处理与错误重试机制:任何无法成功写入至目标系统(即金蝶云星空)的情况,均会触发预设好的错误捕捉模块,此模块负责记录日志并根据设定策略重新尝试提交,直到成功为止以保障业务持续不中断。
接下来部分内容将详细介绍这一系列集成过程,包括核心代码片段以及参数配置等细节,以便大家能够顺利复现这些关键步骤。
调用钉钉接口topapi/processinstance/get获取并加工数据
在数据集成生命周期的第一步中,调用源系统接口是关键环节。本文将深入探讨如何通过轻易云数据集成平台调用钉钉接口topapi/processinstance/get,获取并加工数据。
接口调用配置
首先,我们需要配置元数据,以便正确调用钉钉的API接口。以下是元数据配置的具体内容:
{
"api": "topapi/processinstance/get",
"method": "POST",
"number": "business_id",
"id": "单据编号",
"idCheck": true,
"condition": [
[
{
"field": "extend.status",
"logic": "eq",
"value": "COMPLETED"
}
]
],
"request": [
{
"label": "审批流的唯一码",
"field": "process_code",
"type": "string",
"value": "PROC-BB90A28C-0800-4F37-A972-E23EA258CA09"
},
{
"label": "审批实例开始时间。Unix时间戳,单位毫秒。",
"field": "start_time",
"type": "string",
"value": "{LAST_SYNC_TIME}000"
},
{
"label": "审批实例结束时间,Unix时间戳,单位毫秒",
"field": "end_time",
"type": "string",
"value": "{CURRENT_TIME}000"
},
{
"label": "分页参数,每页大小,最多传20。",
"field": "size",
"type": "string",
"value": 20
},
{
"label": "分页查询的游标,最开始传0,后续传返回参数中的next_cursor值。",
"field": "cursor",
"type": null
}
]
}请求参数解析
- process_code: 审批流的唯一码,用于标识特定的审批流程。
- start_time: 审批实例开始时间,以Unix时间戳表示。这里使用了占位符
{LAST_SYNC_TIME},表示上次同步的时间。 - end_time: 审批实例结束时间,同样以Unix时间戳表示,使用占位符
{CURRENT_TIME}表示当前时间。 - size: 分页参数,每页大小设置为20。
- cursor: 分页查询的游标,初始值为0,在后续请求中使用返回参数中的
next_cursor值。
数据请求与清洗
在调用API获取数据后,需要对数据进行清洗和处理。以下是一个示例代码片段,用于展示如何处理返回的数据:
import requests
import json
url = 'https://oapi.dingtalk.com/topapi/processinstance/get'
headers = {'Content-Type': 'application/json'}
payload = {
'process_code': 'PROC-BB90A28C-0800-4F37-A972-E23EA258CA09',
'start_time': f'{LAST_SYNC_TIME}000',
'end_time': f'{CURRENT_TIME}000',
'size': 20,
'cursor': 0
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
data = response.json()
# 数据清洗与处理
if data['errcode'] == 0:
instances = data['result']['list']
for instance in instances:
if instance['status'] == 'COMPLETED':
# 对完成状态的数据进行进一步处理
process_instance(instance)
else:
print(f"Error: {data['errmsg']}")在这个示例中,我们首先构建了请求的URL和头部信息,然后根据元数据配置构建请求体并发送POST请求。接收到响应后,我们检查返回码是否为0(表示成功),然后对返回的数据进行遍历和处理。
数据转换与写入
在完成数据清洗后,需要将数据转换为目标系统所需的格式,并写入目标系统。这一步通常包括字段映射、格式转换等操作。例如:
def process_instance(instance):
transformed_data = {
'单据编号': instance['business_id'],
'审批状态': instance['status'],
# 更多字段映射...
}
# 写入目标系统(例如数据库)
write_to_target_system(transformed_data)
def write_to_target_system(data):
# 实现写入逻辑,例如插入数据库
pass通过上述步骤,我们实现了从调用钉钉接口获取数据,到清洗、转换和写入目标系统的完整流程。这一过程充分利用了轻易云数据集成平台提供的全生命周期管理功能,使得每个环节都透明可控,高效可靠。
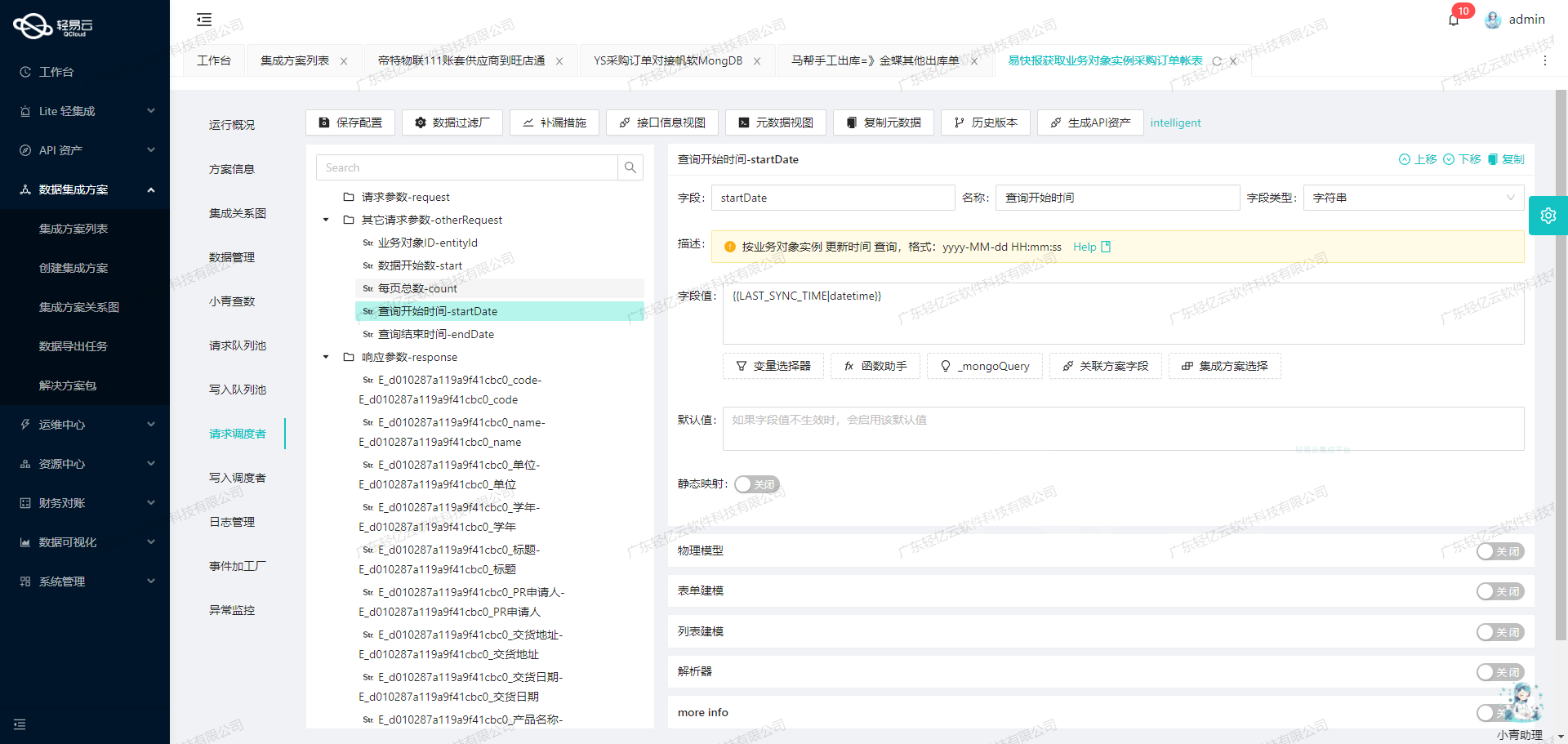
使用轻易云数据集成平台进行ETL转换并写入金蝶云星空API接口
在数据集成的生命周期中,第二步是将已经集成的源平台数据进行ETL(提取、转换、加载)转换,并将其转为目标平台金蝶云星空API接口所能够接收的格式,最终写入目标平台。本文将深入探讨这一过程中的技术细节和具体实现方法。
1. 配置元数据
首先,我们需要配置元数据以适应金蝶云星空API接口的要求。以下是一个示例元数据配置:
{
"api": "batchSave",
"method": "POST",
"idCheck": true,
"operation": {
"method": "batchArraySave",
"rows": 1,
"rowsKey": "array"
},
"request": [
{
"field": "FID",
"label": "单据编号",
"type": "string",
"describe": "单据编号",
"value": "_findCollection find FID from b91e58dd-b358-385e-a6e9-58ae2b8c37ff where FBillNo={Number}"
},
{
"field": "F_VAOJ_HKSX",
"label": "货款属性",
"type": "string",
"describe": "单据类型",
"value": "_function case '{{货款属性}}' when '成品' then 'CP' else 'FL' end"
},
{
"label": "备注",
"field": "FREMARK",
"type": "string",
"value": "{title}-{{收款人(公司名称)}}-{{备注}}"
},
{
"label": "单据编号",
"field": "FBillNo",
"type": "string",
"value": "{business_id}"
}
],
...
}2. 数据提取与清洗
在ETL过程中,首先要从源系统中提取数据,并对其进行清洗和预处理。通过轻易云的数据处理能力,可以高效地完成这一阶段。例如,我们可以使用SQL查询或其他数据提取方式,从源系统中获取需要的数据。
SELECT FID, FBillNo, title, 收款人, 备注, 货款属性 FROM SourceTable WHERE Condition = 'Value';3. 数据转换
接下来是数据转换阶段,这一步骤至关重要,因为需要将源数据转化为目标系统能够识别和处理的格式。在我们的案例中,需要将源数据字段映射到金蝶云星空API所需的字段格式。
例如,对于“货款属性”字段,我们使用了一个简单的条件语句来进行转换:
{
...
{
“field”: “F_VAOJ_HKSX”,
“label”: “货款属性”,
“type”: “string”,
“describe”: “单据类型”,
“value”: “_function case ‘{{货款属性}}’ when ‘成品’ then ‘CP’ else ‘FL’ end”
}
}这个配置会根据“货款属性”的值,将其转换为相应的代码,如“成品”被转换为“CP”,其他情况则为“FL”。
4. 数据加载
最后一步是将转换后的数据加载到目标系统,即金蝶云星空。我们使用API接口batchSave来批量保存这些数据。
以下是一个示例请求体:
{
...
{
“FormId”: “AP_PAYBILL”,
“Operation”: “BatchSave”,
“IsAutoSubmitAndAudit”: false,
“IsVerifyBaseDataField”: false,
“NeedUpDateFields”: [“F_VAOJ_HKSX”, “FREMARK”, “FBillNo”],
...
}
}通过上述配置,我们可以确保所有必要的数据字段都被正确地映射和传输到目标系统中。
API调用示例
在实际操作中,我们会通过HTTP POST请求来调用金蝶云星空的API接口:
import requests
url = 'https://api.kingdee.com/batchSave'
headers = {'Content-Type': 'application/json'}
data = {
# 根据上文配置生成的数据结构
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
print('Data successfully saved to Kingdee Cloud')
else:
print('Failed to save data:', response.text)这种方式不仅简化了复杂的数据集成过程,还确保了每个环节都透明可视,极大提升了业务效率和准确性。
通过上述步骤,我们成功地完成了从源平台到金蝶云星空的ETL转换和数据写入,实现了不同系统间的数据无缝对接。这一过程展示了轻易云数据集成平台在处理异构系统集成时的强大功能和灵活性。