小满-宜搭供应商同步:实现高效的数据集成
在企业应用系统中,数据孤岛常常是阻碍业务流程顺畅和决策支持实时性的主要难题。针对这一痛点,小满OKKICRM与钉钉的对接集成应运而生。本次案例将分享如何通过轻易云数据集成平台,实现小满OKKICRM(以下简称“小满”)中的供应商信息无缝同步到钉钉。
系统对接方案概述
在本方案中,我们成功地配置了一个名为“小满-宜搭供应商同步”的数据集成项目,通过调用小满的接口/v1/supplier/list来获取供应商列表,再使用钉钉的API v1.0/yida/processes/instances/start进行批量写入。为了确保高效且可靠的数据传输,本方案涵盖了以下几个关键技术点:
1. 如何确保集成小满OKKICRM数据不漏单
为了避免遗漏任何一条关键业务数据,我们设计了一套完整的数据抓取与分发机制。采用增量式抓取策略并结合数据库记录更新标志,使得每次操作都能精准定位新增或修改过的信息。此外,加入重试机制以应对网络波动等异常情况,从而保证数据一致性。
2. 大量数据快速写入到钉钉
由于企业级应用经常涉及大量的数据交互,我们特别关注了如何优化大规模写入效率。在实际操作过程中,采取了适当的数据分片(chunking)以及并行处理方法,有效提升写入速度。同时,通过符合RESTful API最佳实践的方式,将多个请求汇聚为一次批处理提交,大幅减少网络开销。
3. 处理分页和限流问题
小满API接口存在分页限制,为此我们灵活运用自动分页处理逻辑,并在每次API调用时动态判断是否需要继续拉取后续页码,对于可能出现的限流情况,则提前设定休眠时间及缓冲措施,以此平滑应对API速率限制挑战。
请求与响应格式映射
考虑到两平台之间可能存在的数据格式差异,我们制定了一系列字段映射规则。例如,在从JSON解析阶段就进行了必要转换,以契合目标系统标准,同时保障原始数据信息完整保留。在具体实施过程中,还结合表单验证、数值校验等步骤进一步完善映射精度。这些准备工作奠定了稳健运行基础,大大降低了因格式错配带来的潜在风险。
通过以上多层面的技术手段整合,不仅解决了来源系统间的隔阂,也使得企业能够更好地利用
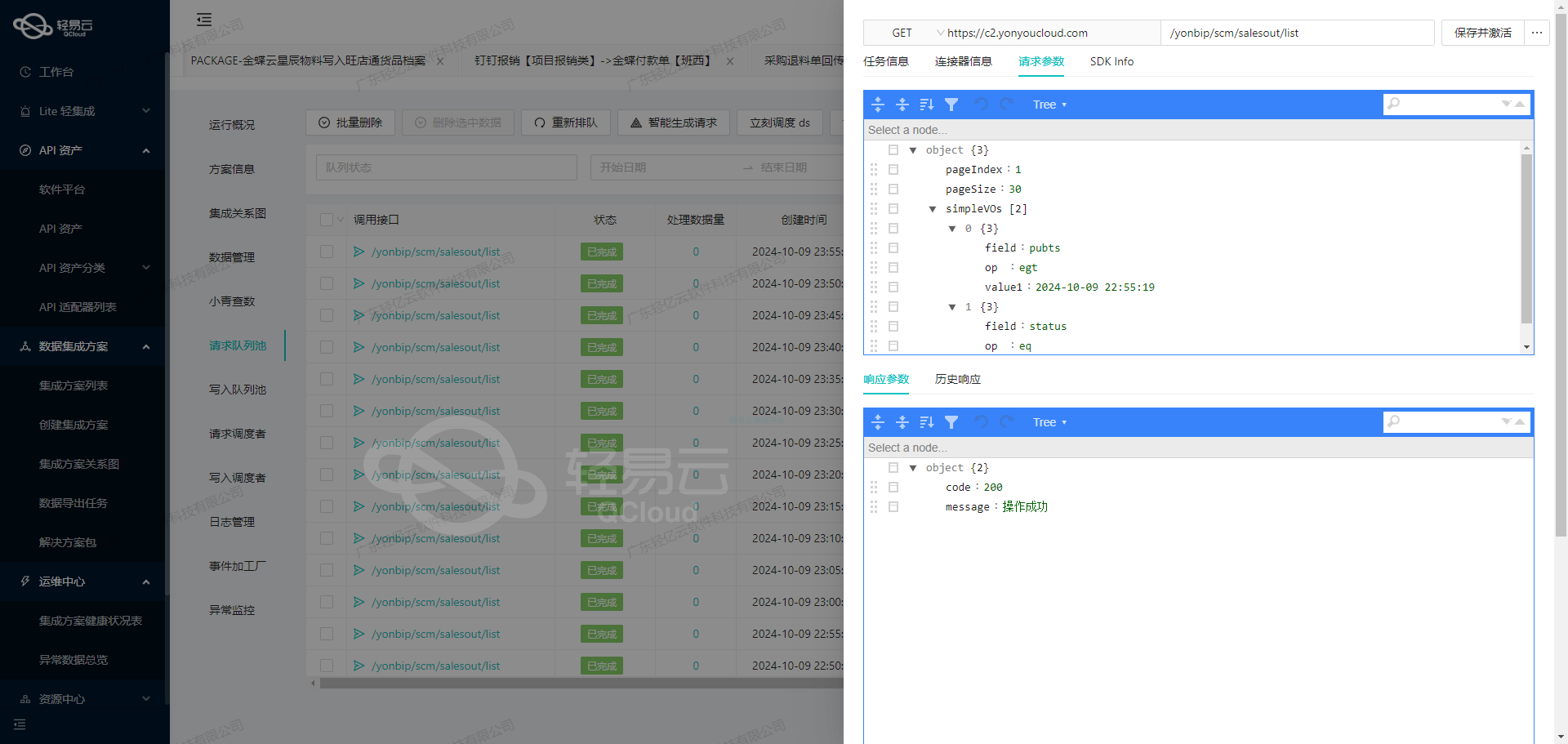
调用小满OKKICRM接口/v1/supplier/list获取并加工数据的技术案例
在数据集成过程中,调用源系统API接口是至关重要的一步。本文将深入探讨如何通过轻易云数据集成平台调用小满OKKICRM的/v1/supplier/list接口来获取供应商列表,并对数据进行初步加工。
接口调用配置
首先,我们需要配置元数据以便正确调用API接口。以下是关键的元数据配置项:
- API路径:
/v1/supplier/list - 请求方法:
GET - 主键字段:
supplier_id - 自动填充响应:
true
请求参数配置
在请求参数中,我们需要设置分页信息、时间范围以及是否查询已删除的数据。以下是具体的请求参数配置:
{
"request": [
{
"field": "start_index",
"label": "第几页",
"type": "string",
"describe": "第几页,默认 = 1",
"value": "1"
},
{
"field": "count",
"label": "每页记录数",
"type": "string",
"describe": "每页记录数,默认 = 20",
"value": "20"
},
{
"field": "is_delete",
"label": "是否查询已删除数据",
"type": "string",
"describe": "默认值: 0,设置=1时查询已删除的数据列表"
},
{
"field": "start_time",
"label": "开始日期",
"type": "datetime",
"value": "{{LAST_SYNC_TIME|datetime}}"
},
{
"field": "end_time",
"label": "结束日期",
"type": "datetime",
"value": "{{CURRENT_TIME|datetime}}"
}
]
}这些参数确保我们能够分页获取供应商列表,并且可以根据时间范围筛选数据。
数据清洗与转换
在获取到原始数据后,需要对其进行清洗和转换,以便后续处理。以下是一些常见的数据清洗与转换操作:
- 字段映射:将API返回的数据字段映射到目标系统所需的字段。例如,将
name映射为供应商名称,将supplier_id作为唯一标识。 - 去重处理:根据
supplier_id去重,确保每个供应商在目标系统中只有一条记录。 - 格式转换:将日期格式统一为目标系统所需的格式。
数据写入
经过清洗和转换后的数据需要写入目标系统。在此过程中,可以使用轻易云平台提供的其他API接口,例如详情接口/v1/supplier/info来补充更多详细信息。
{
"otherRequest": [
{
"field": "info_api",
"label": "详情接口",
"type": "string",
"value": "/v1/supplier/info"
},
{
"field": "info_key",
"label": "详情主键",
"type":"string",
### 使用轻易云数据集成平台将源数据转换并写入钉钉API接口
在数据集成的生命周期中,第二步至关重要,即将已经集成的源平台数据进行ETL转换,并转为目标平台钉钉API接口所能够接收的格式,最终写入目标平台。本文将深入探讨这一过程中涉及的技术细节和具体实现方案。
#### 针对钉钉API接口的数据转换
为了实现数据从源平台到钉钉API接口的无缝转换,我们需要遵循以下元数据配置:
```json
{
"api": "v1.0/yida/processes/instances/start",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true,
"request": [
{"field":"serialNumberField_lqomwdxk","label":"供应商编码","type":"string","value":"{supplier_id}"},
{"field":"textField_lq0sj9h9","label":"供应商名称","type":"string","value":"{name}"},
{"field":"textField_lqaefii2","label":"供应商简称","type":"string","value":"{{简称}}"},
{"field":"textareaField_lqaefiig","label":"供应商地址","type":"string","value":"{address}"},
{"field":"numberField_lqaefii8","label":"税点","type":"int","value":"_function REPLACE( '{{税点}}' , '%','' )"},
{"field":"textareaField_lqaefii6","label":"主营产品","type":"string","value":"{{主营产品}}"},
{"field":"textField_lqaefiik","label":"邮箱","type":"string","value":"{contact_list_email}"},
{"field":"textField_lqaefiih","label":"联系人姓名","type":"string","value":"{contact_list_contact_name}"},
{"field":"textField_lqaefiii","label":"手机/微信","type":"string","value":"{contact_list_phone}"},
{"field":"textField_lqaefiij","label":"QQ","type":"string","value":"{contact_list_social_platform}"},
{"field": "textField_lqd52lht", "label": "私户户名", "type": "string", "value": "{{私户户名}}"},
{"field": "textField_lqd52lhu", "label": "私户开户行", "type": "string", "value": "{{私户开户行}}"},
{"field": "textField_lqd52lhv", "label": "私户账号(银行、支付宝)", "type": "string", "value": "{{私户账号(银行、支付宝)}}"},
{"field": "textField_lqd52lhw", "label": "付款方式", "type": "string", "value": "{{付款方式}}"},
{"field": "selectField_lqaefiia", "label": "供应商评级", "type": "string",
"value": "{rate_id}",
"mapping":{"target" : "65f122cfc30d2b4ed30d4c7f" , "direction" : "positive"}
}
],
...
}数据字段映射与转换
-
字段映射:
serialNumberField_lqomwdxk映射到supplier_idtextField_lq0sj9h9映射到nametextareaField_lqaefiig映射到address- 等等...
-
数据类型转换:
- 税点字段需要去除百分号并转换为整数:
_function REPLACE( '{{税点}}' , '%','' )
- 税点字段需要去除百分号并转换为整数:
-
特殊处理:
- 对于需要进行特殊处理的字段,如税点,需要先进行字符串替换操作,然后再将其转换为整数类型。
请求参数配置
在发送请求时,需要确保以下参数被正确配置:
- 应用编码 (appType):
"APP_E4D9OR2HF7QLY167G75K" - 应用秘钥 (systemToken):
"CH766981N8RI4YCK9QDSUAGJLEPA2BCS0OWSLR" - 用户ID (userId):
"01252853342023385" - 语言 (language):
"zh_CN" - 表单ID (formUuid):
"FORM-8134252150A64670A2AA8F9B69BC92ADHPCQ"
这些参数确保了请求能够被正确识别和处理。
实现步骤
- 提取源数据:从源系统中提取原始数据。
- 数据清洗:根据需求对提取的数据进行清洗,如去除不必要的字符或空格。
- 字段映射与类型转换:按照元数据配置,将清洗后的数据映射到目标字段,并进行必要的类型转换。
- 构建请求体:根据上述映射和转换结果,构建符合钉钉API接口要求的请求体。
- 发送请求:使用POST方法,将构建好的请求体发送到指定API接口。
通过以上步骤,我们能够高效地将源平台的数据转换为钉钉API接口所能接收的格式,并成功写入目标平台。这不仅提升了数据处理效率,也确保了不同系统间的数据一致性和完整性。
