吉客云采购退货数据集成到MySQL的技术案例分享
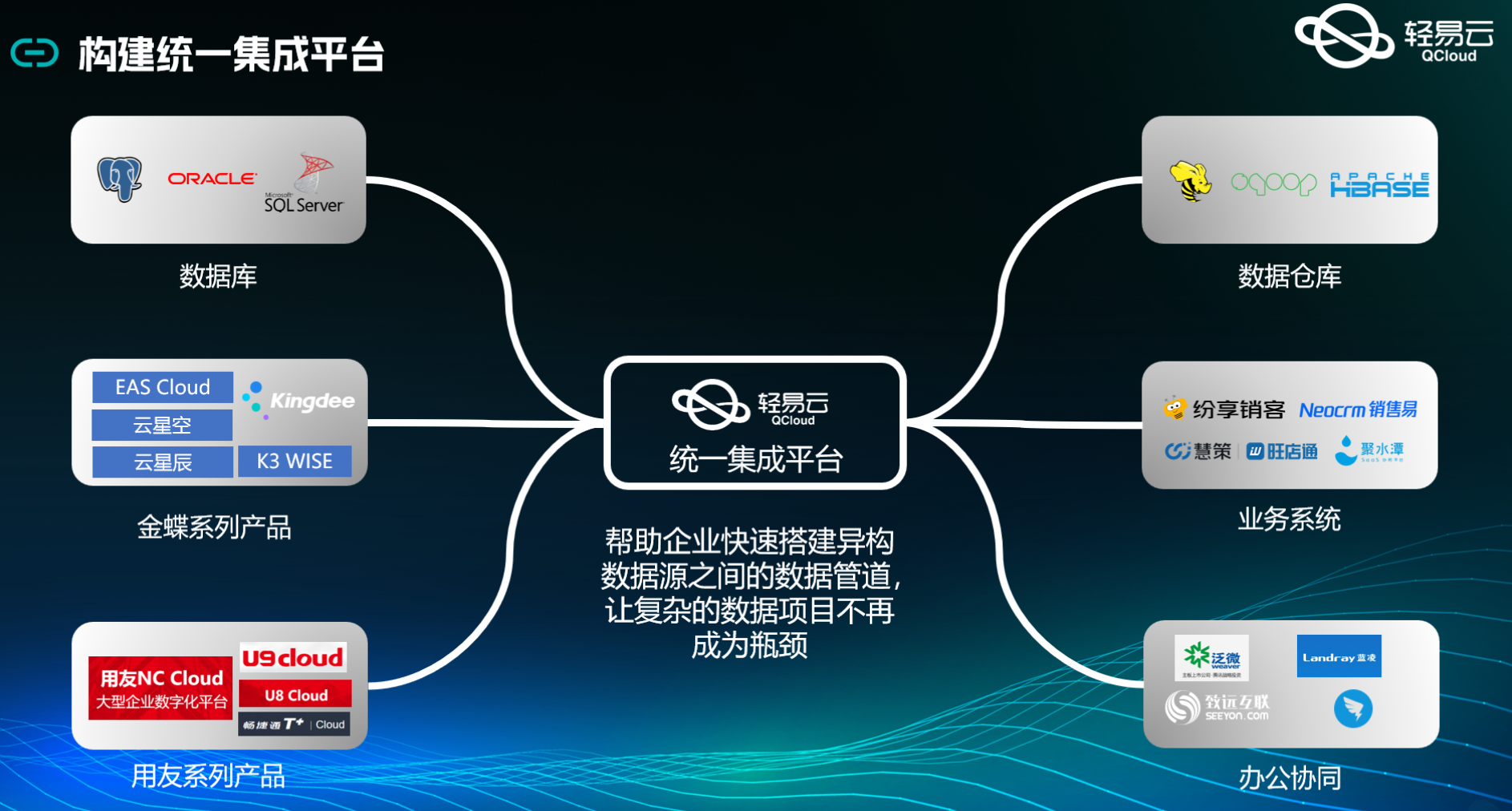
在企业日常运营中,采购退货数据的高效管理和处理至关重要。本文将聚焦于一个具体的系统对接集成案例——吉客云采购退货-BDSBI_pro,通过轻易云数据集成平台,将吉客云的数据无缝对接到MySQL数据库。
首先,我们需要解决的是如何确保从吉客云获取的数据不漏单,并能定时可靠地抓取吉客云接口数据。为此,我们使用了吉客云提供的API接口erp.purchreturn.get,该接口能够精准地获取所需的采购退货数据。同时,为了应对大量数据快速写入到MySQL的问题,我们采用了高吞吐量的数据写入能力,使得大批量的数据可以迅速且稳定地存储到目标数据库中。
在实际操作过程中,处理分页和限流问题是关键的一环。通过合理设置分页参数和限流策略,可以有效避免因请求过多导致的性能瓶颈。此外,为了确保数据质量,我们引入了实时监控与日志记录机制,对每一次数据传输进行全程跟踪。一旦发现异常情况,系统会自动触发告警并执行错误重试机制,以保证数据传输的完整性和准确性。
为了适应不同业务需求和复杂的数据结构,我们还支持自定义的数据转换逻辑。这使得我们能够灵活地将吉客云中的原始数据转换为符合MySQL数据库要求的格式,从而实现无缝对接。同时,通过可视化的数据流设计工具,整个集成过程变得更加直观和易于管理,大大提升了工作效率。
最后,在MySQL端,我们利用其强大的API资产管理功能,通过统一视图全面掌握所有API调用情况,实现资源的高效利用和优化配置。这不仅提高了系统整体性能,还为后续的数据分析与决策提供了坚实基础。
以上就是本次技术案例开头部分内容。在接下来的章节中,我们将详细探讨具体实施步骤及相关技术细节。
调用吉客云接口erp.purchreturn.get获取并加工数据
在轻易云数据集成平台的生命周期中,第一步是调用源系统吉客云的接口erp.purchreturn.get来获取采购退货数据,并进行初步的数据加工处理。该步骤至关重要,因为它确保了后续数据处理和写入环节的准确性和有效性。
接口调用与参数配置
为了从吉客云获取采购退货数据,我们需要正确配置API请求参数。根据元数据配置,以下是关键参数:
pageIndex: 分页页码,用于控制分页查询。pageSize: 分页大小,默认值为50。warehouseCode: 仓库编号,用于筛选特定仓库的数据。skuBarcode: 商品条码,用于筛选特定商品的数据。startDate和endDate: 创建时间范围,用于限定查询时间段。startReturnTime和endReturnTime: 退货时间范围,用于进一步细化查询条件。orderNum: 退货单号,用于精确查找特定订单。
这些参数通过POST方法传递给API,以实现对采购退货数据的精准抓取。例如:
{
"pageIndex": "1",
"pageSize": "50",
"warehouseCode": "",
"skuBarcode": "",
"startDate": "{{LAST_SYNC_TIME|datetime}}",
"endDate": "{{CURRENT_TIME|datetime}}",
"startReturnTime": "",
"endReturnTime": "",
"orderNum": ""
}数据分页与限流处理
由于可能存在大量数据,我们需要考虑分页和限流问题。通过设置合理的pageSize和逐步增加pageIndex,可以有效地分批次获取完整的数据集。同时,为了避免API调用频率过高导致被限流,可以在每次请求之间加入适当的延时或使用异步任务调度机制。
数据清洗与转换
在获取到原始数据后,需要进行初步的数据清洗和转换。这包括但不限于:
- 字段映射:将吉客云返回的数据字段映射到目标系统所需的字段。例如,将返回结果中的
orderId映射为目标数据库中的主键ID。 - 格式转换:将日期、数值等字段转换为目标系统所需的格式。例如,将字符串形式的日期转换为标准的日期时间格式。
- 异常检测:检查并过滤掉不符合预期的数据,如缺失关键字段或格式错误的数据记录。
实时监控与日志记录
为了确保整个过程顺利进行,实时监控和日志记录是必不可少的。轻易云平台提供了集中监控和告警系统,可以实时跟踪每个API调用任务的状态和性能。一旦发现异常情况(如网络超时、接口返回错误等),可以及时触发告警并采取相应措施。
此外,通过详细的日志记录,可以追溯每一次API调用及其响应结果,这对于排查问题和优化流程具有重要意义。
自定义逻辑与业务需求适配
根据具体业务需求,还可以在数据清洗过程中添加自定义逻辑。例如,对于某些特殊类型的订单,可以根据业务规则进行额外处理或标记。这种灵活性使得轻易云平台能够适应各种复杂多变的业务场景。
综上所述,通过合理配置API请求参数、处理分页与限流、执行数据清洗与转换以及实时监控与日志记录,我们能够高效地从吉客云获取采购退货数据,并为后续的数据处理奠定坚实基础。这一步骤不仅确保了数据质量,也提升了整体集成效率。
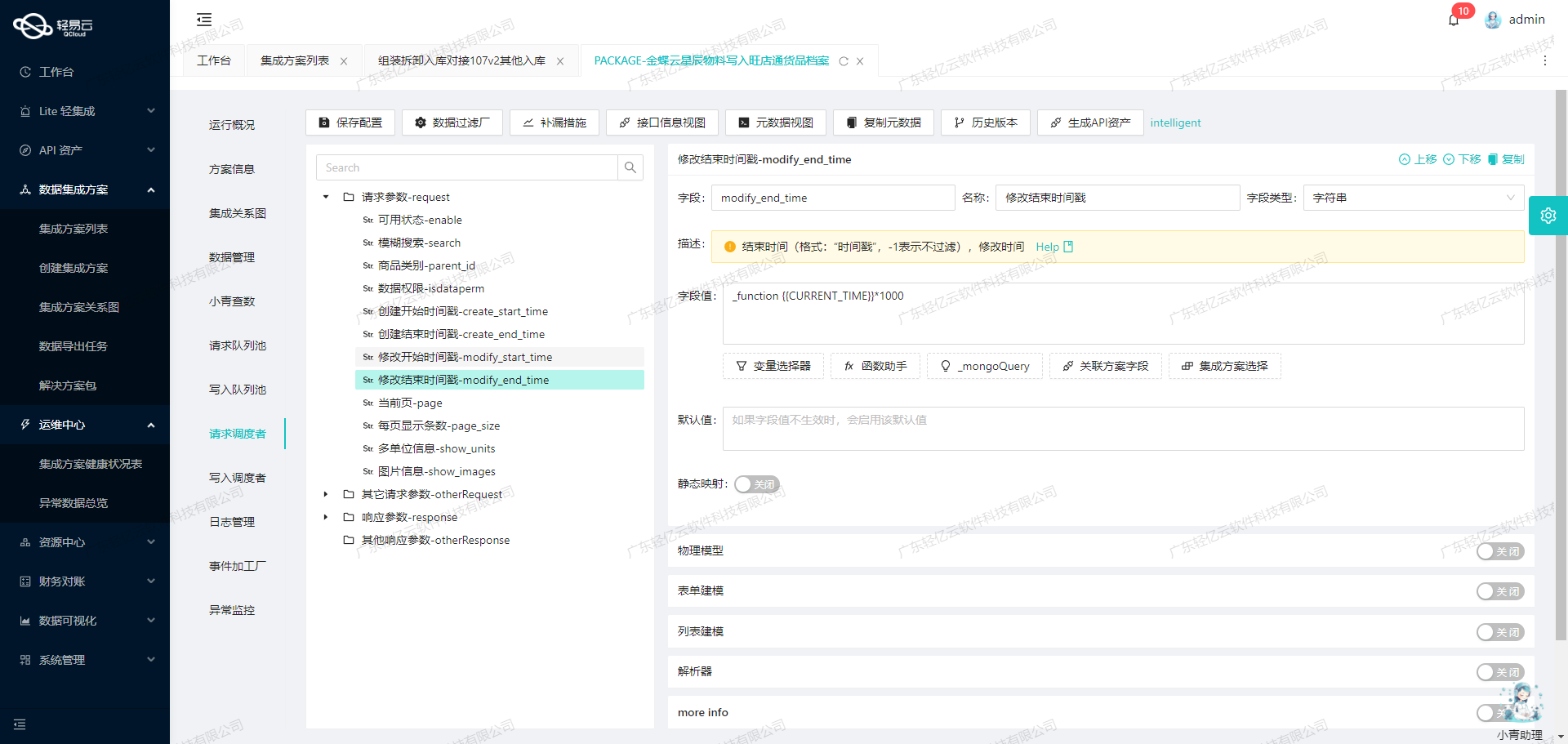
集成吉客云采购退货数据到MySQL的ETL转换与写入
在数据集成生命周期的第二步中,关键任务是将已经集成的源平台数据进行ETL转换,使其符合目标平台MySQLAPI接口能够接收的格式,并最终写入目标平台。本文将详细探讨这一过程,特别关注如何处理数据格式差异、分页与限流问题、异常处理与错误重试机制等技术细节。
数据格式差异的处理
在ETL过程中,首先需要解决的是吉客云和MySQL之间的数据格式差异问题。例如,吉客云接口erp.purchreturn.get返回的数据包含了多种字段类型,如字符串、整数和日期时间。而MySQL数据库中相应的表结构可能要求特定的数据类型和格式。
元数据配置中提供了一个示例,将吉客云的数据字段映射到MySQL字段:
{
"field": "gmt_create",
"label": "创建时间",
"type": "datetime",
"value": "_function FROM_UNIXTIME( ( {gmtCreate} / 1000 ) ,'%Y-%m-%d %T' )"
}这里通过一个函数将Unix时间戳转换为MySQL所需的标准日期时间格式。这种定制化的数据转换逻辑是确保数据能够正确写入目标平台的关键步骤。
批量数据写入与高吞吐量支持
在批量集成大量数据到MySQL时,高吞吐量的数据写入能力至关重要。通过批量操作,可以显著提高数据写入效率,减少网络延迟和数据库锁定时间。以下是一个示例SQL语句,用于批量插入采购退货主表数据:
INSERT INTO `lehua`.`purchase_return`
(`order_id`, `user_code`, `real_name`, `order_num`, `company_name`, `order_type`, `purch_type`,
`vend_name`, `gmt_create`, `text`, `currency_code`, `currency_rate`, `out_status`,
`sett_status`, `revw_status`, `prov_create`, `busi_name`, `dept_name`, `crt_name`,
`purch_code`, `currency_name`, `logistic_type`, `logistic_no`,
`logistic_code`, `logistic_name`,`warehouse_name`,`warehouse_code`,`create_time`,`create_by`)
VALUES
(<{order_id: }>, <{user_code: }>, <{real_name: }>, <{order_num: }>, <{company_name: }>,
<{order_type: }>, <{purch_type: }>, <{vend_name: }>, <{gmt_create: }>, <{text: }>,
<{currency_code: }>, <{currency_rate: }>, <{out_status: }>, <{sett_status: }>,
<{revw_status: }>, <{prov_create: 0000-00-00 00:00:00}>, <{busi_name: }>,
<{dept_name: }>, <{crt_name: }>, <{purch_code: }>, <{currency_name: }>
,<{logistic_type: }>, <{logistic_no: }> ,<{logistic_code}> ,<{logistic_name}>
,<{warehouse_name}> ,<{warehouse_code}> ,<{create_time}> ,< {create_by}>);这种批量插入方式不仅提高了效率,还能有效管理数据库事务,确保数据一致性。
分页与限流问题
在处理大规模数据时,分页和限流策略至关重要。吉客云接口通常会返回大量数据,因此需要合理设置分页参数,以避免单次请求过大导致系统性能下降或超时。可以通过设置每次请求的数据条数(如每页100条),并使用分页标识符逐页获取数据。
{
"api": "executeReturn",
"method": "POST",
"request": [
{"field": "page", "type": "int", "value": "{page}"},
{"field": "pageSize", "type": "int", "value": "{pageSize}"}
]
}以上配置示例展示了如何在请求中添加分页参数,从而实现对大规模数据的分片处理。
异常处理与错误重试机制
为了保证数据集成过程的可靠性,需要实现异常处理与错误重试机制。当出现网络故障或数据库锁定等问题时,可以捕获异常并进行重试操作,以确保最终所有数据都能成功写入目标平台。
例如,在执行SQL插入操作时,可以捕获数据库异常并记录日志,然后根据配置的重试策略重新尝试插入操作:
BEGIN
-- 插入操作
INSERT INTO lehua.purchase_return (...);
EXCEPTION WHEN OTHERS THEN
-- 捕获异常并记录日志
LOG_ERROR(...);
-- 根据重试策略重新尝试
RETRY(...);
END;这种机制不仅提高了系统的鲁棒性,还能及时发现并解决潜在的问题,保障集成任务顺利完成。
实时监控与日志记录
通过实时监控和日志记录,可以全面掌握数据集成过程中的各项指标,如任务状态、执行时间、错误次数等。这有助于快速定位问题并采取相应措施,提高系统整体性能和稳定性。
综上所述,通过合理设计ETL流程、优化批量写入、实现分页与限流策略,以及完善的异常处理与监控机制,可以有效地将吉客云采购退货数据转换并写入到MySQL平台,确保数据集成过程高效、可靠。