旺店通·旗舰版数据集成到MySQL的技术案例分享
在大型企业的电商业务运营中,高效的数据处理和准确的数据存储至关重要。本案例将聚焦于通过轻易云数据集成平台,将旺店通·旗舰版系统中的入库瞬时成本数据无缝对接至MySQL数据库,为企业提供精准、实时的业务数据支持。
技术概述
为实现这一目标,我们采用了statistic.StockinCollect.queryCostWithDetail API接口,从旺店通·旗舰版获取入库瞬时成本明细,并使用MySQL API进行批量写入。以下是整个过程中的关键点:
-
API调用与分页处理
- 旺店通·旗舰版接口通常对单次请求返回的数据量有严格限制。因此,在调用
statistic.StockinCollect.queryCostWithDetail时,必须实现有效的分页机制,以确保所有相关数据均被完整提取,无一遗漏。
- 旺店通·旗舰版接口通常对单次请求返回的数据量有严格限制。因此,在调用
-
高吞吐量写入与性能优化
- 由于需要频繁地将大量数据写入到MySQL,我们必须优先考虑高吞吐量的批处理方法。利用轻易云平台强大的批量执行能力,通过
batchexecuteAPI实现快速、高效的数据存储操作。
- 由于需要频繁地将大量数据写入到MySQL,我们必须优先考虑高吞吐量的批处理方法。利用轻易云平台强大的批量执行能力,通过
-
异常检测和错误重试机制
- 在实际运行过程中,不可避免会出现网络抖动或API响应超时等情况,为此我们设计了完善的异常检测和错误重试机制,确保每条记录都能成功写入数据库,从而保证了整体流程的可靠性。
-
自定义转换逻辑与格式匹配
- 为适应特定业务需求,我们在流经各节点的数据之间设置特定自定义转换逻辑,以解决源端(旺店通·旗舰版)与目的端(MySQL)之间可能存在的数据结构差异问题。
-
集中监控与日志管理
- 实现全程透明化管理,通过配置集中化监控系统,对每个任务环节进行实时跟踪,并记录详细日志。这不仅帮助识别并诊断潜在问题,也为后续维护提供了充分依据。
通过上述技术要点,本案例展示了一种高效、稳健、安全的数据集成方案。在简述完基本框架后,后续部分我们会详细剖析具体实施步骤及其背后的核心原理。
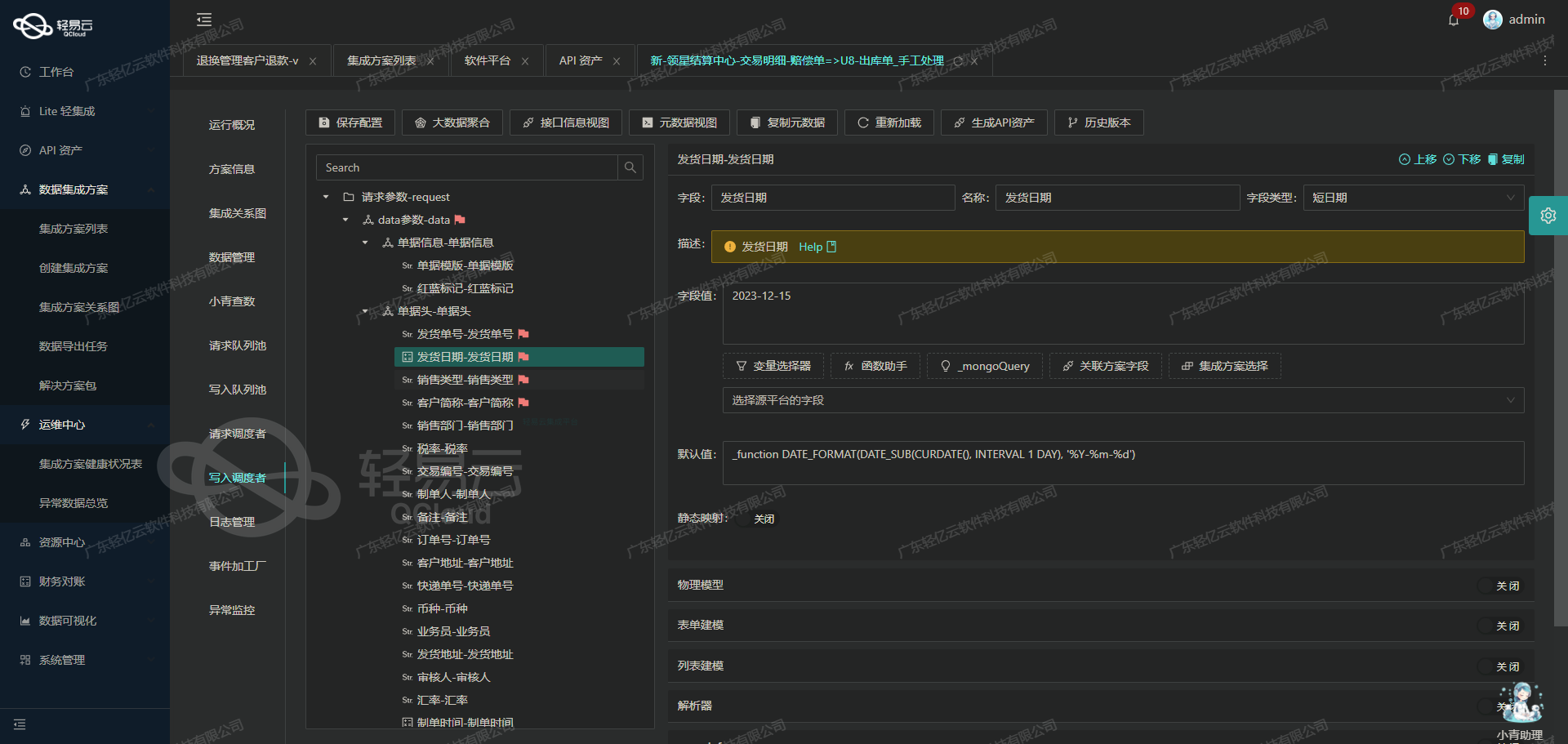
调用旺店通·旗舰版接口statistic.StockinCollect.queryCostWithDetail获取并加工数据
在数据集成生命周期的第一步中,调用源系统接口以获取数据是至关重要的。本文将深入探讨如何通过轻易云数据集成平台调用旺店通·旗舰版接口statistic.StockinCollect.queryCostWithDetail,并对获取的数据进行初步加工。
接口概述
接口statistic.StockinCollect.queryCostWithDetail用于查询入库瞬时成本的详细信息。该接口采用POST请求方式,支持多种查询参数和分页功能,能够高效地返回所需数据。
元数据配置详解
元数据配置是实现接口调用和数据处理的关键。以下是该接口的元数据配置解析:
{
"api": "statistic.StockinCollect.queryCostWithDetail",
"effect": "QUERY",
"method": "POST",
"number": "stockin_no",
"id": "stockin_id",
"name": "stockout_no",
"idCheck": true,
"request": [
{
"field": "params",
"label": "查询参数",
"type": "object",
"children": [
{"field": "start_time", "label": "开始时间", "type": "string", "value":"{{LAST_SYNC_TIME|datetime}}"},
{"field": "end_time", "label": "结束时间", "type": "string", "value":"{{CURRENT_TIME|datetime}}"},
{"field": "warehouse_no", "label": "仓库编号", "type": "string"},
{"field": "time_type",
"label":
"时间查询类型",
"type":"string",
"describe":"1:创建时间\n2:审核时间\n默认创建时间"
},
{"field":"stockin_no","label":"入库单号","type":"string","describe":"出库单号,多个入库单号之间英文逗号分隔"}
]
},
{
"field":"pager",
"label":"分页参数",
"type":"object",
"value":"50",
"children":[
{"field":"page_size","label":"分页大小","type":"string","value":"200"},
{"field":"page_no","label":"页号","type":"string"}
]
}
],
“autoFillResponse”:true,
“beatFlat”:[“detail_list”],
“delay”:300
}参数详解
-
params: 查询参数对象,包含以下字段:
start_time: 开始时间,格式为字符串,使用动态变量{{LAST_SYNC_TIME|datetime}}。end_time: 结束时间,格式为字符串,使用动态变量{{CURRENT_TIME|datetime}}。warehouse_no: 仓库编号,格式为字符串。time_type: 时间查询类型,格式为字符串,可选值为1(创建时间)和2(审核时间),默认值为创建时间。stockin_no: 入库单号,格式为字符串,可输入多个入库单号,以英文逗号分隔。
-
pager: 分页参数对象,包含以下字段:
page_size: 分页大小,格式为字符串,默认值为200。page_no: 页号,格式为字符串。
调用流程
- 构建请求体: 根据元数据配置构建POST请求体,包括查询参数和分页参数。
- 发送请求: 向接口发送POST请求,并传递构建好的请求体。
- 接收响应: 接收接口返回的数据,并根据配置中的
autoFillResponse自动填充响应内容。 - 处理响应: 对响应中的数据进行初步处理,如根据配置中的
beatFlat展开嵌套列表(如detail_list)。
数据清洗与转换
在接收到原始数据后,需要对其进行清洗与转换,以便后续的数据写入操作。以下是常见的数据清洗与转换步骤:
- 字段映射: 将原始字段映射到目标系统所需的字段。例如,将原始的
stockin_no映射到目标系统的入库单号字段。 - 数据过滤: 根据业务需求过滤不必要的数据。例如,只保留特定仓库编号的数据。
- 格式转换: 将日期、数值等字段转换为目标系统所需的格式。例如,将日期字符串转换为标准日期格式。
通过以上步骤,可以确保从旺店通·旗舰版获取的数据经过清洗与转换后能够顺利写入BI泰海系统,实现高效的数据集成。
实践案例
假设我们需要获取2023年10月1日至2023年10月31日期间某仓库(编号WH001)的所有入库瞬时成本信息,并将这些信息写入BI泰海系统。具体操作如下:
-
设置查询参数:
{ “params”: { “start_time”: “2023-10-01T00:00:00”, “end_time”: “2023-10-31T23:59:59”, “warehouse_no”: “WH001”, “time_type”: “1” }, “pager”: { “page_size”: “200”, “page_no”: “1” } } -
构建并发送POST请求:
POST /api/statistic.StockinCollect.queryCostWithDetail HTTP/1.1 Host: api.wangdiantong.com Content-Type: application/json Body: { ... } -
接收并处理响应:
{ “code”:0, “msg”:”success”, “data”:[ { ... } ] } -
清洗与转换数据,并写入BI泰海系统。
通过上述步骤,可以高效地实现从旺店通·旗舰版到BI泰海系统的数据集成,为业务决策提供准确及时的数据支持。

数据请求与清洗
在数据集成生命周期的第二步中,我们需要将已经从源平台(如旺店通旗舰版)获取并清洗的数据,转换为目标平台(如MySQL API接口)所能接收的格式,并最终写入目标平台。此过程涉及ETL(Extract, Transform, Load)操作中的Transform和Load两个部分。
ETL转换
首先,我们需要根据元数据配置,将源数据字段映射到目标数据字段。以下是元数据配置中定义的字段映射关系:
{
"field": "stockin_no",
"label": "入库单号",
"type": "string",
"value": "{stockin_no}"
},
{
"field": "stockin_id",
"label": "入库单id",
"type": "string",
"value": "{stockin_id}"
},
...每个字段都有其对应的标签、类型和值。我们需要确保这些字段在转换过程中保持一致,以便目标平台能够正确解析和存储数据。
SQL语句生成
根据元数据配置中的main_sql字段,我们可以生成用于插入数据的SQL语句:
REPLACE INTO stockincollect_querycostwithdetail(
stockin_no, stockin_id, src_order_id, flag_id, logistics_id, warehouse_id,
warehouse_no, warehouse_name, note_count, src_order_type, src_order_no,
status, operator_name, logistics_name, logistics_no, goods_count,
goods_type_count, remark, created, check_time, checked_goods_total_cost,
planned_goods_total_cost, modified, detail_list_rec_id,
detail_list_stockin_id, detail_list_num, detail_list_expire_date,
detail_list_goods_name, detail_list_goods_no, detail_list_short_name,
detail_list_spec_no, detail_list_spec_name, detail_list_spec_code,
detail_list_barcode, detail_list_defect, detail_list_checked_cost_price,
detail_list_total_checked_cost_price, detail_list_planned_cost,
detail_list_total_planned_cost, detail_list_position_no,
detail_list_batch_no, detail_list_production_date,
detail_list_weight, detail_list_goods_weight,
detail_list_unit_name ,detail_list_brand_name ,detail_list_spec_id ,
detail_list_goods_id ,detail_list_base_unit_id ,detail_list_unit_id ,
detail_list_num2 ,detail_list_brand_id ,detail_list_position_id ,
detail_list_expect_num ,detail_list_remark ,detail_list_unit_ratio ,
detail_list_validity_days
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?,
?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)数据映射与插入
在执行上述SQL语句时,需要将源数据中的值映射到相应的占位符中。例如:
PreparedStatement pstmt = connection.prepareStatement(sql);
pstmt.setString(1, sourceData.get("stockin_no"));
pstmt.setString(2, sourceData.get("stockin_id"));
...
pstmt.executeUpdate();这种方式确保了数据能够正确地插入到目标数据库中。
异常处理与日志记录
在实际操作中,可能会遇到各种异常情况,如网络中断、数据库连接失败等。因此,需要添加异常处理机制,并记录日志以便后续排查问题。例如:
try {
pstmt.executeUpdate();
} catch (SQLException e) {
logger.error("Failed to execute SQL: ", e);
}性能优化
为了提高性能,可以考虑批量插入数据。元数据配置中的limit字段定义了每次批量操作的最大记录数。在实际应用中,可以通过如下方式实现批量插入:
int batchSize = 1000;
int count = 0;
for (Map<String,String> record : records) {
pstmt.setString(1, record.get("stockin_no"));
...
pstmt.addBatch();
if (++count % batchSize == 0) {
pstmt.executeBatch();
connection.commit();
count = 0;
}
}
if (count > 0) {
pstmt.executeBatch();
}
connection.commit();总结
通过上述步骤,我们可以实现从源平台到目标平台的数据ETL转换和写入。这不仅保证了数据的一致性和完整性,还提高了系统的性能和稳定性。在实际应用中,根据具体需求和环境,可以进一步优化和调整相关配置和代码。