更新班牛货品:高效数据集成方案
在企业日常运营中,数据的及时更新和准确性至关重要。本文将分享一个具体的系统对接集成案例——如何通过轻易云数据集成平台,将班牛的数据高效地集成到班牛系统中,实现货品信息的实时更新。
本次方案名为“更新班牛货品”,旨在解决大量数据快速写入、定时可靠抓取以及处理接口分页和限流等问题。我们利用了轻易云平台的高吞吐量数据写入能力,使得大量货品数据能够迅速且准确地被集成到目标系统中,极大提升了数据处理的时效性。
为了确保每一条数据都不漏单,我们采用了集中监控和告警系统,实时跟踪任务状态和性能。同时,通过调用班牛提供的数据获取API(task.list)和数据写入API(task.update),实现了从源头到目标平台的数据无缝对接。此外,我们还特别关注了接口分页和限流问题,通过自定义的数据转换逻辑和异常处理机制,确保整个过程稳定可靠。
在实际操作中,我们使用可视化的数据流设计工具,对整个流程进行了直观管理。这不仅使得配置更加简便,也提高了整体效率。通过统一视图和控制台,企业可以全面掌握API资产的使用情况,实现资源的高效利用与优化配置。
接下来,我们将详细介绍具体实施步骤及技术要点,包括如何调用班牛接口、处理分页与限流、以及异常处理与错误重试机制等内容。
调用班牛接口task.list获取并加工数据
在数据集成的生命周期中,调用源系统接口是关键的第一步。本文将深入探讨如何通过轻易云数据集成平台调用班牛接口task.list,并对获取的数据进行加工处理。
接口配置与请求参数
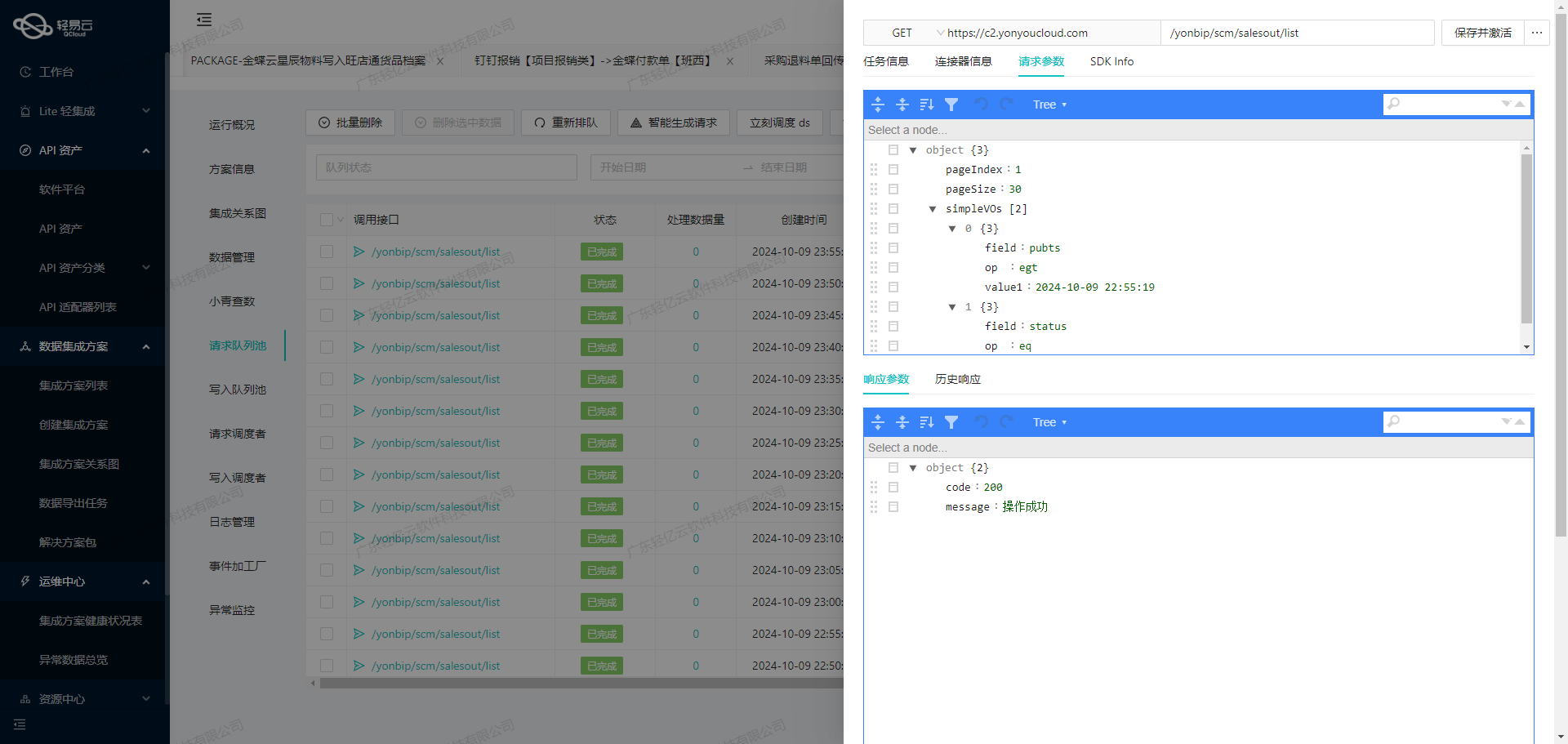
首先,我们需要了解task.list接口的元数据配置。该接口主要用于查询任务列表,支持多种查询条件和分页功能。以下是关键的请求参数:
project_id: 群组ID,用于指定查询范围。page_size: 每页返回记录数。page_num: 当前页码。star_created和end_created: 起始时间和结束时间,用于筛选创建时间范围内的任务。star_modified和end_modified: 修改时间起始和结束时间,用于筛选修改时间范围内的任务。task_status: 工作状态,用于筛选特定状态的任务。
这些参数可以灵活组合,以满足不同的数据查询需求。例如,通过设置star_modified为过去24小时,可以实现增量数据抓取。
数据请求与清洗
在轻易云平台上,我们可以通过可视化界面配置上述参数,并发起HTTP GET请求以获取班牛系统中的任务列表。以下是一个典型的请求示例:
GET /api/task.list?project_id=27912&page_size=100&page_num=1&star_modified=_function DATE_FORMAT(DATE_ADD(NOW(),INTERVAL - 24 HOUR),'%Y-%m-%d %H:%i:%s')&end_modified={{CURRENT_TIME|datetime}}成功获取数据后,需要对原始响应进行清洗和预处理。这包括但不限于:
- 字段映射:将班牛系统中的字段名映射到目标系统所需的字段名。例如,将
task_name映射为目标系统中的name。 - 格式转换:根据业务需求,对日期、数值等字段进行格式转换。例如,将日期格式从YYYY-MM-DD HH:mm:ss转换为ISO 8601标准。
- 异常处理:检测并处理异常数据,如缺失值或格式错误的数据条目。
分页与限流处理
由于班牛接口可能返回大量数据,分页机制至关重要。在每次请求中,通过调整page_num参数逐页获取数据,直到所有记录被完全抓取。同时,为避免触发API限流策略,应合理设置请求频率,并在必要时实现重试机制。
例如,在抓取第一页数据后,如果总记录数超过当前页大小,则继续抓取下一页:
page_num = 1;
do {
response = fetchData(page_num);
processResponse(response);
page_num++;
} while (response.hasMoreData());数据转换与写入
在完成数据清洗后,需要将其转换为目标系统所需的数据结构,并写入相应数据库或文件存储。这一步通常涉及复杂的数据映射和业务逻辑,例如:
- 根据业务规则合并或拆分记录。
- 应用自定义计算逻辑生成新的派生字段。
- 批量写入高吞吐量数据库,以确保性能和可靠性。
实时监控与日志记录
为了确保整个过程透明且可追溯,轻易云平台提供了实时监控和日志记录功能。通过集中式监控面板,可以实时查看每个集成任务的执行状态、性能指标以及潜在问题。此外,详细的日志记录有助于快速定位和解决故障,提高整体运维效率。
综上所述,通过合理配置元数据、精细化的数据清洗与转换,以及完善的分页、限流和监控机制,可以高效地调用班牛接口并加工处理数据,为后续的数据集成奠定坚实基础。
集成方案:更新班牛货品
在数据集成生命周期的第二步,我们需要将已经集成的源平台数据进行ETL转换,使其符合班牛API接口所能接收的格式,并最终写入目标平台。以下将详细探讨这一过程,重点关注如何配置和调用班牛API接口task.update。
数据转换与写入
在数据转换阶段,首先需要理解并解析源平台的数据结构。假设我们从一个MongoDB数据库中获取了原始数据,并且该数据包含了商品条码、商品编号等信息。接下来,我们需要将这些数据映射到班牛API所要求的字段格式。
元数据配置解析
根据提供的元数据配置,task.update接口需要以下几个关键字段:
app_id: 小程序IDproject_id: 群组IDtask_id: 工单IDcontents: 包含具体更新内容的对象,其中包括商品条码等信息
以下是对元数据配置中的关键部分进行详细解析:
{
"api": "task.update",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true,
"request": [
{"field":"app_id","label":"小程序id","type":"int","value":"17000"},
{"field":"project_id","label":"群组ID","type":"int","value":"27912"},
{"field":"task_id","label":"工单id","type":"int","value":"{{-1}}"},
{
"field": "contents",
"label": "contents",
"type": "object",
"children": [
{
"field": "101297",
"label": "商品条码",
"type": "string",
"value": "_mongoQuery a97d423e-52f5-3d6f-9f94-39a9f43f2bd5 findField=content.skuBarcode where={\"content.goodsNo\":{\"$eq\":\"{{27963}}\"}}"
}
]
}
]
}ETL转换步骤
-
提取数据:从源平台(如MongoDB)提取所需的数据。这里使用了一个MongoDB查询来获取商品条码:
"_mongoQuery a97d423e-52f5-3d6f-9f94-39a9f43f2bd5 findField=content.skuBarcode where={\"content.goodsNo\":{\"$eq\":\"{{27963}}\"}}"这段查询语句表示从MongoDB集合中查找
goodsNo等于特定值的文档,并提取其中的skuBarcode字段。 -
转换数据:将提取到的数据转换为班牛API接口所需的格式。例如,将MongoDB返回的数据结构化为符合班牛接口要求的JSON对象。
-
加载数据:通过HTTP POST请求,将转换后的数据发送到班牛API接口
task.update。确保请求体中的每个字段都符合接口规范。
调用班牛API接口
在调用班牛API时,需特别注意以下几点:
- 分页和限流处理:如果一次性要处理大量数据,应考虑分页处理和限流机制,以避免超出API限制。
- 错误处理与重试机制:实现可靠的数据写入,需要设计错误处理和重试机制。一旦请求失败,可以根据响应状态码决定是否重试或记录错误日志。
- 实时监控与日志记录:通过轻易云提供的监控和告警系统,实时跟踪任务状态,确保每个步骤都正常执行,并在出现问题时及时告警。
示例请求
假设我们已经完成了ETL转换,以下是一个示例请求体:
{
"app_id": 17000,
"project_id": 27912,
"task_id": -1,
"contents": {
"101297": "<已转换的商品条码>"
}
}通过HTTP POST请求将上述JSON对象发送至班牛API接口,即可完成数据写入操作。
数据质量监控与异常检测
在整个ETL过程中,必须持续监控数据质量。例如,通过校验规则确保商品条码等关键字段不为空且符合预期格式。一旦检测到异常,应立即记录并触发告警,以便及时处理。
自定义数据转换逻辑
针对特定业务需求,可以自定义复杂的数据转换逻辑。例如,如果源平台的数据格式与目标平台有较大差异,可以编写自定义脚本进行深度转换,以确保最终生成的数据完全符合班牛API要求。
通过以上步骤,我们可以高效地将源平台的数据经过ETL转换后成功写入班牛系统,实现不同系统间的数据无缝对接。这不仅提升了业务效率,也保证了数据的一致性和完整性。