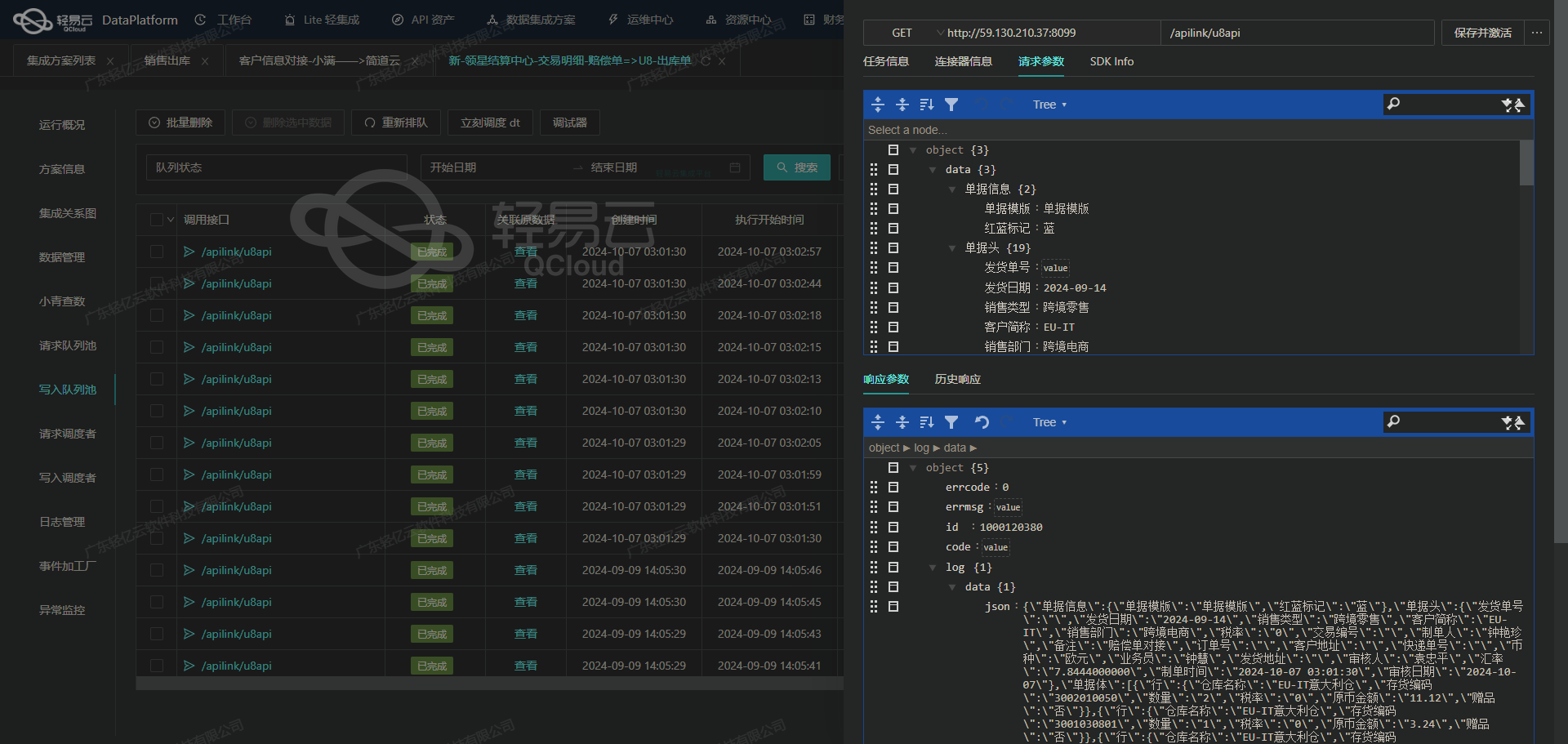
查询班牛退换原因-质量问题细分
在数据集成系统的实施过程中,针对不同业务场景和需求,我们常常需要处理复杂的数据对接任务。在本案例中,我们将探讨如何通过轻易云数据集成平台,将班牛系统中的退换货原因进行分类汇总,并细化到具体的“质量问题”类别。该方案旨在帮助企业快速抓取相关API接口数据,确保高效、可靠地完成大批量数据写入,同时实现对整个流程状态的实时监控。
为了保证这一目标,我们先从API接口的数据获取开始。在这个案例中,首先需要调用班牛提供的column.list API,以获取所需的退换货原因列表。同时,通过自定义的数据转换逻辑,使得这些信息能够适应我们具体的业务需求和数据结构。
确保集成过程无缝进行的一项关键技术是在处理中,大量数据快速写入至班牛系统。这不仅提高了整体处理效率,还避免了因大量请求带来的性能瓶颈。此外,为了应对可能出现的数据格式差异与分页限流问题,本方案采用了一系列定制化映射和异常检测机制,以确保每一条记录都能够精确、稳定地被处理并存储到指定位置。
值得特别关注的是,在整个任务执行过程中,集中监控和告警系统发挥着重要作用。它实时跟踪每个步骤的执行情况,一旦检测到任何异常情况,即刻触发相应的告警通知,并迅速采取重试措施,从而提升整体操作链路上的鲁棒性。
综上所述,通过合理配置API资产管理功能以及高吞吐量的数据写入能力,该解决方案极大程度上简化了查询及分析“质量问题”退换原因的信息整理工作,为企业决策层提供精准、高效的信息支持。
调用班牛接口column.list获取并加工数据的技术案例
在数据集成的生命周期中,调用源系统接口是至关重要的一步。本文将深入探讨如何使用轻易云数据集成平台调用班牛接口column.list,并对获取的数据进行加工处理。
接口调用配置
首先,我们需要配置调用班牛接口column.list的元数据。根据提供的元数据配置,我们可以看到以下关键参数:
- API:
column.list - Method:
GET - Request Parameters:
project_id: 固定值为25821
- Condition:
column_id: 值为37582
这些参数定义了我们需要从班牛系统中查询特定项目(ID为25821)下的某个列(ID为37582)的信息。
请求构建
根据元数据配置,我们需要构建一个HTTP GET请求。请求URL和参数如下:
GET /api/column.list?project_id=25821&column_id=37582 HTTP/1.1
Host: api.banniu.com在轻易云平台上,可以通过可视化界面配置这些请求参数,确保每个字段都准确无误。
数据清洗与转换
在获取到原始数据后,我们需要对其进行清洗和转换,以便后续处理和分析。假设返回的数据包含以下结构:
{
"data": [
{
"column_id": 37582,
"name": "退换原因",
"relation_options": [
{"id": 1, "name": "质量问题"},
{"id": 2, "name": "非质量问题"}
]
}
]
}我们需要提取并细分“质量问题”相关的数据。具体步骤如下:
- 解析JSON响应:将返回的JSON字符串解析为对象。
- 过滤数据:从
relation_options中筛选出“质量问题”相关的条目。 - 构建新结构:将筛选后的数据转换为所需格式。
以下是一个Python示例代码,用于实现上述步骤:
import requests
import json
# Step 1: 发起HTTP GET请求
url = 'https://api.banniu.com/api/column.list'
params = {'project_id': '25821', 'column_id': '37582'}
response = requests.get(url, params=params)
# Step 2: 解析JSON响应
data = response.json()
# Step 3: 提取并细分“质量问题”相关的数据
quality_issues = []
for option in data['data'][0]['relation_options']:
if option['name'] == '质量问题':
quality_issues.append(option)
# Step 4: 构建新结构
processed_data = {
'project_id': '25821',
'quality_issues': quality_issues
}
print(json.dumps(processed_data, indent=4, ensure_ascii=False))数据写入与存储
在完成数据清洗与转换后,下一步是将处理后的数据写入目标系统或存储介质。这一步通常涉及到另一个API调用或数据库操作。在轻易云平台上,可以通过配置相应的写入节点来实现这一过程。
例如,如果目标系统是一个数据库,可以配置数据库连接信息,并使用SQL语句插入处理后的数据。如果目标系统是另一个API,则可以配置相应的API调用参数和请求体。
实时监控与调试
为了确保整个过程顺利进行,轻易云平台提供了实时监控和调试功能。通过这些功能,可以查看每个环节的数据流动和处理状态,及时发现并解决潜在的问题。
总之,通过合理配置元数据和利用轻易云平台强大的集成功能,我们可以高效地调用班牛接口column.list,并对获取的数据进行精细化处理,为后续的数据分析和业务决策提供可靠支持。

使用轻易云数据集成平台实现班牛API接口的ETL转换
在数据集成生命周期的第二阶段,我们需要将已经集成的源平台数据进行ETL(提取、转换、加载)处理,转为目标平台班牛API接口所能够接收的格式,并最终写入目标平台。本文将详细探讨如何通过轻易云数据集成平台完成这一过程。
元数据配置解析
在本次任务中,我们的目标是查询班牛退换原因中的质量问题细分,并将结果写入班牛平台。根据提供的元数据配置:
{
"api": "workflow.task.create",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true
}我们可以了解到以下关键信息:
api字段指明了我们要调用的班牛API接口为workflow.task.create。effect字段表明此次操作的效果是执行(EXECUTE)。method字段表示我们需要使用HTTP POST方法来提交请求。idCheck字段为true,意味着我们需要对ID进行校验。
数据提取与清洗
首先,我们需要从源平台提取相关数据。假设源平台的数据包含多个退换原因,其中包括质量问题。我们需要对这些数据进行清洗,确保只保留与质量问题相关的信息。
# 示例代码:提取和清洗数据
def extract_and_clean_data(source_data):
# 提取所有退换原因
all_reasons = source_data.get("return_reasons", [])
# 筛选出质量问题相关的数据
quality_issues = [reason for reason in all_reasons if reason.get("type") == "quality"]
return quality_issues数据转换
接下来,我们需要将清洗后的数据转换为班牛API接口所需的格式。根据元数据配置,班牛API接口workflow.task.create可能需要特定的数据结构,例如任务名称、描述、优先级等。
# 示例代码:转换数据格式
def transform_data(quality_issues):
transformed_data = []
for issue in quality_issues:
task_data = {
"task_name": issue.get("issue_name"),
"description": issue.get("issue_description"),
"priority": issue.get("priority_level", "medium")
}
transformed_data.append(task_data)
return transformed_data数据写入
最后,我们使用HTTP POST方法将转换后的数据写入到班牛平台。为了确保请求成功,我们还需要进行ID校验,这里假设每个任务都有一个唯一的ID。
import requests
# 示例代码:写入数据到班牛平台
def write_to_target_platform(transformed_data):
url = "https://api.banniu.com/workflow/task/create"
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer YOUR_ACCESS_TOKEN'
}
for task in transformed_data:
response = requests.post(url, json=task, headers=headers)
if response.status_code == 200:
print(f"Task {task['task_name']} created successfully.")
else:
print(f"Failed to create task {task['task_name']}. Response: {response.text}")
# 主函数调用示例
if __name__ == "__main__":
source_data = get_source_data() # 假设此函数获取源平台的数据
quality_issues = extract_and_clean_data(source_data)
transformed_data = transform_data(quality_issues)
write_to_target_platform(transformed_data)通过上述步骤,我们实现了从源平台到班牛API接口的数据ETL转换和写入。在实际应用中,可以根据具体需求对代码进行优化和扩展,以适应不同的数据结构和业务逻辑。