案例分享:钉钉数据集成到MySQL在对账系统中的应用
在本文中,我们将探讨如何利用轻易云数据集成平台,将钉钉的数据有效地集成到MySQL数据库,特别是在对账系统供应商账号状态修改这一具体应用场景下的实现方案。通过该案例,我们重点关注高效的数据传输、实时监控及异常处理机制。
钉钉与MySQL API接口概述
本次集成任务涉及两个核心API接口。首先是从钉钉获取供应商账号状态数据的API(v1.0/yida/processes/instances),其次是向MySQL写入这些数据的API(execute)。这两个接口将在整个数据流动过程中起着关键作用。
数据质量与异常处理策略
为了确保从钉钉获取的数据准确无误,并快速写入至MySQL数据库,采用了以下几种技术手段:
- 高吞吐量和批量处理:支持大量数据快速批量写入到MySQL,有效提升了整体流程的时效性。
- 集中监控和告警系统:通过实时跟踪任务状态,发现并解决可能出现的问题,如网络波动或接口限流问题。
- 自定义转换逻辑:适应业务需求,对不同结构的数据进行格式转换,以符合目标数据库表结构要求。
技术实施细节
- 定时抓取与分页处理:配置定时任务以可靠地抓取并分页处理来自于钉钉的数据信息,从根本上避免漏单现象。
- 错误重试机制:遇到连接超时或者请求失败等情况,通过构建错误重试机制保证每条记录最终成功存储在MySQL中。
- 可视化设计工具的使用:利用可视化工具直观设计整个数据流,更加便捷地管理各个环节,提高维护效率。
接下来,我们将详细解析上述技术点在实际操作中的具体实现在后续内容中展示,包括代码示例和注意事项等。
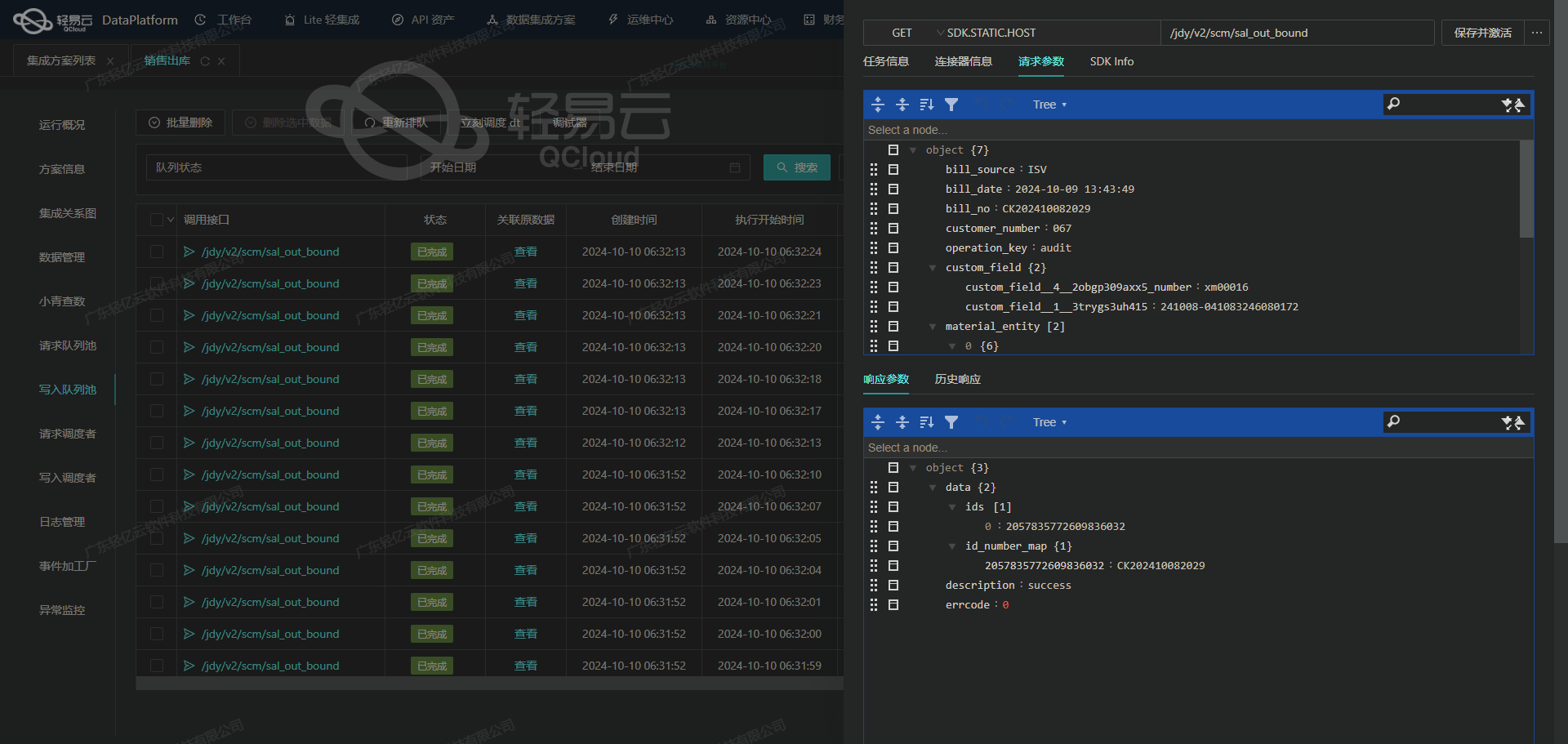
调用钉钉接口v1.0/yida/processes/instances获取并加工数据
在数据集成的生命周期中,调用源系统接口获取数据是至关重要的一步。本文将详细探讨如何通过钉钉接口v1.0/yida/processes/instances获取供应商账号状态修改的相关数据,并进行初步加工。
接口调用配置
根据元数据配置,我们需要向钉钉接口发送一个POST请求。以下是请求的具体参数配置:
- api:
v1.0/yida/processes/instances - method:
POST - number:
title - id:
processInstanceId - pagination:
pageSize: 50
- beatFlat:
tableField_ktaw945v
- idCheck: true
请求参数详解
请求参数包括分页信息、应用信息、用户信息、表单信息以及查询条件等。以下是各个字段的详细说明:
-
分页参数
pageSize: 分页大小,设置为50。pageNumber: 分页页码,初始值为1。
-
应用信息
appType: 应用ID,值为APP_JL611JQ2HXF8T62QJWV5。systemToken: 应用秘钥,值为9I866N7106AT2IRP2KD7JBBECGH436XDNR3TK33。
-
用户信息
userId: 用户的userid,值为16000443318138909。
-
语言设置
language: 语言设置,默认值为中文(zh_CN)。
-
表单信息
formUuid: 表单ID,值为FORM-YZ9664D1RC62CIK3C2JDL6BZC3C0345CVV26L61。
-
查询条件
searchFieldJson: 包含多个子字段,用于指定查询条件:selectField_kt3rofbs: 申请类型,值为“供应商银行账户”。textField_kspditvc: 流水号。textField_kmvrqh6o: 申请人。
-
时间范围
createFromTimeGMT: 创建时间起始值,固定为2024-03-20 00:00:00。createToTimeGMT: 创建时间终止值,为当前时间。modifiedFromTimeGMT: 修改时间起始值。modifiedToTimeGMT: 修改时间终止值。
-
其他参数
taskId: 任务ID。instanceStatus: 实例状态,值为“COMPLETED”。approvedResult: 流程审批结果,值为“agree”。
数据请求与清洗
在成功调用接口并获取数据后,需要对返回的数据进行清洗和初步加工。以下是一些关键步骤:
-
数据解析 将返回的JSON数据解析成结构化的数据格式,例如DataFrame,以便后续处理。
-
字段筛选 根据业务需求筛选出必要的字段,例如供应商账号状态、申请人、流水号等。
-
数据转换 对部分字段进行必要的转换,例如日期格式转换、数值单位转换等。
-
去重处理 如果存在重复记录,根据唯一标识(如processInstanceId)进行去重处理。
示例代码
以下是一个示例代码片段,用于展示如何调用接口并处理返回的数据:
import requests
import pandas as pd
from datetime import datetime
# 定义请求URL和头部
url = "https://api.dingtalk.com/v1.0/yida/processes/instances"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_ACCESS_TOKEN"
}
# 定义请求体
payload = {
"pageSize": "50",
"pageNumber": "1",
"appType": "APP_JL611JQ2HXF8T62QJWV5",
"systemToken": "9I866N7106AT2IRP2KD7JBBECGH436XDNR3TK33",
"userId": "16000443318138909",
"language": "zh_CN",
"formUuid": "FORM-YZ9664D1RC62CIK3C2JDL6BZC3C0345CVV26L61",
"searchFieldJson": {
"selectField_kt3rofbs": "供应商银行账户"
},
"createFromTimeGMT": "2024-03-20 00:00:00",
"createToTimeGMT": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"instanceStatus": "COMPLETED",
"approvedResult": "agree"
}
# 发起POST请求
response = requests.post(url, headers=headers, json=payload)
data = response.json()
# 数据解析与清洗
df = pd.DataFrame(data['data'])
df_filtered = df[['processInstanceId', 'title', 'status', 'applicant']]
# 去重处理
df_cleaned = df_filtered.drop_duplicates(subset=['processInstanceId'])
print(df_cleaned)通过上述步骤,我们可以高效地从钉钉系统中获取所需的数据,并进行初步加工,为后续的数据转换与写入打下坚实基础。
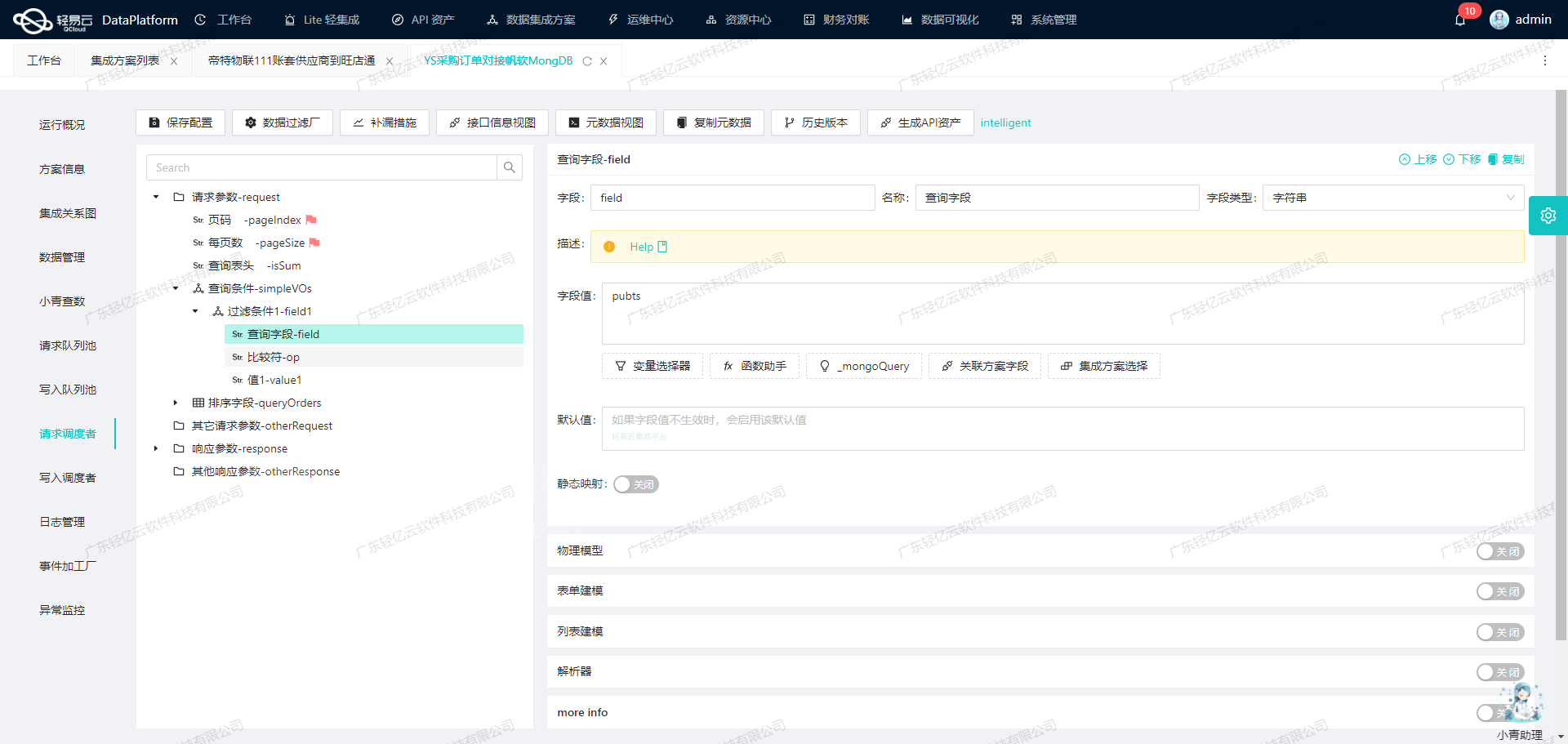
使用轻易云数据集成平台进行ETL转换并写入MySQL API接口
在数据集成生命周期的第二阶段,关键任务是将已经集成的源平台数据进行ETL(提取、转换、加载)转换,使其符合目标平台 MySQL API 接口所能接收的格式,并最终写入目标平台。本文将详细探讨如何利用元数据配置完成这一过程。
元数据配置解析
在本次技术案例中,我们需要将对账系统中的供应商账号状态修改后写入 MySQL 数据库。以下是元数据配置的详细解析:
{
"api": "execute",
"method": "POST",
"idCheck": true,
"request": [
{
"field": "main_params",
"label": "主参数",
"type": "object",
"children": [
{
"field": "account",
"label": "银行账号",
"type": "string",
"value": "{{tableField_ktaw945v_textField_ktaw945y}}"
},
{
"field": "status",
"label": "使用状态",
"type": "int"
}
]
}
],
"otherRequest": [
{
"field": "main_sql",
"label": "主语句",
"type": "string",
"value":
`UPDATE \`lhhy_srm\`.\`supplier_account\`
SET \`status\` = <{status: }>
WHERE \`account\` = <{account: }>;`
}
],
"buildModel": true
}ETL转换步骤
-
提取(Extract):
- 从对账系统中提取供应商账号及其状态信息。
- 在元数据配置中,
{{tableField_ktaw945v_textField_ktaw945y}}表示从源系统中提取的银行账号字段。
-
转换(Transform):
- 将提取的数据转换为 MySQL API 接口所需的格式。
- 在元数据配置中,定义了一个
main_params对象,其中包含两个字段:account和status。这两个字段将被映射到 SQL 更新语句中。
-
加载(Load):
- 将转换后的数据通过 MySQL API 接口写入目标数据库。
- 配置中的
main_sql字段定义了实际执行的 SQL 更新语句,将status值更新到指定的account。
系统接口与数据集成特性
-
API调用方式:
- 使用 POST 方法调用 MySQL API 接口,通过 HTTP 请求发送转换后的数据。
-
参数校验:
- 配置中的
idCheck: true表示在执行操作前会进行参数校验,确保必要字段如account和status的有效性。
- 配置中的
-
动态 SQL 构建:
- 利用模板语言
<{status: }>和<{account: }>动态构建 SQL 更新语句,以确保灵活性和可扩展性。
- 利用模板语言
实际应用案例
假设我们需要将某个供应商账号状态从“活跃”修改为“冻结”,具体操作如下:
-
提取数据:
{ "{{tableField_ktaw945v_textField_ktaw945y}}": "1234567890", "{{status}}": 0 } -
构建请求对象:
{ "main_params": { "account": "1234567890", "status": 0 } } -
生成 SQL 更新语句:
UPDATE `lhhy_srm`.`supplier_account` SET `status` = 0 WHERE `account` = '1234567890'; -
发送 POST 请求:
POST /execute HTTP/1.1 Host: target-mysql-api.com Content-Type: application/json { ... // 包含 main_params 和 main_sql 的完整 JSON 对象 ... }
通过上述步骤,我们成功地将对账系统中的供应商账号状态修改并写入到目标 MySQL 数据库。这一过程充分利用了轻易云数据集成平台提供的全生命周期管理和可视化操作界面,实现了高效、透明的数据处理和集成。