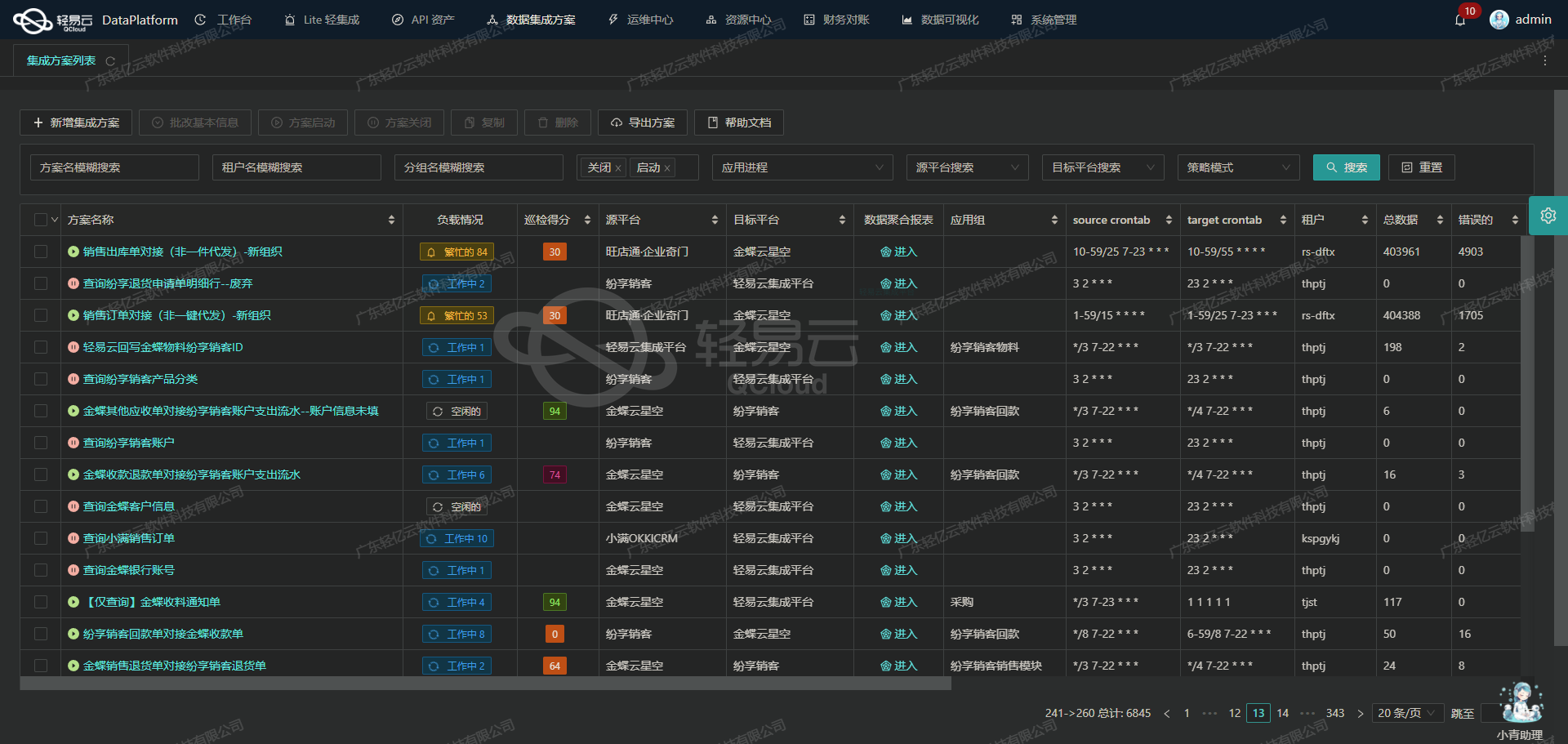
南方电网商城平台数据集成案例分享:售后取消
在南方电网商城平台上,高效、可靠的数据处理是保障售后业务顺利进行的关键。而为了实现这一目标,我们将其与轻易云数据集成平台进行了深度对接,专注于满足“售后取消”场景下的数据同步需求。本次技术案例将重点介绍我们如何通过设计和配置,确保数据从南方电网商城平台系统快速、准确地传输到轻易云集成平台,并在过程中完成各种自定义转换逻辑。
首先,在执行该方案时,我们需要处理大量来自南方电网商城的平台数据,这些数据通过API接口/o2pcm/v1/path/api/category/getByLevel进行定时抓取。为此,我们利用了轻易云集成平台的高吞吐量写入能力,使得这些大批量数据能够迅速且稳定地被导入,从而保证了实时性。
其次,为避免漏单问题及接口限流带来的风险,我们设置了一套细致的异常处理和错误重试机制。在每个监控点位都布设了实时跟踪与告警系统,一旦发现任何异动或故障,即可立刻响应并解决。这不仅提高了系统的健壮性,还增强了对整个流程透明度的掌握。
此外,当面对来自两个不同系统之间的数据格式差异时,我们采用了自定义数据转换逻辑,以确保所有进入轻易云集成平台的数据都是经过精确映射和校准后的结果。这使我们能灵活应对复杂多变的业务需求,同时也提升了整体效率。
最后,通过可视化工具直观设计的数据流,不仅使得整个实施过程变得更加明朗,也方便日后的维护和优化工作。客户团队可以通过统一视图全面掌握API资产使用情况,对资源进行有效管理,实现最佳性能表现。
本篇文章接下来将详细分析具体实施步骤,包括各项技术要点以及面临的问题解决之道,希望这份经验能为类似项目提供有益参考。
调用南方电网商城平台接口获取并加工数据的技术案例
在数据集成生命周期的第一步,调用源系统接口获取数据是至关重要的环节。本文将详细探讨如何通过轻易云数据集成平台调用南方电网商城平台接口/o2pcm/v1/path/api/category/getByLevel,并对获取的数据进行初步加工处理。
接口调用配置
首先,我们需要配置元数据以便正确调用南方电网商城平台的API接口。根据提供的元数据配置:
{
"api": "/o2pcm/v1/path/api/category/getByLevel",
"method": "POST",
"idCheck": true
}该配置表明我们需要使用POST方法调用/o2pcm/v1/path/api/category/getByLevel接口,并且需要进行ID校验。
数据请求与清洗
在轻易云数据集成平台上,我们可以通过以下步骤实现对该接口的数据请求与清洗:
-
创建API请求任务: 在轻易云平台上创建一个新的API请求任务,选择POST方法,并填写API路径为
/o2pcm/v1/path/api/category/getByLevel。 -
设置请求参数: 根据业务需求设置请求参数。例如,如果需要获取特定分类级别的数据,可以在请求体中添加相应的参数:
{ "level": 3 } -
ID校验: 配置ID校验逻辑,以确保每次请求的数据都是唯一且有效的。这可以通过在请求前后对比ID列表来实现,避免重复处理相同的数据。
-
发送请求并接收响应: 发送配置好的API请求,并接收返回的JSON格式响应数据。假设响应数据如下:
{ "status": "success", "data": [ {"id": 101, "name": "Category A", "level": 3}, {"id": 102, "name": "Category B", "level": 3} ] }
数据转换与写入
在接收到原始数据后,需要对其进行转换和清洗,以便后续处理和存储。以下是具体步骤:
-
解析JSON响应: 使用轻易云平台内置的JSON解析工具,将响应中的
data字段提取出来,形成一个列表对象。 -
数据清洗: 对提取出的数据进行初步清洗,例如去除无效字段、标准化字段名称等。可以通过编写自定义脚本或使用平台提供的可视化工具完成此操作。例如,将原始字段名转换为更符合内部规范的名称:
[ {"category_id": 101, "category_name": "Category A", "category_level": 3}, {"category_id": 102, "category_name": "Category B", "category_level": 3} ] -
转换格式: 根据目标系统要求,将清洗后的数据转换为目标格式。例如,如果目标系统要求CSV格式,可以将JSON对象列表转换为CSV字符串。
-
写入目标系统: 最后,将转换后的数据写入目标系统。这一步通常涉及到调用另一个API或直接写入数据库。在轻易云平台上,可以通过配置相应的数据写入任务来实现这一点。
实时监控与日志记录
为了确保整个过程顺利进行,实时监控和日志记录是必不可少的。在轻易云平台上,可以利用内置的监控工具实时查看API调用状态、数据流动情况以及处理进度。同时,通过日志记录功能,可以详细记录每一步操作,包括成功和失败的信息,以便于后续排查和优化。
通过上述步骤,我们能够高效地调用南方电网商城平台接口获取所需分类数据,并对其进行初步加工处理,为后续的数据集成工作打下坚实基础。
数据集成生命周期中的ETL转换与写入
在数据集成生命周期的第二步,我们将已经集成的源平台数据进行ETL(提取、转换、加载)处理,转为目标平台能够接收的格式,并最终写入目标平台。本文将详细探讨如何利用轻易云数据集成平台的API接口实现这一过程。
数据提取与清洗
在进行ETL转换之前,首先需要从源平台提取数据并进行清洗。这一步骤确保了数据的完整性和准确性,为后续的转换和写入打下基础。假设我们已经完成了这一阶段,接下来重点讨论如何将清洗后的数据转换为目标平台所需的格式,并通过API接口写入目标平台。
数据转换
数据转换是ETL过程中的关键环节。在这个阶段,我们需要根据目标平台的要求,对数据进行格式化和结构调整。以下是一个简单的数据转换示例:
def transform_data(source_data):
transformed_data = []
for record in source_data:
transformed_record = {
"id": record["source_id"],
"name": record["source_name"],
"status": "cancelled" if record["source_status"] == "inactive" else "active"
}
transformed_data.append(transformed_record)
return transformed_data在这个示例中,我们将源数据中的source_id、source_name和source_status字段转换为目标平台所需的id、name和status字段,并对状态值进行了相应的映射。
数据写入
完成数据转换后,我们需要将转换后的数据通过API接口写入目标平台。根据元数据配置,我们使用POST方法调用“写入空操作”API,并启用了ID检查功能。以下是一个Python代码示例,展示了如何实现这一过程:
import requests
import json
def write_to_target_platform(transformed_data):
api_url = "https://api.qingyiyun.com/write_empty_operation"
headers = {"Content-Type": "application/json"}
for record in transformed_data:
response = requests.post(api_url, headers=headers, data=json.dumps(record))
if response.status_code == 200:
print(f"Record {record['id']} written successfully.")
else:
print(f"Failed to write record {record['id']}. Status code: {response.status_code}")
# 示例源数据
source_data = [
{"source_id": 1, "source_name": "Item1", "source_status": "inactive"},
{"source_id": 2, "source_name": "Item2", "source_status": "active"}
]
# 数据转换
transformed_data = transform_data(source_data)
# 写入目标平台
write_to_target_platform(transformed_data)在这个示例中,我们首先定义了API URL和请求头,然后遍历转换后的每条记录,通过POST请求将其发送到目标平台。如果请求成功,则输出成功信息;否则,输出失败信息及状态码。
ID检查
元数据配置中启用了ID检查功能,这意味着在写入过程中需要确保每条记录都有唯一的ID。在实际应用中,可以通过数据库查询或其他方式来验证ID的唯一性。例如:
def check_unique_id(record_id):
# 假设有一个函数get_existing_ids()返回已存在的ID列表
existing_ids = get_existing_ids()
return record_id not in existing_ids
def write_to_target_platform_with_check(transformed_data):
api_url = "https://api.qingyiyun.com/write_empty_operation"
headers = {"Content-Type": "application/json"}
for record in transformed_data:
if check_unique_id(record["id"]):
response = requests.post(api_url, headers=headers, data=json.dumps(record))
if response.status_code == 200:
print(f"Record {record['id']} written successfully.")
else:
print(f"Failed to write record {record['id']}. Status code: {response.status_code}")
else:
print(f"Duplicate ID found for record {record['id']}. Skipping write operation.")
# 示例源数据、数据转换同上略
# 写入目标平台并进行ID检查
write_to_target_platform_with_check(transformed_data)在这个示例中,我们增加了一个ID检查函数,在写入之前验证每条记录的ID是否唯一。如果发现重复ID,则跳过该记录的写入操作。
通过上述步骤,我们可以高效地完成从源平台到目标平台的数据ETL转换与写入过程,确保数据的一致性和完整性。
