聚水谭-店铺商品资料单集成到BI邦盈-店铺商品资料表(只新增)技术案例
在数据驱动的业务环境中,如何高效、准确地实现系统间的数据对接和集成是每个企业面临的重要挑战。本文将详细分享一个实际的系统对接集成案例:将聚水潭·奇门平台中的店铺商品资料单数据集成到MySQL数据库中的BI邦盈-店铺商品资料表(仅新增)。
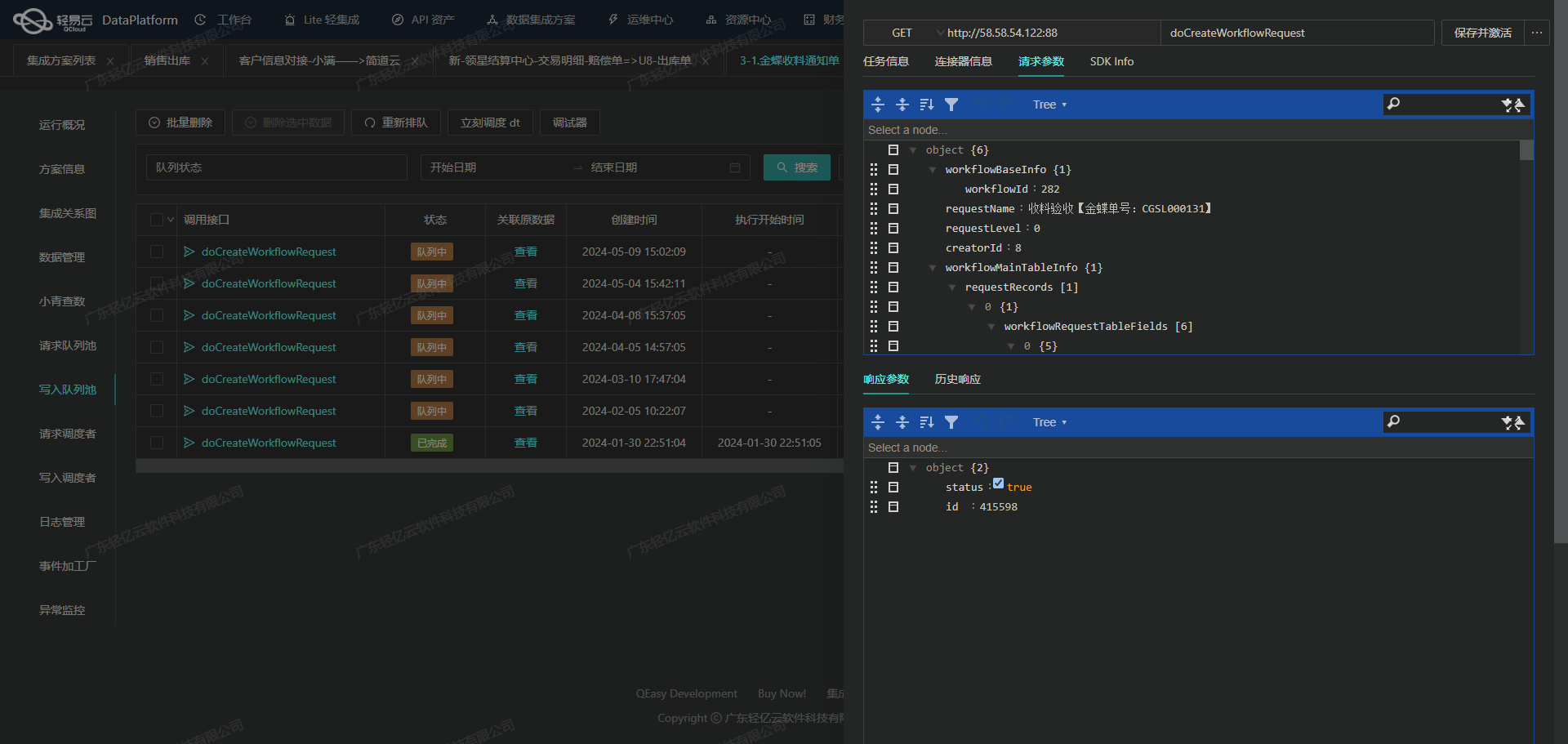
本次集成方案主要利用了轻易云数据集成平台的高吞吐量数据写入能力和实时监控功能,以确保大量数据能够快速、安全地从聚水潭·奇门系统传输并写入到MySQL数据库中。通过调用聚水潭·奇门提供的API接口jushuitan.itemskumapper.list.query获取最新的商品资料,并使用MySQL的批量写入API batchexecute进行数据存储。
为了保证数据处理过程的透明度和可靠性,我们采用了以下关键技术特性:
- 高吞吐量的数据写入能力:支持大规模数据快速写入,提升了整体处理效率。
- 集中监控和告警系统:实时跟踪数据集成任务状态,及时发现并处理异常情况。
- 自定义数据转换逻辑:适应不同业务需求和数据结构,实现灵活的数据映射。
- 分页与限流处理:有效管理API调用频率,避免因请求过多导致接口限流问题。
此外,为确保整个集成过程中不漏单,我们设计了一套定时可靠的数据抓取机制,通过定期调用聚水潭·奇门接口来获取最新的数据更新,并结合MySQL定制化的数据映射对接策略,将新增加的商品资料精确无误地存储到目标数据库中。
在后续章节中,我们将深入探讨具体的实施步骤,包括如何调用聚水潭·奇门接口、处理分页与限流问题,以及实现MySQL对接异常处理与错误重试机制等内容。通过这一案例,希望能为类似需求提供有价值的参考和借鉴。
调用聚水潭·奇门接口jushuitan.itemskumapper.list.query获取并加工数据
在轻易云数据集成平台的生命周期中,第一步是调用源系统接口以获取原始数据。本文将详细探讨如何通过调用聚水潭·奇门接口jushuitan.itemskumapper.list.query来实现这一过程,并对数据进行初步加工处理。
接口调用配置
首先,我们需要配置元数据,以便正确地调用聚水潭·奇门的API接口。以下是关键的元数据配置:
{
"api": "jushuitan.itemskumapper.list.query",
"effect": "QUERY",
"method": "POST",
"number": "{sku_id}+{modified}",
"id": "{sku_id}+{modified}",
"name": "name",
"request": [
{"field": "page_index", "label": "第几页", "type": "int", "value": "1"},
{"field": "page_size", "label": "每页多少条", "type":"int", "value":"50"},
{"field":"modified_begin","label":"修改起始时间","type":"string","value":"{{LAST_SYNC_TIME|datetime}}"},
{"field":"modified_end","label":"修改结束时间","type":"string","value":"{{CURRENT_TIME|datetime}}"}
],
"autoFillResponse": true,
"delay":5
}数据请求与清洗
在实际操作中,通过上述配置,我们可以发送POST请求至jushuitan.itemskumapper.list.query接口,获取指定时间段内的商品SKU映射列表。为了确保高效的数据抓取和处理,我们需要注意以下几点:
- 分页处理:由于单次请求返回的数据量有限(每页50条),我们需要通过循环分页来获取全部数据。这可以通过调整
page_index参数实现。 - 时间窗口:利用
modified_begin和modified_end参数,可以精确控制抓取的数据范围,避免重复或遗漏。 - 自动填充响应:设置
autoFillResponse: true,使得平台能够自动解析并填充返回的数据结构,简化后续的数据处理步骤。
数据转换与写入准备
在成功获取到原始数据后,需要对其进行初步清洗和转换,以适应目标系统(如MySQL)的要求。具体步骤包括:
- 字段映射:根据业务需求,将源系统中的字段映射到目标系统。例如,将SKU ID和修改时间组合成唯一标识符。
- 格式转换:确保日期、数值等字段符合目标系统的格式要求。
- 去重与过滤:移除重复记录,并根据业务逻辑筛选出有效数据。
实践案例
假设我们从聚水潭·奇门接口获取到如下部分响应:
{
"data":[
{
"sku_id":"12345",
"name":"商品A",
"modified":"2023-10-01T12:00:00"
},
{
"sku_id":"67890",
"name":"商品B",
"modified":"2023-10-01T12:05:00"
}
]
}我们需要将这些记录转换为适合MySQL存储的格式,例如:
INSERT INTO bi_shop_items (id, name, modified) VALUES ('12345+2023-10-01T12:00:00', '商品A', '2023-10-01T12:00:00');
INSERT INTO bi_shop_items (id, name, modified) VALUES ('67890+2023-10-01T12:05:00', '商品B', '2023-10-01T12:05:00');异常处理与优化
在实际操作中,还需考虑异常情况,如网络波动、API限流等问题。可以采取以下措施:
- 重试机制:对于临时性错误,可设置重试策略,以提高成功率。
- 限流保护:根据API文档限制请求频率,避免触发限流机制。
- 日志记录与监控:实时监控任务状态,并记录日志以便于排查问题。
通过以上步骤,我们能够高效地调用聚水潭·奇门接口获取并加工数据,为后续的数据集成奠定坚实基础。在整个过程中,轻易云平台提供了强大的可视化工具和监控功能,使得复杂的数据集成任务变得更加直观和易于管理。
数据集成与ETL转换:从聚水潭到MySQL
在数据集成的生命周期中,将已经集成的源平台数据进行ETL转换并写入目标平台是关键步骤之一。本文将详细探讨如何将聚水潭的店铺商品资料单通过ETL转换,转为MySQLAPI接口所能够接收的格式,并最终写入MySQL数据库。
数据请求与清洗
首先,我们需要从聚水潭平台抓取店铺商品资料单的数据。通过调用jushuitan.itemskumapper.list.query接口,可以获取到相关的商品信息。为了确保数据不漏单,需要处理分页和限流问题,确保每次请求都能完整获取所有数据。
数据转换与写入
一旦获取到原始数据,接下来就是进行ETL(Extract, Transform, Load)转换。我们需要将这些数据转化为MySQLAPI接口能够接收的格式。以下是元数据配置中的关键字段及其映射关系:
{
"api": "batchexecute",
"effect": "EXECUTE",
"method": "SQL",
"idCheck": true,
"request": [
{"field":"co_id","label":"公司编号","type":"string","value":"{co_id}"},
{"field":"shop_id","label":"店铺编号","type":"string","value":"{shop_id}"},
{"field":"channel","label":"来源平台","type":"string","value":"{channel}"},
{"field":"i_id","label":"款式编码(线上款式编码)","type":"string","value":"{i_id}"},
{"field":"sku_id","label":"商品编码(线上商品编码)","type":"string","value":"{sku_id}"}
// 其他字段省略
],
"otherRequest": [
{"field": "main-sql", "label": "主语句", "type": "string", "value": "INSERT INTO item_sku_mapper (co_id,shop_id,channel,i_id,sku_id,...) VALUES"},
{"field": "limit", "label": "limit", "type": "string", "value": "500"}
]
}数据映射
在上述配置中,每个字段都有明确的映射关系。例如,co_id表示公司编号,shop_id表示店铺编号等。这些字段需要从源数据中提取,并按照目标表结构进行插入操作。
自定义数据转换逻辑
有些字段可能需要特殊处理,例如时间字段或价格字段。在这种情况下,可以使用自定义函数来进行转换。例如,insert_time字段默认值可以设置为当前时间:
{"field":"insert_time","label":"加工时间","type":"string","value":"{modified}","default":"_function NOW()"}数据质量监控与异常处理
在整个ETL过程中,数据质量监控和异常处理至关重要。实时监控任务状态和性能,及时发现并处理数据问题。例如,可以设置告警系统,当某个任务失败时立即通知相关人员。
高吞吐量的数据写入
为了提升数据处理的时效性,需要支持高吞吐量的数据写入能力。通过批量插入操作,可以大幅度提高数据写入效率。例如,在上述配置中,通过设置limit参数为500,实现一次批量插入500条记录。
MySQL对接注意事项
在将数据写入MySQL时,需要注意以下几点:
- 事务管理:确保每次插入操作都是原子性的,以防止部分成功、部分失败的情况。
- 错误重试机制:对于可能出现的网络故障或数据库锁定情况,设计错误重试机制。
- 索引优化:合理设计索引,提高查询和插入效率。
- 分页处理:对于大规模数据集,采用分页处理策略,以避免内存溢出。
实现细节
最后,通过调用MySQLAPI接口,将转换后的数据批量写入目标数据库:
INSERT INTO item_sku_mapper (co_id, shop_id, channel, i_id, sku_id, ...) VALUES (?, ?, ?, ?, ?)以上是从聚水潭平台到MySQL数据库的数据集成过程中的关键技术点和实现细节。通过合理配置元数据、优化ETL流程、加强监控和异常处理,可以有效提升数据集成效率和质量。