钉钉数据集成到MySQL:付款申请单的高效对接方案
在企业日常运营中,数据的高效流转和准确处理至关重要。本文将分享一个具体的系统对接集成案例,即如何通过轻易云数据集成平台,将钉钉中的付款申请单数据无缝集成到MySQL数据库中,实现从“钉钉-付款申请单”到“BI崛起-付款申请表”的高效转换。
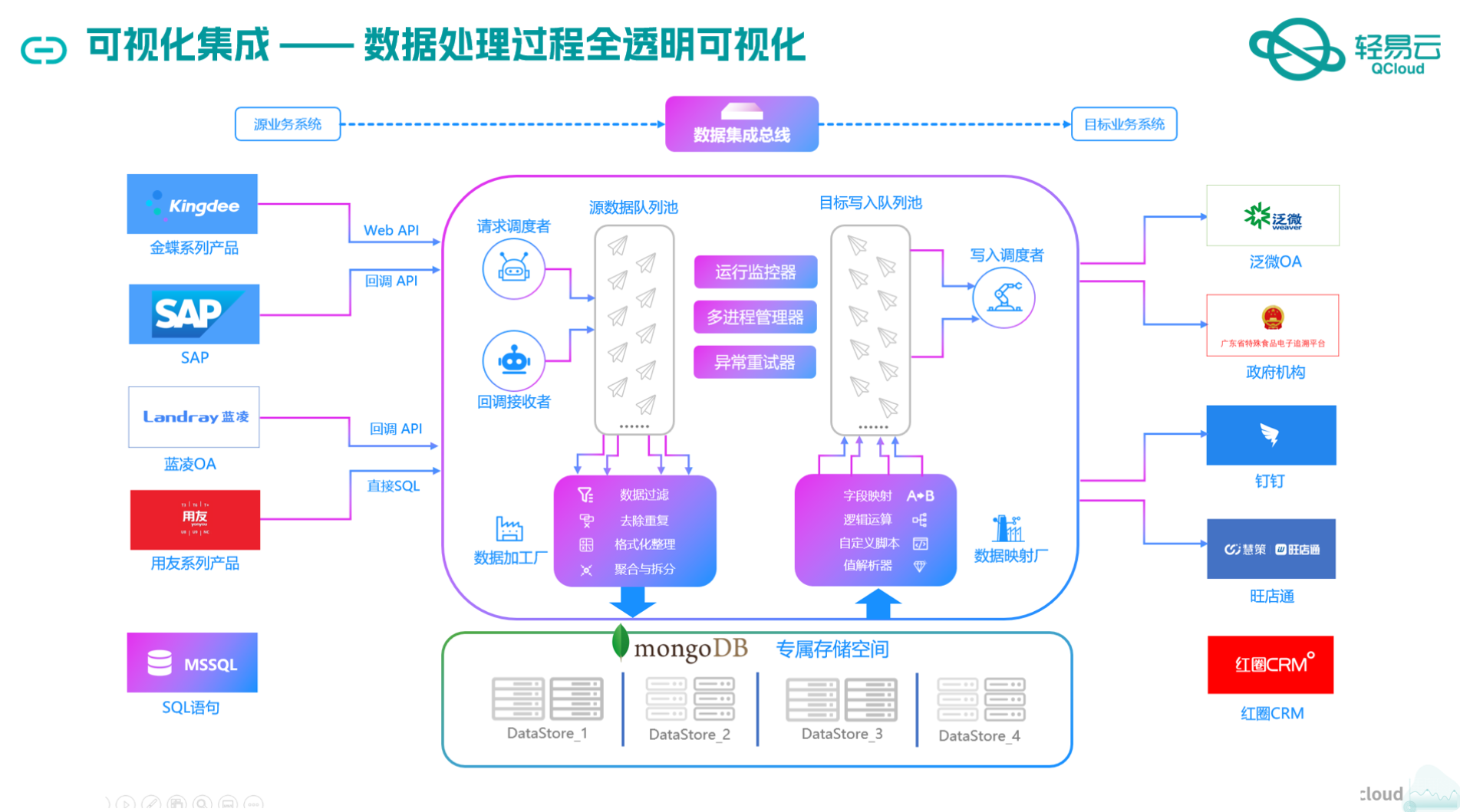
本次集成方案主要利用了轻易云平台的以下特性:
- 高吞吐量的数据写入能力:确保大量付款申请单数据能够快速被写入MySQL,提升整体处理时效性。
- 实时监控与告警系统:通过集中监控和告警功能,实时跟踪每个数据集成任务的状态和性能,及时发现并解决潜在问题。
- 自定义数据转换逻辑:适应特定业务需求,对钉钉接口返回的数据进行必要的格式转换,以符合MySQL数据库结构要求。
- 分页与限流处理:针对钉钉API接口(topapi/processinstance/get)的分页和限流机制进行优化处理,确保数据抓取过程稳定可靠。
- 异常处理与错误重试机制:在对接过程中,通过完善的异常处理和错误重试机制,提高系统的鲁棒性,避免因网络波动或其他原因导致的数据丢失。
通过这些技术手段,我们不仅实现了从钉钉到MySQL的数据无缝对接,还确保了整个流程的透明度和可控性,为企业提供了一套可靠、高效的数据集成解决方案。

调用钉钉接口topapi/processinstance/get获取并加工数据
在轻易云数据集成平台的生命周期中,调用源系统钉钉接口topapi/processinstance/get是关键的第一步。这个过程涉及从钉钉系统中提取付款申请单的数据,并进行初步的清洗和加工,以便后续的数据转换与写入操作。
配置元数据
首先,我们需要配置元数据来定义如何调用钉钉接口。以下是一个典型的元数据配置示例:
{
"api": "topapi/processinstance/get",
"effect": "QUERY",
"method": "POST",
"number": "number",
"id": "id",
"request": [
{
"field": "process_code",
"label": "审批流的唯一码",
"type": "string",
"describe": "这里填写钉钉表单的id",
"value": "PROC-6D095BC9-1E1B-4306-95EF-854971B52272"
},
{
"field": "start_time",
...
}
],
...
}数据请求与清洗
在实际操作中,调用API时需要传递多个参数,包括审批流的唯一码、时间戳、分页参数等。这些参数确保我们能够准确地获取所需的数据,并处理大批量的数据请求。
- 审批流唯一码:这是唯一标识特定审批流程的代码。在本例中,它被设置为
PROC-6D095BC9-1E1B-4306-95EF-854971B52272。 - 时间戳:使用Unix时间戳来指定查询范围内的开始和结束时间。通过函数动态生成这些值,例如
_function {LAST_SYNC_TIME}*1000和_function {CURRENT_TIME}*1000。 - 分页参数:为了处理大量数据,分页查询是必不可少的。每次请求最多返回20条记录,通过游标(cursor)控制分页。
数据转换与写入准备
在获取到原始数据后,需要对其进行初步清洗和转换。例如,将费用明细字段展平(beatFlat),以便后续处理更加方便。此外,还需要注意处理可能出现的数据格式差异和异常情况。
示例代码片段
def fetch_dingtalk_data(process_code, start_time, end_time, cursor=0):
payload = {
'process_code': process_code,
'start_time': start_time,
'end_time': end_time,
'size': 20,
'cursor': cursor
}
response = requests.post('https://oapi.dingtalk.com/topapi/processinstance/get', json=payload)
data = response.json()
# 初步清洗和展平费用明细
cleaned_data = clean_and_flatten(data['result']['list'])
return cleaned_data, data['result']['next_cursor']
# 清洗和展平函数示例
def clean_and_flatten(data_list):
flattened_list = []
for item in data_list:
flat_item = flatten_expense_details(item)
flattened_list.append(flat_item)
return flattened_list实时监控与日志记录
为了确保整个过程顺利进行,实时监控和日志记录至关重要。通过轻易云平台提供的集中监控系统,可以实时跟踪每个数据集成任务的状态,并及时发现和处理异常情况。
异常处理机制
在调用API过程中,可能会遇到各种异常,如网络超时、限流等。实现健壮的错误重试机制可以提高系统稳定性。例如,在遇到网络超时时,可以设置重试次数及间隔时间,以确保最终成功获取数据。
import time
def robust_fetch(process_code, start_time, end_time):
max_retries = 5
retries = 0
cursor = 0
while retries < max_retries:
try:
data, next_cursor = fetch_dingtalk_data(process_code, start_time, end_time, cursor)
process_data(data) # 对获取的数据进行进一步处理或存储
if not next_cursor:
break # 没有更多数据了,退出循环
cursor = next_cursor
except Exception as e:
retries += 1
time.sleep(2 ** retries) # 指数退避策略
if retries == max_retries:
log_error(f"Failed to fetch data after {max_retries} attempts")通过上述步骤,我们能够高效地从钉钉系统中提取并加工付款申请单的数据,为后续的数据转换与写入做好准备。这一过程不仅保证了数据的一致性和完整性,也提升了整体业务流程的透明度和效率。
钉钉付款申请单数据集成至MySQL的ETL转换及写入
在数据集成平台生命周期的第二步中,我们需要将从钉钉接口获取到的付款申请单数据进行ETL转换,并将其写入到目标平台MySQL中。以下是实现这一过程的详细技术步骤和注意事项。
数据请求与清洗
首先,通过调用钉钉接口topapi/processinstance/get获取付款申请单数据。该接口返回的数据通常包含多个字段,如申请单ID、所属部门、用途、预计付款日期、总额等。为了确保数据的完整性和准确性,需对这些原始数据进行清洗和预处理。
{
"bfn_id": "123456",
"department": "财务部",
"purpose": "办公设备采购",
"estimated_payment_date": "2023-10-01",
"total_amount": "5000",
...
}数据转换
在数据清洗之后,需要对数据进行ETL转换,以适应目标平台MySQLAPI接口所能接收的格式。在这个过程中,必须确保字段名称和数据类型与MySQL数据库中的表结构相匹配。例如,将bfn_id映射为数据库中的bfn_id字段,确保其类型为字符串。
元数据配置如下:
{
"field": "main_params",
"children": [
{"field": "bfn_id", "label": "id", "type": "string", "value": "{bfn_id}"},
{"field": "department", "label": "所属部门", "type": "string", "value": "{{所属部门}}"},
{"field": "purpose", "label": "用途", "type": "string", "value": "{{用途}}"},
...
]
}通过上述配置,可以将钉钉接口返回的数据字段逐一映射到MySQL表中的相应字段。
数据写入
经过转换后的数据,需要通过API接口写入到MySQL数据库中。为了提高写入效率和保证数据一致性,采用批量插入方式,同时处理分页和限流问题。
使用以下SQL语句进行批量插入操作:
REPLACE INTO payment_application_info
(bfn_id, department, purpose, estimated_payment_date, total_amount, payment_method, payee_name, payee_account, payee_bank, actual_payment_amount, details_of_purpose, other_expenses, amount, corresponding_subjects, create_time, finish_time, originator_userid, originator_dept_id, status, result, business_id, originator_dept_name, biz_action)
VALUES (:bfn_id,:department,:purpose,:estimated_payment_date,:total_amount,:payment_method,:payee_name,:payee_account,:payee_bank,:actual_payment_amount,:details_of_purpose,:other_expenses,:amount,:corresponding_subjects,:create_time,:finish_time,:originator_userid,:originator_dept_id,:status,:result,:business_id,:originator_dept_name,:biz_action);注意事项
- 分页处理:由于钉钉接口可能返回大量数据,需实现分页处理以避免超时或内存溢出问题。
- 限流控制:为防止API调用频率过高导致被限流,需设置合理的调用频率。
- 异常处理与重试机制:在写入过程中,如遇网络波动或数据库故障,应实现异常捕获并进行重试,以保证数据最终一致性。
- 实时监控与日志记录:通过集成平台提供的监控和告警系统,实时跟踪数据集成任务状态,并记录操作日志以便于后续审计和问题排查。
通过上述步骤,可以有效地将从钉钉获取到的付款申请单数据经过ETL转换后,成功写入到MySQL数据库中,实现不同系统间的数据无缝对接。这一过程不仅提高了数据处理效率,也确保了业务流程的连续性和可靠性。