聚水潭数据集成到MySQL:高效解决方案分享
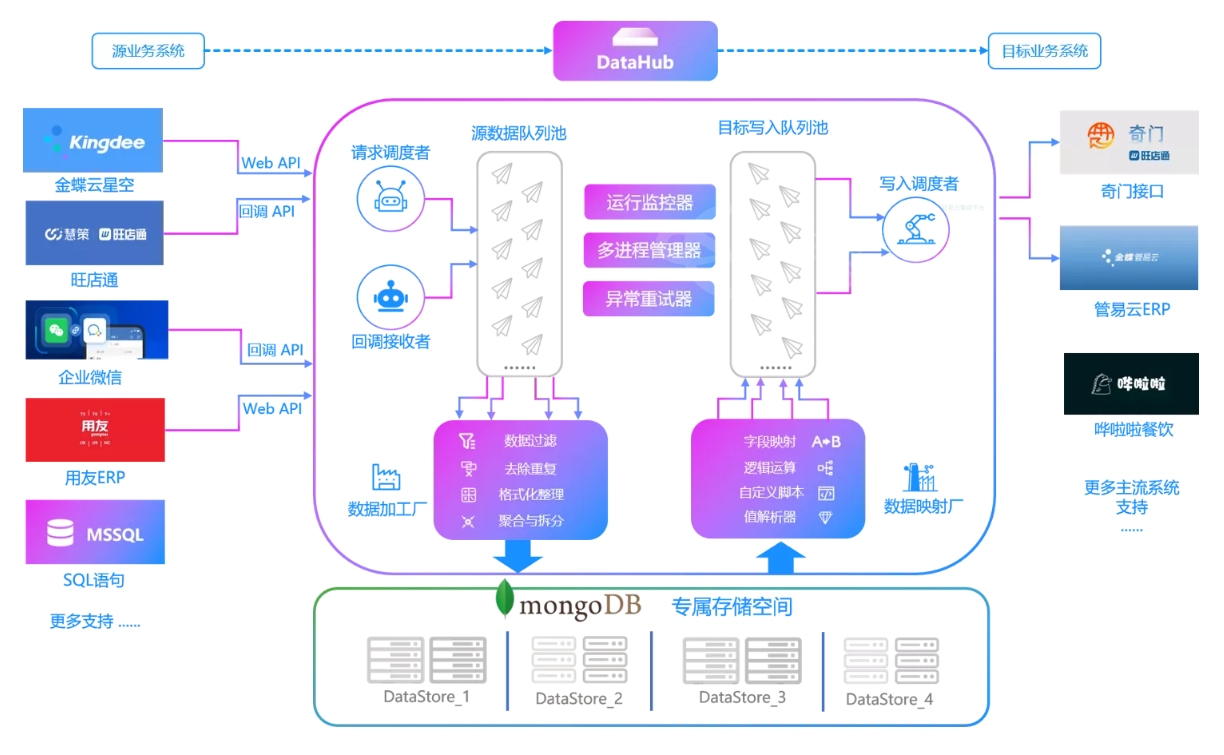
在系统集成过程中,如何确保不同平台之间的数据无缝对接一直是个不小的挑战。尤其对于需要处理大量频繁交易数据的企业来说,实现高吞吐量、低延迟且可靠的数据传输更为关键。在此次案例中,我们将通过轻易云数据集成平台,对聚水潭中的其他出入库单据进行抓取,并实时同步至MySQL数据库。这一过程不仅需要考虑接口调用、批量写入以及分页限流等技术细节,还需要建立起完善的数据质量监控和异常处理机制。
首先,通过调用聚水潭提供的API/open/other/inout/query来定时获取最新的其他出入库单。据悉,该API支持基于时间窗口和状态过滤条件的查询方式,保证了我们能够持续地、高效地抓取目标数据。而这些数据则会被转换并批量写入到MySQL中,以做到快速响应业务需求。
为了确保这一过程中的每一步都能顺利进行,我们使用轻易云的一些重要特性。例如,它提供了一个可视化的数据流设计工具,使得整个集成流程直观清晰。同时,集中式监控与告警系统使我们可以实时跟踪任务状态,一旦发生异常立刻采取措施。此外,高吞吐量的数据写入能力也让大规模数据传输变得更加容易,从而提高整体效率。
在具体实现上需关注以下几个方面:
-
接口调用与分页限流:
- 如何正确使用聚水潭接口
/open/other/inout/query并处理其分页返回。 - 设定合理的请求速率以避免触发限流策略,同时保证不会漏掉任何记录。
- 如何正确使用聚水潭接口
-
数据格式转换:
- 自定义转化逻辑,将聚水潭返回的数据结构映射至适配MySQL表结构。
-
批量写入优化:
- 利用轻易云的平台优势,通过 MySQL API
batchexecute, 实现高效、大批量的数据插入操作。
- 利用轻易云的平台优势,通过 MySQL API
-
异常处理机制:
- 在多个环节配置重试逻辑及错误日志,确保任何因网络或临时故障导致的问题都能及时发现并恢复。
-
实时监控与日志记录:
- 系统内置功能帮助开发团队从全局视角掌握每次任务执行情况,提高对问题定位及解决速度。
通过上述技术方法,不仅有效提高了跨系统间的大规模数据传递效率,还显著增强了整个工作流程的透明度和可靠性。
调用聚水潭接口获取并加工数据的技术实现
在数据集成的生命周期中,调用源系统接口是至关重要的一步。本文将深入探讨如何通过轻易云数据集成平台调用聚水潭接口 /open/other/inout/query 获取并加工数据。
接口配置与调用
首先,我们需要配置元数据以便正确调用聚水潭接口。以下是具体的元数据配置:
{
"api": "/open/other/inout/query",
"effect": "QUERY",
"method": "POST",
"number": "io_id",
"id": "io_id",
"idCheck": true,
"request": [
{"field": "modified_begin", "label": "修改起始时间", "type": "datetime", "value": "{{LAST_SYNC_TIME|datetime}}"},
{"field": "modified_end", "label": "修改结束时间", "type": "datetime", "value": "{{CURRENT_TIME|datetime}}"},
{"field": "status", "label": "单据状态", "type": "string", "value":"Confirmed"},
{"field": "date_type", "label":"时间类型","type":"string","value":"2"},
{"field":"page_index","label":"第几页","type":"string","value":"1"},
{"field":"page_size","label":"每页多少条","type":"string","value":"30"}
],
"autoFillResponse": true,
"condition_bk":[
[{"field":"type","logic":"in","value":"其他退货,其他入仓"}]
],
"beatFlat":["items"]
}请求参数解析
modified_begin和modified_end:用于指定查询的时间范围,分别代表修改起始时间和结束时间。使用模板变量{{LAST_SYNC_TIME|datetime}}和{{CURRENT_TIME|datetime}}动态填充。status:固定值为"Confirmed",表示只查询已确认的单据。date_type:固定值为"2",表示按修改时间查询。page_index和page_size:用于分页查询,分别表示当前页码和每页记录数。
数据请求与清洗
在发送请求后,系统会返回包含多个出入库单据的数据集。由于配置了 autoFillResponse: true,平台会自动处理响应数据,并根据条件过滤出所需的记录。
例如,条件过滤部分:
"condition_bk":[
[{"field":"type","logic":"in","value":"其他退货,其他入仓"}]
]此配置确保只保留类型为“其他退货”和“其他入仓”的单据。
数据转换与写入
获取并清洗后的数据需要进行转换,以符合目标系统的要求。在此过程中,可以利用轻易云平台提供的可视化工具进行字段映射和格式转换。例如,将聚水潭返回的数据字段映射到BI崛起系统所需的字段:
{
// 聚水潭字段 -> BI崛起字段映射示例
// 聚水潭返回的字段名: BI崛起目标字段名
// 示例:
// io_id: transaction_id,
// modified_time: update_time,
}通过这种方式,可以确保数据在不同系统间无缝对接。
实时监控与调试
在整个过程中,轻易云平台提供了实时监控功能,可以随时查看数据流动和处理状态。如果出现问题,可以利用平台提供的日志和调试工具进行排查和修正。
总结来说,通过合理配置元数据并利用轻易云平台强大的集成功能,我们可以高效地调用聚水潭接口 /open/other/inout/query 获取并加工所需的数据,为后续的数据处理和分析奠定坚实基础。
使用轻易云数据集成平台进行ETL转换并写入MySQL API接口的技术案例
在数据集成过程中,将源平台的数据转换为目标平台所能接受的格式是至关重要的一步。本文将详细探讨如何使用轻易云数据集成平台将聚水潭的出入库单数据转换并写入BI崛起的MySQL数据库。
元数据配置解析
在本次集成任务中,我们需要将聚水潭的出入库单数据通过ETL流程转换为BI崛起能够接收的格式,并最终写入MySQL数据库。以下是具体的元数据配置:
{
"api": "batchexecute",
"effect": "EXECUTE",
"method": "SQL",
"number": "id",
"id": "id",
"name": "id",
"idCheck": true,
"request": [
{"field":"id","label":"主键","type":"string","value":"{io_id}-{items_ioi_id}"},
{"field":"io_id","label":"出仓单号","type":"string","value":"{io_id}"},
{"field":"io_date","label":"单据日期","type":"string","value":"{io_date}"},
{"field":"status","label":"单据状态","type":"string","value":"{status}"},
{"field":"so_id","label":"线上单号","type":"string","value":"{so_id}"},
{"field":"type","label":"单据类型","type":"string","value":"{type}"},
{"field":"f_status","label":"财务状态","type":"string","value":"{f_status}"},
{"field":"warehouse","label":"仓库名称","type":"string","value":"{warehouse}"},
{"field":"receiver_name","label":"收货人","type":"string","value":"{receiver_name}"},
{"field":"receiver_mobile","label":"收货人手机","type":"string","value":"{receiver_mobile}"},
{"field":"receiver_state","label":"收货人省","type":"string","value":"{receiver_state}"},
{"field":"receiver_city","label":"收货人市","type":""},
...
],
"otherRequest": [
{
"field": "main_sql",
"label": "主语句",
"type": "string",
"describe": "SQL首次执行的语句,将会返回:lastInsertId",
"value":
`REPLACE INTO other_inout_query(
id, io_id, io_date, status, so_id, type, f_status, warehouse, receiver_name,
receiver_mobile, receiver_state, receiver_city, receiver_district, receiver_address,
wh_id, remark, modified, created, labels, wms_co_id, creator_name, wave_id,
drop_co_name, inout_user, l_id, lc_id, logistics_company, lock_wh_id,
lock_wh_name, items_ioi_id, items_sku_id, items_name, items_unit,
items_properties_value, items_qty, items_cost_price,
items_cost_amount, items_i_id,
items_remark,
items_io_id,
items_sale_price,
items_sale_amount,
items_batch_id,
items_product_date,
items_supplier_id,
items_expiration_date,
sns_sku_id,
sns_sn
) VALUES`
},
{
"field": "limit",
"label": "limit",
"type": "string",
"value": "1000"
}
]
}数据请求与清洗
在ETL流程中,首先需要从源系统获取原始数据,并对其进行清洗和标准化处理。元数据配置中的request字段定义了需要提取的数据字段及其对应关系。例如:
{"field": "id", "label": "主键", ...}表示将io_id和items_ioi_id拼接作为主键。{"field": "io_date", ...}表示提取出仓单的日期。
这些字段通过特定的映射关系,从源系统中提取并进行初步处理。
数据转换与写入
在数据清洗完成后,下一步是将这些清洗后的数据转换为目标系统所能接受的格式,并通过API接口写入到目标系统。在本案例中,目标系统为MySQL数据库。
元数据配置中的otherRequest字段定义了主要的SQL语句和其他请求参数:
main_sql字段定义了插入操作所需执行的SQL语句。这里使用了REPLACE INTO来确保如果记录已经存在则更新,否则插入新记录。limit字段设置了每次批量处理的数据量上限,这里设定为1000条。
具体执行时,系统会根据配置生成相应的SQL语句并执行。例如:
REPLACE INTO other_inout_query(
id, io_id, io_date,...)
VALUES
('1-101', '1', '2023-01-01',...),
('2-102', '2', '2023-01-02',...),
...通过这种方式,可以确保源系统的数据能够无缝地转换并写入到目标MySQL数据库中,实现不同系统之间的数据集成。
技术要点总结
- 元数据配置:通过详细定义每个字段及其映射关系,确保从源系统到目标系统的数据转换准确无误。
- 批量处理:利用批量处理机制提高效率,同时设置合理的批量大小(如1000条)以平衡性能和资源消耗。
- SQL语句生成:根据配置自动生成适当的SQL语句,通过API接口执行,确保数据准确写入目标数据库。
以上内容详细阐述了如何利用轻易云数据集成平台实现ETL转换,并最终将数据写入到MySQL API接口。这种方法不仅提高了业务透明度和效率,还确保了不同系统间的数据一致性和完整性。
