MySQL数据集成到金蝶云星空案例分享:MOM-物料成本核算单-修改-OK-新版
在本次技术案例中,我们将重点探讨如何利用轻易云的数据集成平台,完成MySQL数据库中的物料成本核算单数据高效、准确地传输到金蝶云星空系统。该集成方案的具体名称为“MOM-物料成本核算单-修改-OK-新版”,旨在实现批量数据的快速写入,同时确保数据不漏单,并提供实时监控和异常处理机制,有效解决分页和限流问题。
首先,通过MySQL API接口select从源库获取所需业务数据。为了保证高吞吐量的数据写入能力,我们使用了多线程并发读取方式,从而提升了整体效率。此外,通过定时任务抓取MySQL接口的数据,确保所有新增或变更的记录都能及时同步到目标系统。
接下来是我们关注的重头戏——如何将大量处理后的数据无缝对接至金蝶云星空。在这一过程中,统一API资产管理功能发挥了重要作用,它通过统一视图和控制台帮助我们全面掌握API使用情况,实现资源的高效利用和优化配置。同时,为应对两者之间可能存在的数据格式差异,我们应用了自定义的数据转换逻辑,以适应特定的业务需求。
针对金蝶云星空的数据写入操作,本案例采用其提供的批量保存接口——batchSave。这不仅极大简化了代码复杂度,也显著提高了操作性能。为了确保可靠性,每一个写入过程都有集中监控与告警系统支撑,当出现异常时能够第一时间触发告警并进行重试机制处理,最大程度上降低因网络波动或其他非预期因素导致的数据丢失风险。
此外,在整个流程中,对实际运行状态及性能参数进行实时跟踪,并通过日志记录来持续监督操作进展。因此,一旦发现任何异常现象,可以迅速响应并执行相应调优措施,使得我们的每一次任务执行都处于受控状态内,高度保障项目顺利运行。
综上所述,此配置方案有效利用轻易云平台的一系列优势特性,不仅简化且加速了MySQL到金蝶云星空的集成过程,还极大提升整个业务链条上的透明度和可靠性,为后续进一步拓展奠定坚实基础。在下一部分内容中,将详细展示具体实施步骤及关键实现细节。
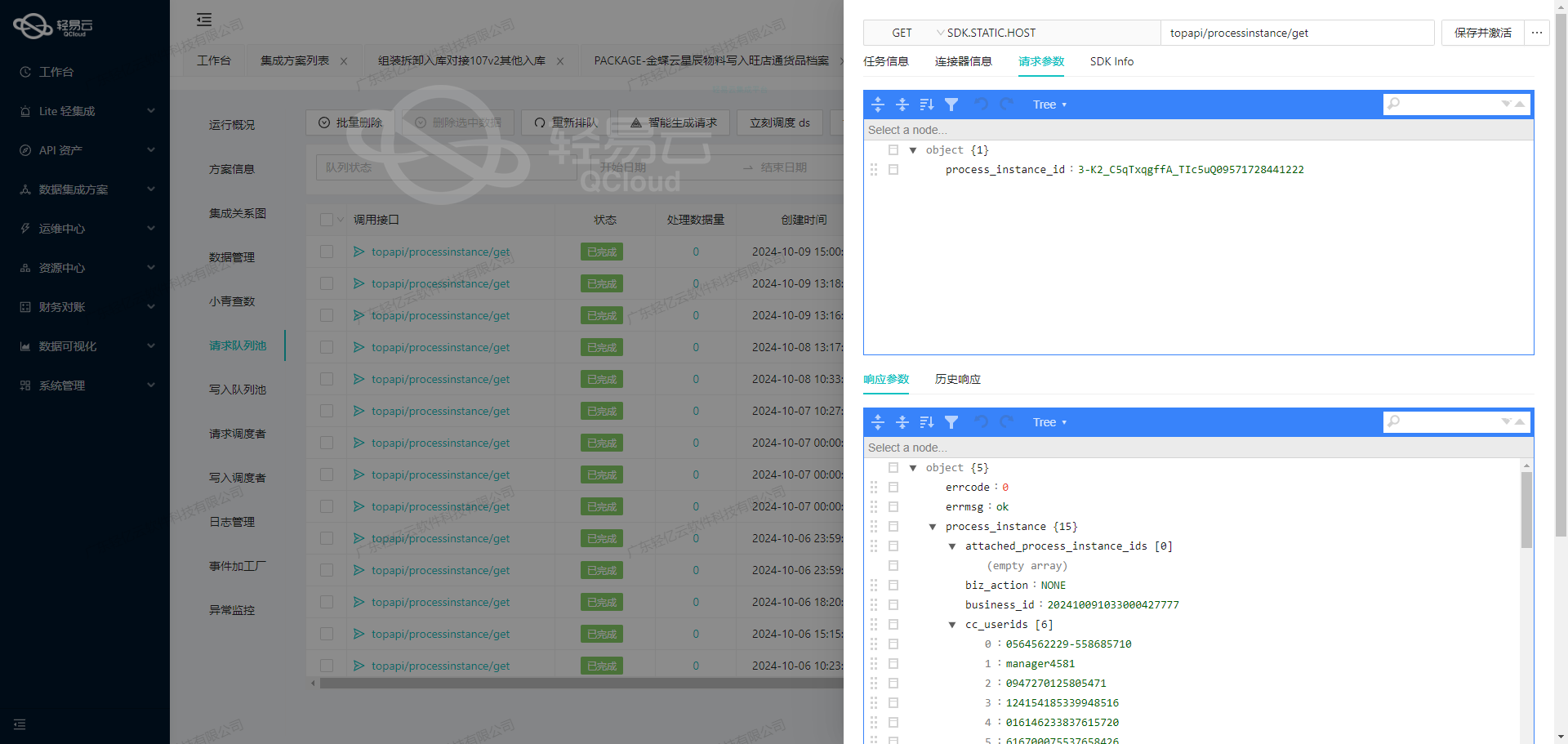
使用轻易云数据集成平台调用MySQL接口获取并加工数据
在数据集成的生命周期中,第一步是从源系统获取数据并进行初步加工。本文将深入探讨如何使用轻易云数据集成平台调用MySQL接口,通过select语句获取所需的数据,并进行必要的处理。
元数据配置解析
元数据配置是实现数据集成的关键,它定义了如何从源系统请求数据以及如何处理这些数据。以下是我们使用的元数据配置:
{
"api": "select",
"effect": "QUERY",
"method": "POST",
"id": "HEADER_ID",
"request": [
{
"field": "main_params",
"label": "main_params",
"type": "object",
"describe": "111",
"children": [
{
"field": "limit",
"label": "limit",
"type": "string",
"value": "2000"
},
{
"field": "offset",
"label": "offset",
"type": "string"
}
]
}
],
"otherRequest": [
{
"field": "main_sql",
"label": "main_sql",
"type": "string",
"describe": "111",
"value":
"\nSELECT \n CONCAT('',a.HEADER_ID) as HEADER_ID,\n CASE\n\ta.site_id \n\tWHEN 8001 THEN\n\t'T02' ELSE 'T02.01' \nEND AS ORG, \nc.MATERIAL_CODE, \na.total_cost, \nb.bom_name, \na.price, \na.MATERIAL_COST,\na.ATTRITION_CHANCE,\na.PACKAGE_LABEL, \na.ASSEMBLE_TIME, \na.untaxed_amount, \na.tax_amount, \nd.PRODUCT_BRAND,\nd.PRODUCT_MODEL,\nd.PRODUCT_PRICE,\na.tax_amount/d.PRODUCT_PRICE*100 as F_MProportion\nFROM \nty_report.hme_cost_acc_header a \nLEFT JOIN tarzan_method.mt_bom b ON a.bom_id = b.bom_id \nLEFT JOIN tarzan_method.mt_material c ON a.material_id = c.material_id \nLEFT JOIN ( \n SELECT header_id, PRODUCT_BRAND, PRODUCT_MODEL, PRODUCT_PRICE \n FROM ty_report.hme_cost_acc_product \n GROUP BY header_id \n ORDER BY product_id DESC \n) d ON d.header_id = a.HEADER_ID \nWHERE a.status='3' and a.sync_kingdee='1'\nand a.last_update_date>='{{LAST_SYNC_TIME|datetime}}'\n limit :limit offset :offset"
}
],数据请求与清洗
在这一阶段,我们通过POST方法向MySQL数据库发送查询请求。请求参数包括limit和offset,用于控制返回结果的数量和起始位置。这些参数可以动态调整,以便分页获取大量数据。
"request":[
{
...
{
field: 'limit',
label: 'limit',
type: 'string',
value: '2000'
},
{
field: 'offset',
label: 'offset',
type: 'string'
}
}
]通过上述配置,我们可以灵活地控制每次查询返回的数据量,确保系统资源的高效利用。
SQL查询语句解析
核心部分是SQL查询语句,它决定了从数据库中提取哪些字段以及如何进行初步的数据加工。以下是主要的SQL查询片段:
SELECT
CONCAT('',a.HEADER_ID) as HEADER_ID,
CASE
a.site_id
WHEN 8001 THEN
'T02' ELSE 'T02.01'
END AS ORG,
c.MATERIAL_CODE,
a.total_cost,
b.bom_name,
a.price,
a.MATERIAL_COST,
a.ATTRITION_CHANCE,
a.PACKAGE_LABEL,
a.ASSEMBLE_TIME,
a.untaxed_amount,
a.tax_amount,
d.PRODUCT_BRAND,
d.PRODUCT_MODEL,
d.PRODUCT_PRICE,
a.tax_amount/d.PRODUCT_PRICE*100 as F_MProportion
FROM
ty_report.hme_cost_acc_header a
LEFT JOIN tarzan_method.mt_bom b ON a.bom_id = b.bom_id
LEFT JOIN tarzan_method.mt_material c ON a.material_id = c.material_id
LEFT JOIN (
SELECT header_id, PRODUCT_BRAND, PRODUCT_MODEL, PRODUCT_PRICE
FROM ty_report.hme_cost_acc_product
GROUP BY header_id
ORDER BY product_id DESC
) d ON d.header_id = a.HEADER_ID
WHERE
a.status='3' and a.sync_kingdee='1'
and a.last_update_date>='{{LAST_SYNC_TIME|datetime}}'
limit :limit offset :offset该查询语句包含多个表的连接操作(JOIN),并使用了条件过滤(WHERE)来确保只提取符合特定条件的数据。此外,还进行了字段转换和计算,如将税额与产品价格相除以计算比例(F_MProportion)。
自动填充响应与补救机制
为了确保数据请求的完整性和准确性,平台提供了自动填充响应功能(autoFillResponse)和遗漏补救机制(omissionRemedy)。这些机制可以在出现异常或遗漏时自动采取补救措施,例如通过定时任务重新发起请求。
"autoFillResponse": true,
"omissionRemedy":{
...
}通过这些配置,可以大大提高数据集成过程的可靠性和稳定性。
实际应用案例
假设我们需要从MySQL数据库中提取物料成本核算单的数据,并对其进行初步加工。我们可以按照上述元数据配置进行设置,并执行以下步骤:
- 配置API请求参数,包括
limit和offset。 - 编写并测试SQL查询语句,确保能够正确提取所需字段。
- 启用自动填充响应和遗漏补救机制,确保在出现异常时能够自动恢复。
通过这些步骤,我们可以高效地从源系统获取并加工所需的数据,为后续的数据转换与写入阶段奠定坚实基础。
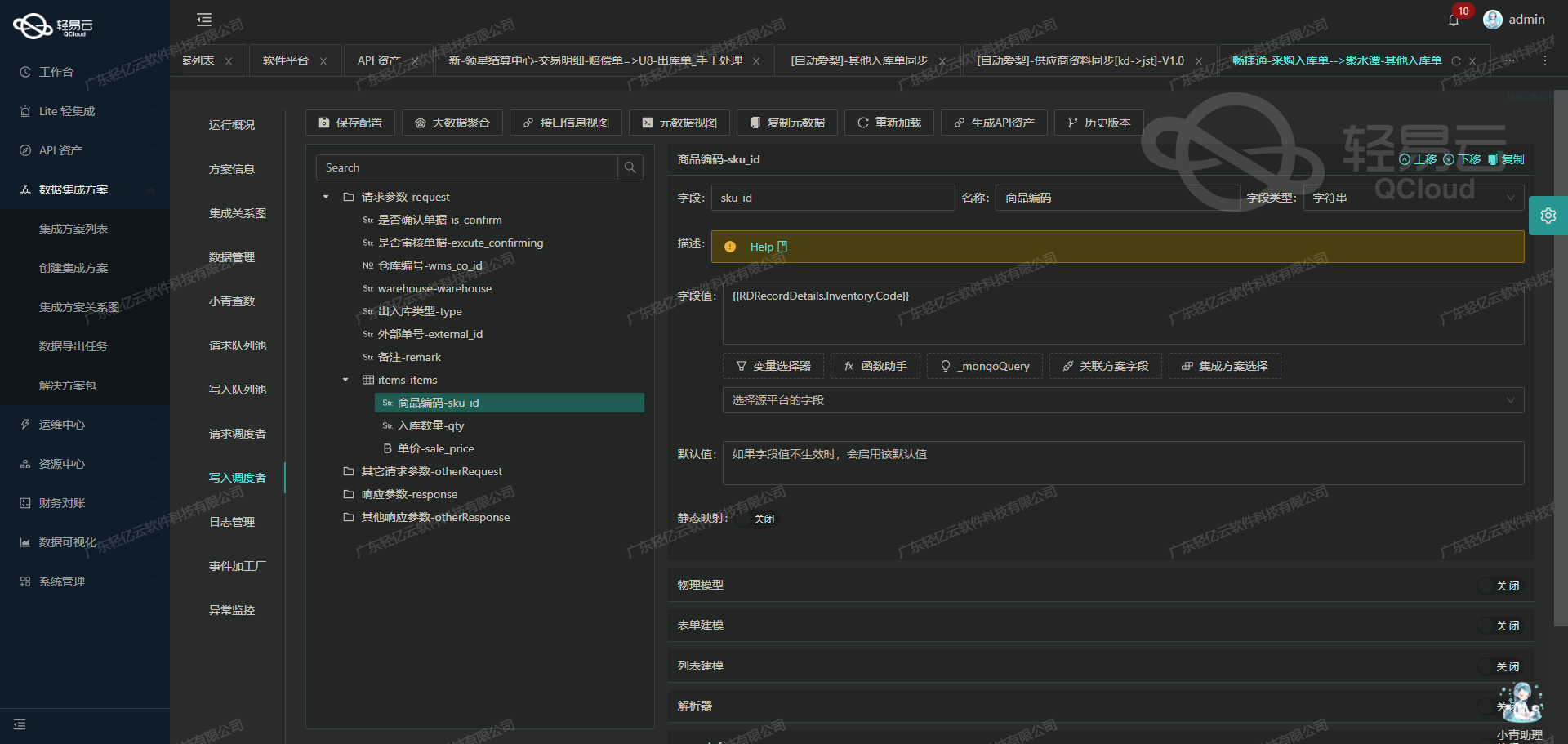
使用轻易云数据集成平台将源数据转换并写入金蝶云星空API接口的技术案例
在数据集成生命周期的第二步中,我们需要将已经集成的源平台数据进行ETL转换,并转为目标平台金蝶云星空API接口所能够接收的格式,最终写入目标平台。本文将详细探讨如何通过配置元数据实现这一过程。
API接口配置
首先,我们需要了解金蝶云星空API接口的基本配置。根据元数据配置,我们使用的是batchSave API,采用POST方法进行数据提交,并且在请求中包含多个字段。以下是关键字段及其配置:
- FID: 通过
_findCollection函数从指定ID中查找,并根据物料编码(MATERIAL_CODE)获取对应的FID。 - F_OrgId: 组织ID,通过
ConvertObjectParser解析器转换为FNumber格式。 - F_Materialid: 成品编码,同样通过
ConvertObjectParser解析器转换为FNumber格式。 - F_BOMID: BOM版本,通过解析器进行转换。
- F_SUMAMOUNT: 总成本,直接从源数据中的total_cost字段获取。
- F_MPRICE: 面价,直接从源数据中的price字段获取。
- F_UntaxedAMOUNT: 未税审核成本,从untaxed_amount字段获取。
- F_TaxAMOUNT: 含税审核成本,从tax_amount字段获取。
- F_ora__OraPinPa: 竟品品牌,从PRODUCT_BRAND字段获取。
- F_oraPrice: 竟品面价,从PRODUCT_PRICE字段获取。
- F_OraSpec: 竟品规格,从PRODUCT_MODEL字段获取。
- F_MProportion: 含税成本占竞品面价1的比率,从F_MProportion字段获取。
其他请求参数包括业务对象表单Id、执行操作类型、是否自动提交并审核、验证基础资料等,这些参数确保了操作的正确性和完整性。
数据转换与写入
在轻易云数据集成平台中,我们可以通过以下步骤完成数据转换与写入:
-
定义请求结构 根据元数据配置,定义请求结构。每个字段都需要按照上述配置进行映射和转换。例如:
{ "FormId": "kb18628e4a5cd41609782b5678d51a6a1", "Operation": "BatchSave", "IsAutoSubmitAndAudit": false, "IsVerifyBaseDataField": true, "IsDeleteEntry": false, "Model": { "FID": "_findCollection find FID from 6a63c600-37b9-3e3e-acb7-f9a06374c83e where F_Materialid={MATERIAL_CODE}", "F_OrgId": "{ORG}", "F_Materialid": "{MATERIAL_CODE}", ... } } -
使用解析器 对于需要解析的字段,如组织ID和成品编码,通过
ConvertObjectParser解析器进行转换:{ "field": "F_OrgId", "label": "组织", "type": "string", "value": "{ORG}", "parser": { "name": "ConvertObjectParser", "params": "FNumber" } } -
构建POST请求 将所有参数组装成一个完整的POST请求,并发送到金蝶云星空API接口:
{ "api": "/k3cloud/Kingdee.BOS.WebApi.ServicesStub.DynamicFormService.BatchSave", "method": "POST", ... } -
处理响应 接收并处理API响应,根据返回结果判断操作是否成功,并进行相应处理。如果失败,则记录错误信息并重新尝试或通知相关人员。
技术要点总结
通过轻易云数据集成平台,我们能够高效地将源平台的数据进行ETL转换,并无缝对接到金蝶云星空API接口。这一过程不仅简化了复杂的数据处理流程,还提高了系统间的数据一致性和准确性。关键在于正确配置元数据,利用合适的解析器和请求结构,实现自动化的数据集成与写入。
以上技术案例展示了如何利用轻易云数据集成平台实现复杂的数据转换与写入,希望对实际项目中的应用有所帮助。