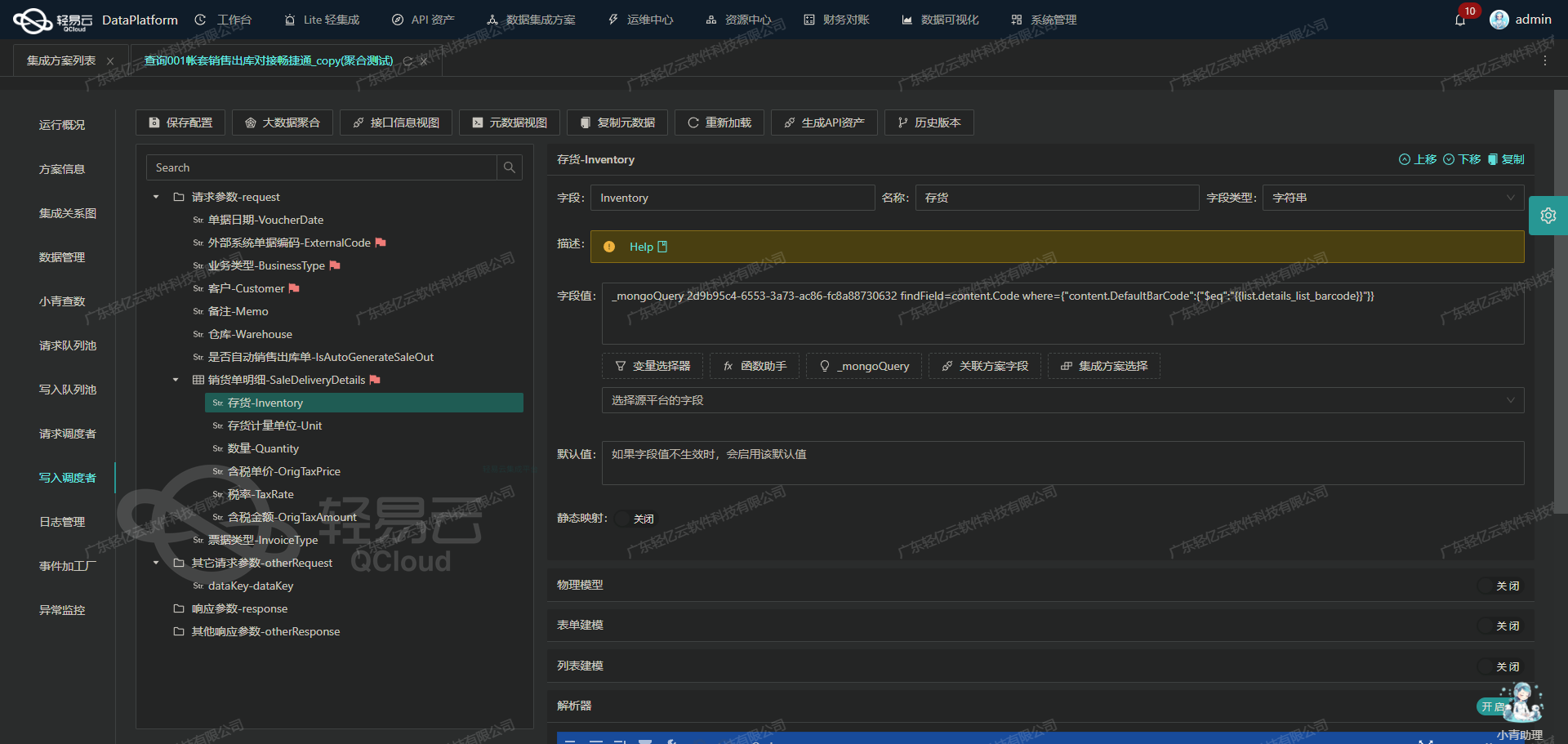
小满-宜搭-小满用户名查询宜搭用户名联查:钉钉数据集成到轻易云平台案例分享
在企业日常运营中,如何高效安全地实现跨系统的数据对接成为了关键挑战之一。本次案例将详细阐述如何通过轻易云数据集成平台,将钉钉的数据准确无误地集成到指定业务应用中。具体方案名为“小满-宜搭-小满用户名查询宜搭用户名联查”。
首先,我们需要利用钉钉提供的API接口来获取所需数据。在此案例中,指定的接口是v1.0/yida/forms/instances/ids/{appType}/{formUuid}。为了确保大规模数据抓取的稳定性和可靠性,我们会使用定时任务来抓取这些接口数据,并处理分页与限流问题以避免超时现象。
接收到来自钉钉的数据后,下一个重要步骤就是快速且批量地写入到轻易云集成平台。这一过程中,为了能有效应对不同系统间的数据格式差异,通过自定义映射规则进行转换显得尤为重要。此外,为保证操作过程中的容错率,将实现全面的实时监控与日志记录机制,以便及时捕捉并解决任何潜在的问题。
异常处理和错误重试机制也是此流程管理的重要部分。当出现网络波动或其他不可预见的问题导致请求失败时,该机制将自动尝试重新执行未完成的操作,保障整个流程具有高度鲁棒性和连续性。
结合实际需求,本方案不仅能够确保从源头(如钉钉)获取完整而一致的数据,还能通过灵活且高效的平台功能,实现对目标系统的一键无缝写入。同时,它具备出色的透明度和可追溯性,使每一步骤都清晰可见,从而提升整体运营效率及管理水平。这些技术细节将在以下章节进一步展开分析。
调用钉钉接口获取并加工数据
在轻易云数据集成平台的生命周期中,调用源系统接口是数据处理的第一步。本文将详细探讨如何通过调用钉钉接口v1.0/yida/forms/instances/ids/{appType}/{formUuid}获取并加工数据,以实现小满-宜搭-小满用户名查询宜搭用户名联查的集成方案。
接口调用与元数据配置
首先,我们需要理解和配置元数据,以便正确调用钉钉接口。以下是关键的元数据配置:
{
"api": "v1.0/yida/forms/instances/ids/{appType}/{formUuid}",
"method": "POST",
"pagination": {
"pageSize": 100
},
"condition": [
[
{
"field": "extend.approvedResult",
"logic": "eq",
"value": "agree"
}
]
],
"request": [
{
"field": "appType",
"label": "应用ID",
"type": "string",
"describe": "示例:APP_PBKT0MFBEBTDO8T7SLVP",
"value": "APP_E4D9OR2HF7QLY167G75K"
},
{
"field": "systemToken",
"label": "应用秘钥",
"type": "string",
"value": "CH766981N8RI4YCK9QDSUAGJLEPA2BCS0OWSLR"
},
{
"field": "userId",
"label": "管理员用户钉钉ID",
"type": "string",
"describe": "钉钉的userId",
"value": "481569556726068568"
},
{
...
}
],
...
}请求参数详解
- appType: 应用ID,用于标识具体的应用实例。
- systemToken: 应用秘钥,用于验证请求合法性。
- userId: 管理员用户的钉钉ID,确保有权限访问所需的数据。
- language: 请求语言,设置为
zh_CN表示中文。 - formUuid: 表单ID,用于指定要查询的表单实例。
- instanceStatus: 实例状态,设置为
COMPLETED表示只查询已完成的实例。 - currentPage: 当前页码,通过分页机制获取大批量数据。
- pageSize: 每页记录数,默认设置为100条。
- originatorId: 数据提交人工号,可选参数,用于进一步过滤数据。
- createFrom/createTo: 创建时间范围,用于限定查询的数据时间段。
- modifiedFrom/modifiedTo: 修改时间范围,通常用于增量同步。
条件过滤与分页机制
在实际操作中,我们通常需要对返回的数据进行条件过滤和分页处理。上述配置中的condition字段定义了一个简单的条件过滤:
"condition":[[{"field":"extend.approvedResult","logic":"eq","value":"agree"}]]这表示只查询审批结果为“同意”的表单实例。分页机制则通过currentPage和pageSize参数实现,每次请求返回最多100条记录。
数据请求与清洗
在获取到原始数据后,需要对其进行清洗和转换,以便后续处理。例如,可以使用以下伪代码进行初步清洗:
def clean_data(raw_data):
cleaned_data = []
for record in raw_data:
if record['status'] == 'COMPLETED':
cleaned_record = {
'user_id': record['originatorId'],
'approved_result': record['extend']['approvedResult'],
'created_time': record['createdTime']
}
cleaned_data.append(cleaned_record)
return cleaned_data此函数过滤出状态为“COMPLETED”的记录,并提取所需字段。
数据转换与写入
清洗后的数据需要进一步转换,并写入目标系统。例如,可以将清洗后的数据转换为目标系统所需的格式,并通过API或数据库连接写入:
def transform_and_write(cleaned_data, target_system_api):
transformed_data = []
for record in cleaned_data:
transformed_record = {
'username': get_username(record['user_id']),
'approval_status': record['approved_result'],
'submission_date': record['created_time']
}
transformed_data.append(transformed_record)
response = requests.post(target_system_api, json=transformed_data)
return response.status_code此函数将清洗后的数据转换为目标系统格式,并通过POST请求写入目标系统。
实时监控与错误处理
在整个过程中,实时监控和错误处理至关重要。可以通过日志记录和异常捕获机制确保每个步骤都能顺利执行,并及时发现和解决问题:
try:
raw_data = fetch_raw_data(api_endpoint, params)
cleaned_data = clean_data(raw_data)
status_code = transform_and_write(cleaned_data, target_system_api)
if status_code != 200:
log_error("Data write failed with status code:", status_code)
except Exception as e:
log_error("An error occurred:", str(e))以上代码展示了一个完整的数据请求、清洗、转换和写入流程,并包含基本的错误处理逻辑。
通过上述步骤,我们可以高效地调用钉钉接口获取并加工数据,为后续的数据集成奠定坚实基础。

小满-宜搭-小满用户名查询宜搭用户名联查:ETL转换与写入
在轻易云数据集成平台中,将源平台的数据进行ETL转换并写入目标平台是数据处理生命周期的关键步骤之一。本文将深入探讨如何通过API接口将已经集成的源平台数据进行转换,最终写入目标平台。
数据请求与清洗
首先,我们从源平台(如小满)获取原始数据。这一步骤通常涉及到调用源平台的API接口,获取所需的用户数据。假设我们已经完成了这一步,并且得到了包含用户信息的数据集。
数据转换与写入
接下来,我们需要将这些原始数据进行转换,以符合目标平台(如轻易云集成平台API接口)所能接收的格式。这里,我们将使用元数据配置来指导这一过程。
元数据配置如下:
{
"api": "写入空操作",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true
}这段配置表明,我们需要通过POST方法调用目标API接口,并且在执行操作前需要进行ID检查。
-
数据转换:
- 字段映射:首先,需要将源平台的数据字段映射到目标平台所需的字段。例如,源平台中的用户名字段可能是
username,而目标平台需要的是user_name。 - 格式调整:确保数据格式符合目标API要求。例如,日期格式、数值类型等可能需要进行相应的转换。
- ID检查:根据配置中的
idCheck参数,在写入之前需要检查记录是否存在。如果存在,则更新;如果不存在,则插入新记录。
- 字段映射:首先,需要将源平台的数据字段映射到目标平台所需的字段。例如,源平台中的用户名字段可能是
-
构建请求体:
- 根据上述转换结果,构建符合目标API接口要求的请求体。例如:
{ "user_name": "example_user", "email": "example@example.com" }
- 根据上述转换结果,构建符合目标API接口要求的请求体。例如:
-
调用API接口:
-
使用HTTP POST方法,将构建好的请求体发送到目标API接口。具体代码示例如下:
import requests url = "https://api.targetplatform.com/execute" headers = { 'Content-Type': 'application/json' } payload = { "user_name": "example_user", "email": "example@example.com" } response = requests.post(url, json=payload, headers=headers) if response.status_code == 200: print("Data written successfully.") else: print(f"Failed to write data: {response.text}")
-
-
处理响应:
- 检查API响应状态码和返回内容,以确认操作是否成功。如果失败,需要根据返回的信息进行错误处理和重试机制。
实例应用
假设我们从小满获取了以下用户数据:
[
{"username": "john_doe", "email": "john@example.com"},
{"username": "jane_doe", "email": "jane@example.com"}
]我们需要将这些数据转换并写入轻易云集成平台。具体步骤如下:
-
字段映射和格式调整:
[ {"user_name": "john_doe", "email": "john@example.com"}, {"user_name": "jane_doe", "email": "jane@example.com"} ] -
构建请求体并调用API接口:
import requests url = "https://api.targetplatform.com/execute" headers = { 'Content-Type': 'application/json' } data = [ {"user_name": "john_doe", "email": "john@example.com"}, {"user_name": "jane_doe", "email": "jane@example.com"} ] for user in data: response = requests.post(url, json=user, headers=headers) if response.status_code == 200: print(f"Data for {user['user_name']} written successfully.") else: print(f"Failed to write data for {user['user_name']}: {response.text}")
通过上述步骤,我们成功地将小满用户数据转换并写入了轻易云集成平台。这一过程不仅确保了数据的一致性和完整性,还极大提升了系统间的数据交互效率。