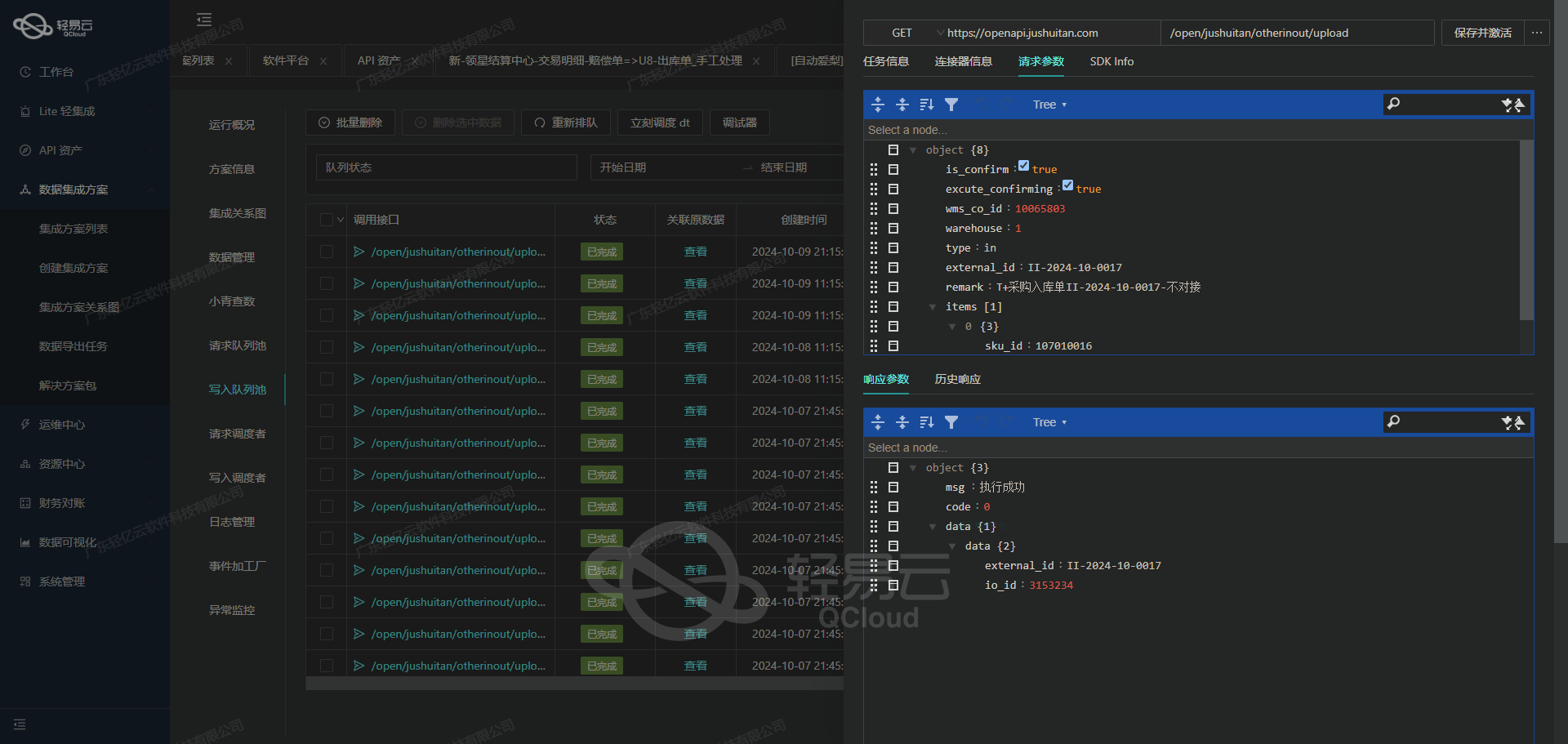
案例分享:聚水潭数据集成到畅捷通T+的技术实施
在本案例中,我们将详细探讨如何通过API接口实现将聚水潭的其他入库单数据无缝集成至畅捷通T+系统,确保数据信息准确无误,同时大幅提升处理效率。我们的方案名称为“聚水潭-其他入库单-->畅捷通-其他入库单”,其核心涉及多个关键步骤与技术细节。
首先,通过调用聚水潭提供的数据接口/open/other/inout/query,我们能够定时、可靠地抓取最新的其他入库单数据。为了应对可能存在的大量数据,我们设计了一套分页机制,确保在处理限流问题时不会遗漏任何订单。
抓取到原始数据后,需要解决的是两系统之间的数据格式差异。这一过程会用到轻易云提供的数据转换工具,将聚水潭的JSON格式调整适配为畅捷通T+要求的结构。在这个过程中,我们特别关注了字段映射和类型转换的问题,以确保写入环节顺利进行。
接下来,通过调用另一个API接口 /tplus/api/v2/otherReceive/Create ,我们实现了批量向畅捷通T+快速写入已整理好的数据,此操作不仅提高了整体效率,还减少了每次请求的开销。尽管如此,在实际运行中难免出现异常情况。因此我们加入了错误重试机制,如果某个输入失败,会自动记录日志并尝试重新提交。
实时监控与日志记录同样是不可或缺的一部分,它帮助开发人员迅速定位问题,并随时掌握整个流程中的各个环节状态。从而保障整个集成过程透明、高效且可追踪。
通过本文所述的方法与策略,为企业客户搭建更加智能化、自动化的数据桥梁,让不同信息系统间协作变得更简单高效。
调用聚水潭接口/open/other/inout/query获取并加工数据
在数据集成生命周期的第一步中,调用源系统接口获取数据是至关重要的。本文将深入探讨如何通过轻易云数据集成平台调用聚水潭接口/open/other/inout/query,并对获取的数据进行初步加工。
接口配置与请求参数
首先,我们需要配置元数据以便正确调用聚水潭接口。以下是元数据配置的详细内容:
{
"api": "/open/other/inout/query",
"effect": "QUERY",
"method": "POST",
"number": "io_id",
"id": "io_id",
"idCheck": true,
"request": [
{"field":"modified_begin","label":"修改起始时间","type":"datetime","value":"{{MINUTE_AGO_20|datetime}}"},
{"field":"modified_end","label":"修改结束时间","type":"datetime","value":"{{CURRENT_TIME|datetime}}"},
{"field":"status","label":"单据状态","type":"string","value":"Confirmed"},
{"field":"page_index","label":"第几页","type":"string","value":"1"},
{"field":"page_size","label":"每页多少条","type":"string","value":"30"},
{"field":"date_type","label":"抓取时间类型","type":"string","describe":"0:修改时间,modified。 2:出入库时间 io_date,未传入时默认为0"}
],
"autoFillResponse": true,
"condition_bk": [
[{"field": "type", "logic": "notin", "value": "其它出库"}]
],
"condition": [
[{"field": "type", "logic": "notin", "value": "其它出库"}, {"field": "wms_co_id", "logic": "neqv2", "value": "10406603"}]
],
"omissionRemedy": {
"crontab": "2 */3 * * *",
"takeOverRequest":[
{"field":"modified_begin","value":"_function FROM_UNIXTIME( unix_timestamp() -86400 , '%Y-%m-%d %H:%i:%s' )","type":"string","label":"接管字段"}
]
}
}请求参数详解
- modified_begin 和 modified_end:用于指定查询的时间范围。
{{MINUTE_AGO_20|datetime}}表示从当前时间前20分钟开始,{{CURRENT_TIME|datetime}}表示当前时间。 - status:单据状态,这里固定为"Confirmed"。
- page_index 和 page_size:分页参数,分别表示查询第几页和每页多少条记录。
- date_type:抓取时间类型,默认为0,即按修改时间查询。
条件过滤与自动填充
- condition_bk 和 condition:用于过滤不需要的数据。例如,排除“其它出库”类型的单据,并且
wms_co_id不等于10406603。 - autoFillResponse:启用自动填充响应功能,可以简化后续的数据处理工作。
数据请求与清洗
通过上述配置,我们可以发起POST请求,从聚水潭系统中获取符合条件的数据。以下是一个示例请求体:
{
"modified_begin": "{{MINUTE_AGO_20|datetime}}",
"modified_end": "{{CURRENT_TIME|datetime}}",
"status": "Confirmed",
"page_index": 1,
"page_size": 30,
"date_type": 0
}在接收到响应后,需要对数据进行初步清洗和验证。例如:
- 确认所有必需字段是否存在且格式正确。
- 根据业务逻辑进一步过滤不需要的数据。
异常处理与补救机制
为了确保数据的完整性和连续性,我们还配置了异常处理和补救机制:
- omissionRemedy:设置了定时任务,每隔三小时执行一次,以防止遗漏数据。通过
FROM_UNIXTIME( unix_timestamp() -86400 , '%Y-%m-%d %H:%i:%s' )动态计算前一天的开始时间,以便重新抓取可能遗漏的数据。
通过以上步骤,我们可以高效地从聚水潭系统中获取并清洗所需的数据,为后续的数据转换与写入打下坚实基础。这一过程充分利用了轻易云数据集成平台的强大功能,实现了不同系统间的数据无缝对接。
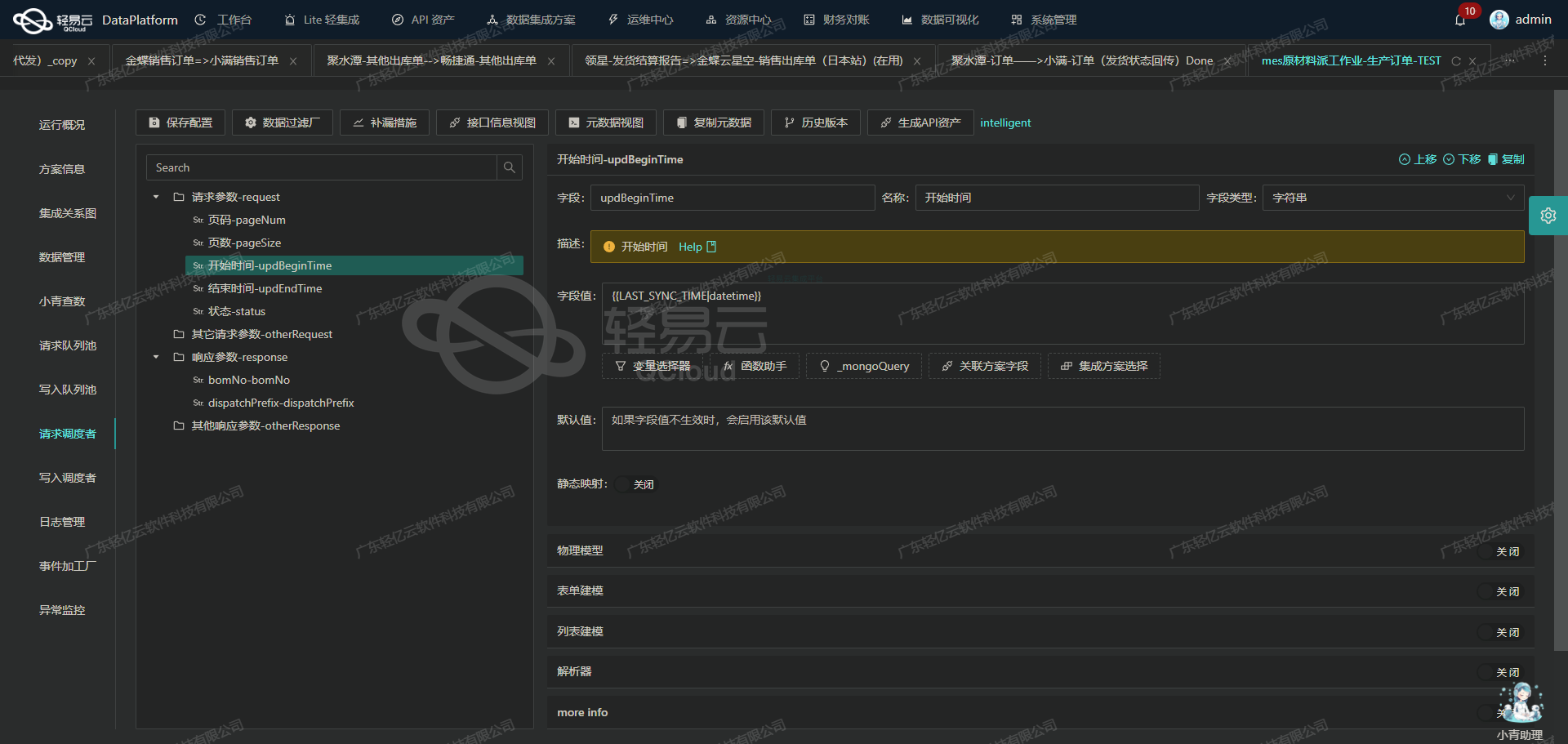
使用轻易云数据集成平台将聚水潭其他入库单转换并写入畅捷通T+API接口
在数据集成的生命周期中,ETL(Extract, Transform, Load)过程是至关重要的一环。本文将详细探讨如何使用轻易云数据集成平台,将已经从源平台(如聚水潭)提取并清洗后的数据,转换为畅捷通T+ API接口所能接收的格式,并最终写入目标平台。
API接口配置
根据元数据配置,我们需要将聚水潭的其他入库单数据转换为畅捷通T+所需的格式,并通过/tplus/api/v2/otherReceive/Create接口进行提交。以下是具体的配置细节:
- API路径:
/tplus/api/v2/otherReceive/Create - 请求方法:
POST - 执行效果:
EXECUTE - ID检查:
true
请求参数解析
-
ExternalCode (外部单据号):
- 类型:
string - 描述:外部单据号,用于唯一性检查,防止重复提交。
- 值:
{io_id}
- 类型:
-
VoucherType (单据类型):
- 类型:
string - 描述:单据类型,默认值为
ST1004。 - 值:
ST1004 - 解析器:
ConvertObjectParser,参数为Code
- 类型:
-
VoucherDate (单据日期):
- 类型:
string - 描述:单据日期
- 值:
{modified}
- 类型:
-
BusiType (业务类型):
- 类型:
string - 描述:业务类型编码,取值范围包括13(其他)和14(其他退库)。
- 值:
13 - 解析器:
ConvertObjectParser,参数为Code
- 类型:
-
Warehouse (仓库信息):
- 类型:
string - 描述:仓库信息
- 值:
{wms_co_id} - 解析器:
ConvertObjectParser, 参数为Code - 映射关系:
{ "target": "66d687ab2f3fde34df428d6d", "direction": "positive" }
- 类型:
-
Memo (表头备注):
- 类型:
string - 描述:备注信息
- 值:
{remark}
- 类型:
-
DynamicPropertyKeys:
- 类型:
string - 值:
pubuserdefnvc3,pubuserdefnvc4 - 解析器:
StringToArray, 参数为,
- 类型:
-
DynamicPropertyValues:
- 类型:
string - 值:
13<{io_id} - 解析器:
StringToArray, 参数为<
- 类型:
-
RdStyle (入库类别):
- 类型:
string - 值:
113 - 解析器:
ConvertObjectParser, 参数为Code
- 类型:
-
RDRecordDetails (单据明细信息): 包含以下子字段:
[ { "field": "Inventory", "label": "存货信息", "type": "string", "value": "{sku_id}", "parser": { "name": "ConvertObjectParser", "params": "Code" } }, { "field": "BaseQuantity", "label": "主计量单位数量", "type": "string", "value": "{qty}" }, { "field": "Price", "label": "成本单价", "type": "string", "value": "{sale_price}" }, { "field": "Project", "label": "项目", "type": "string", "value": 807, { name: 'ConvertObjectParser', params: 'Code' } } ] -
OtherRequest:
[ { field: 'dataKey', label: 'dataKey', type: 'string', describe: '111', value: 'dto' } ]
数据转换与写入
在实际操作中,我们需要确保每个字段的数据都经过正确的转换和映射。例如:
- 使用
{io_id}来填充外部单据号 (ExternalCode) 字段,以确保唯一性。 - 将
{modified}转换为标准日期格式以填充单据日期 (VoucherDate) 字段。 - 利用
ConvertObjectParser将业务类型编码 (BusiType) 转换为目标系统可识别的代码。
对于复杂的数据结构,如单据明细信息 (RDRecordDetails) ,我们需要逐一处理每个子字段,确保其值和格式符合目标平台的要求。
通过以上配置和处理步骤,我们可以高效地将聚水潭其他入库单的数据转换并写入畅捷通T+系统,实现不同系统间的数据无缝对接。这不仅提高了数据处理效率,也保证了数据的一致性和准确性。