汤臣倍健营销云数据集成到SQL Server:退货入库-四川绪泰
在信息化系统的对接过程中,实现高效可靠的数据集成至关重要。本文将聚焦于一个具体的技术案例,展示如何通过轻易云数据集成平台,将汤臣倍健营销云的数据成功对接到SQL Server。本次分享的方案名称为“退货入库-四川绪泰”。
为了实现精准、高效的数据集成,本次任务主要涉及以下关键技术点:
-
调用汤臣倍健营销云接口 我们使用了API
/erp/api/order/query/saleReturnOrder来获取退货订单数据。这是整个数据流动开始的重要一步,通过设置定时任务,我们可以确保准时、可靠地抓取所需数据。 -
处理分页与限流问题 接口返回的数据可能会因为限流机制和大批量请求而分页。因此,在设计流程时,特别考虑到了接口的分页处理逻辑,以确保所有订单记录都能够被一一抓取,不遗漏任何单据。
-
自定义数据转换逻辑 针对从汤臣倍健营销云获取到的数据,与SQL Server目标表结构之间存在差异的问题,我们设计了一套自定义的数据转换规则。这个过程不仅包括字段映射,还涉及复杂的业务逻辑处理,如状态转码等。
-
实时监控与日志记录 在整个集成过程中,借助平台提供的集中监控和告警系统,我们能够实时跟踪每个步骤的执行情况。一旦出现异常,可以及时捕获并启动错误重试机制。这极大提高了系统运行过程中的稳定性和可维护性。
-
批量写入至 SQL Server 为了提升写入效率,对获取的大量订单数据进行合理分组,并采用批量操作方式通过
insertAPI 写入到SQL Server中。不仅提高了整体性能,也减少了数据库连接次数,减轻负载压力。
接下来,让我们逐步拆解这一方案,从API调用,到分页处理,再到最终写回数据库,每一个环节都会详细阐述其技术细节及注意事项。
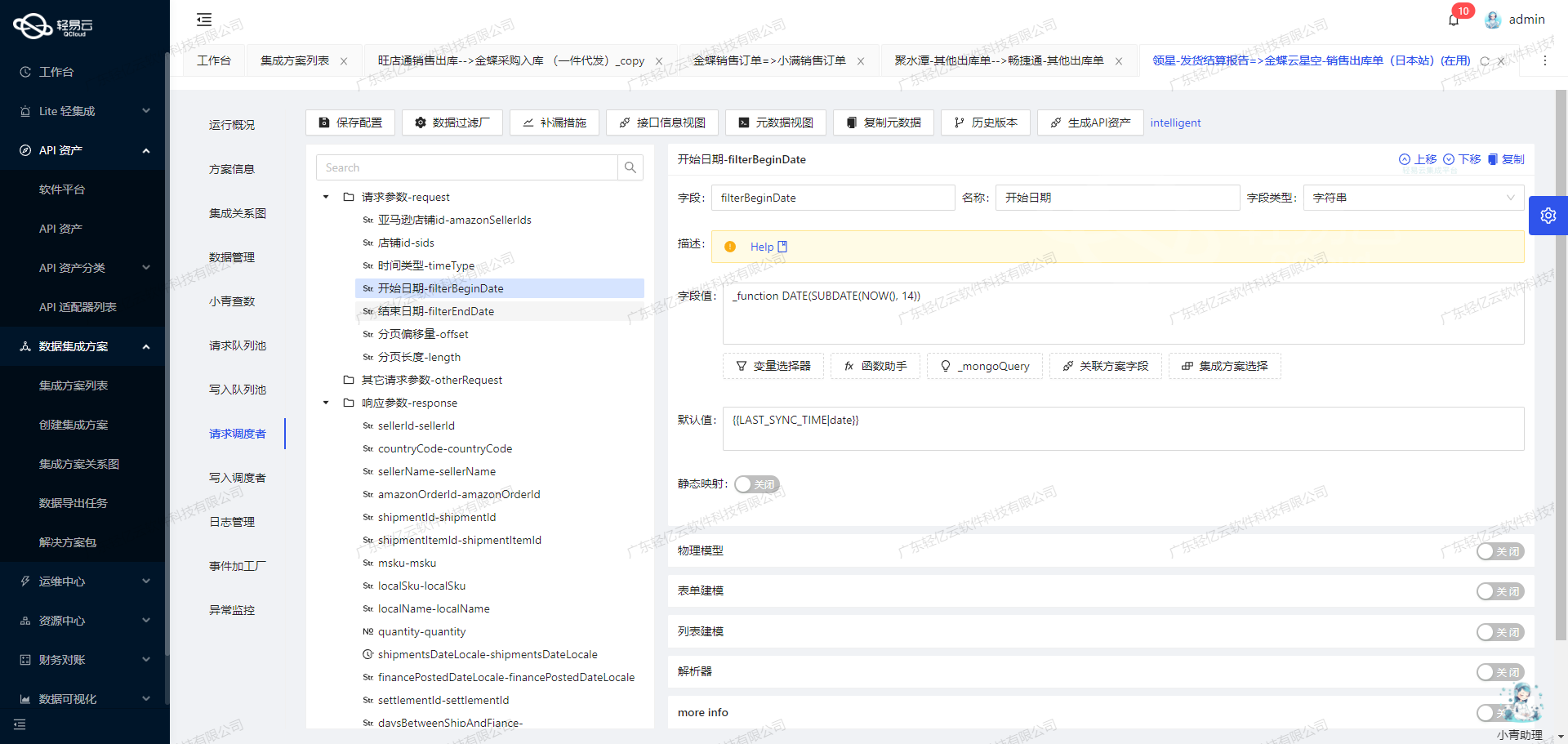
调用源系统汤臣倍健营销云接口/erp/api/order/query/saleReturnOrder获取并加工数据
在数据集成生命周期的第一步,我们需要调用汤臣倍健营销云的接口来获取退货入库相关的数据。本文将详细探讨如何通过轻易云数据集成平台配置元数据,调用该接口并进行初步的数据处理。
接口调用配置
首先,我们需要配置API调用的元数据。根据提供的metadata,接口路径为/erp/api/order/query/saleReturnOrder,请求方法为POST。以下是关键字段及其配置:
- tenantId: 经销商ID,是必填项。例如:
34cc4109705e4c058b7b3b0352e57d31 - yxyNumber: 营销云销售订单号,可选项。如果传递此参数,其他时间状态等条件无效。
- number: 系统订单号,可选项。如果传递此参数,其他时间状态等条件无效。
- status: 订单状态,默认值为
1(已审核)。 - beginTime: 开始时间,格式为
0000-00-00或0000-00-00 00:00:00。如果不传单号,此字段必填。 - endTime: 结束时间,格式同上。如果不传单号,此字段必填。
- pageNo: 页码,默认值为1。
- pageSize: 每页条数,默认值为30。
- timeType: 时间段标志,默认值为0(创建时间)。
以下是一个示例请求体:
{
"tenantId": "34cc4109705e4c058b7b3b0352e57d31",
"status": "1",
"beginTime": "{{LAST_SYNC_TIME|datetime}}",
"endTime": "{{CURRENT_TIME|datetime}}",
"pageNo": "1",
"pageSize": "100",
"timeType": "0"
}数据清洗与转换
在获取到原始数据后,我们需要对其进行清洗和转换,以便后续处理和存储。以下是一些常见的数据清洗与转换操作:
-
字段映射与重命名:将API返回的数据字段映射到目标系统所需的字段。例如,将API返回的
number字段重命名为目标系统中的订单编号。 -
数据类型转换:确保所有字段的数据类型符合目标系统要求。例如,将字符串类型的日期转换为日期类型。
-
缺失值处理:对于某些可能缺失的重要字段,需要进行填充或删除操作。例如,对于缺失的经销商ID,可以使用默认值或从其他数据源补充。
-
去重处理:确保没有重复记录,这通常通过检查唯一标识符(如订单ID)来实现。
以下是一个简单的数据清洗示例代码:
import pandas as pd
# 假设我们已经从API获取了原始数据
raw_data = [
{"id": "123", "number": "XOUT0000000293", "status": "1", "createTime": "2023-10-01 12:00:00"},
{"id": "124", "number": "XOUT0000000294", "status": "1", "createTime": "2023-10-01 13:00:00"}
]
# 转换为DataFrame
df = pd.DataFrame(raw_data)
# 字段重命名
df.rename(columns={"number": "order_number", "createTime": "created_at"}, inplace=True)
# 数据类型转换
df['created_at'] = pd.to_datetime(df['created_at'])
# 去重处理
df.drop_duplicates(subset=['id'], inplace=True)
print(df)实时监控与日志记录
为了确保数据集成过程的透明度和可追溯性,我们需要对每个步骤进行实时监控和日志记录。这包括:
- 请求日志:记录每次API请求的详细信息,包括请求体、响应时间和响应结果。
- 错误日志:记录任何发生的错误或异常情况,以便及时排查和解决问题。
- 处理日志:记录每次数据清洗与转换操作的详细信息,包括处理前后的数据状态。
通过这些日志记录,我们可以全面掌握整个数据集成过程,从而快速定位和解决问题,提高整体效率。
以上就是调用汤臣倍健营销云接口获取并加工退货入库数据的详细技术案例。在实际应用中,根据具体业务需求,还可以进一步优化和扩展这些操作。
使用轻易云数据集成平台进行ETL转换并写入SQL Server API接口
在数据集成生命周期的第二阶段,我们需要将已经集成的源平台数据进行ETL(提取、转换、加载)处理,最终将其转为目标平台SQL Server API接口所能够接收的格式,并写入目标数据库。本文将详细介绍如何利用轻易云数据集成平台完成这一过程,重点探讨API接口和数据集成的技术细节。
元数据配置解析
首先,我们需要理解元数据配置中的各个字段及其作用。以下是一个典型的元数据配置示例:
{
"api": "insert",
"method": "POST",
"idCheck": true,
"request": [
{
"label": "主表参数",
"field": "main_params",
"type": "object",
"children": [
{"parent": "main_params", "label": "单号编号", "field": "djbh", "type": "string", "value": "{number}"},
{"parent": "main_params", "label": "采购入库传CGC 销售退回传XHH", "field": "djlx", "type": "string", "value": "XHH"},
{"parent": "main_params", "label": "日期", "field": "rq", "type": "string", "value": "{{auditTime|date}}"},
{"parent": "main_params", "label":"时间","field":"ontime","type":"string","value":"{{auditTime|time}}"},
{"parent":"main_params","label":"单位内码","field":"wldwid","type":"string","value":"{extCusCode}"},
{"parent":"main_params","label":"含税金额","field":"hsje","type":"string","value":"{{itemList.taxlastmoney}}"},
{"parent":"main_params","label":"备注","field":"beizhu","type":"string","value":"{remark}"},
{"parent":"main_params","label":"原始单号","field":"webdjbh","type":"string","value":"{othernumber}"}
]
},
{
...
}
],
...
}该配置定义了向SQL Server插入数据时所需的参数和结构。主要分为主表参数和扩展表参数两部分。
主表参数
主表参数包含了基本的订单信息,如单号编号、类型、日期、时间等。这些字段在ETL过程中需要从源系统的数据中提取并转换为目标系统所需的格式。例如:
djbh:单号编号,直接从源系统字段number映射。djlx:单据类型,固定值“XHH”表示销售退回。rq和ontime:分别表示日期和时间,通过模板语言将审核时间(auditTime)格式化为日期和时间字符串。wldwid:单位内码,从源系统字段extCusCode映射。hsje:含税金额,从商品列表中的最后金额字段映射。beizhu:备注,从源系统字段remark映射。webdjbh:原始单号,从源系统字段othernumber映射。
扩展表参数
扩展表参数用于记录订单明细信息,包括商品内码、仓库编号、批号、数量等。这些信息通常以数组形式存在,需要逐项处理。例如:
spid:商品内码,通过查找集合中的商品编码(extMaterialNo)获取对应的商品ID。ckid: 仓库编号,从商品列表中的仓库编号字段映射。pihao: 批号,从商品列表中的批号字段映射。shl: 数量,从商品列表中的操作数量字段映射,且要求数量大于0。
SQL语句配置
为了将转换后的数据写入SQL Server,我们需要定义相应的SQL语句:
{
...
"otherRequest":[
{
...
{
label: '主SQL语句',
field: 'main_sql',
type: 'string',
value: 'INSERT INTO gxkphz (djbh,djlx,rq,ontime,wldwid,hsje,beizhu,webdjbh) values ( :djbh,:djlx,:rq,:ontime,:wldwid,:hsje,:beizhu,:webdjbh)'
},
{
label: '扩展SQL语句1',
field: 'extend_sql_1',
type: 'string',
value: 'INSERT INTO gxkpmx (djbh,dj_sn,spid,ckid,pihao,sxrq,baozhiqi,shl,hshj,hsje,xgdjbh,recnum,hzid,ckname) values ( :djbh,:dj_sn,:spid,:ckid,:pihao,:sxrq,:baozhiqi,:shl,:hshj,:hsje,:xgdjbh,:recnum,:hzid,:ckname)'
}
}
],
...
}这些SQL语句用于将主表和扩展表的数据插入到目标数据库中。每个占位符(如:djbh, :djlx, 等)对应于前面定义的参数字段。
数据转换与写入流程
- 提取数据:从源系统中提取原始数据,包括订单基本信息和明细信息。
- 转换数据:根据元数据配置,将提取的数据转换为目标格式。例如,将审核时间格式化为日期和时间字符串,将商品编码转换为商品ID等。
- 生成SQL语句:使用转换后的数据填充预定义的SQL语句,占位符替换为实际值。
- 执行写入操作:通过API接口调用,将生成的SQL语句发送到目标SQL Server数据库,完成数据写入操作。
通过以上步骤,我们可以高效地完成从源平台到目标平台的数据ETL转换,并确保每个环节都透明可控,实现不同系统间的数据无缝对接。
